 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Deep Learning based RMT Data Inversion using Gaussian Random Field
Oct 22, 2024Deep learning (DL) methods have emerged as a powerful tool for the inversion of geophysical data. When applied to field data, these models often struggle without additional fine-tuning of the network. This is because they are built on the assumption that the statistical patterns in the training and test datasets are the same. To address this, we propose a DL-based inversion scheme for Radio Magnetotelluric data where the subsurface resistivity models are generated using Gaussian Random Fields (GRF). The network's generalization ability was tested with an out-of-distribution (OOD) dataset comprising a homogeneous background and various rectangular-shaped anomalous bodies. After end-to-end training with the GRF dataset, the pre-trained network successfully identified anomalies in the OOD dataset. Synthetic experiments confirmed that the GRF dataset enhances generalization compared to a homogeneous background OOD dataset. The network accurately recovered structures in a checkerboard resistivity model, and demonstrated robustness to noise, outperforming traditional gradient-based methods. Finally, the developed scheme is tested using exemplary field data from a waste site near Roorkee, India. The proposed scheme enhances generalization in a data-driven supervised learning framework, suggesting a promising direction for OOD generalization in DL methods.
Harnessing Business and Media Insights with Large Language Models
Jun 02, 2024

This paper introduces Fortune Analytics Language Model (FALM). FALM empowers users with direct access to comprehensive business analysis, including market trends, company performance metrics, and expert insights. Unlike generic LLMs, FALM leverages a curated knowledge base built from professional journalism, enabling it to deliver precise and in-depth answers to intricate business questions. Users can further leverage natural language queries to directly visualize financial data, generating insightful charts and graphs to understand trends across diverse business sectors clearly. FALM fosters user trust and ensures output accuracy through three novel methods: 1) Time-aware reasoning guarantees accurate event registration and prioritizes recent updates. 2) Thematic trend analysis explicitly examines topic evolution over time, providing insights into emerging business landscapes. 3) Content referencing and task decomposition enhance answer fidelity and data visualization accuracy. We conduct both automated and human evaluations, demonstrating FALM's significant performance improvements over baseline methods while prioritizing responsible AI practices. These benchmarks establish FALM as a cutting-edge LLM in the business and media domains, with exceptional accuracy and trustworthiness.
Jointformer: Single-Frame Lifting Transformer with Error Prediction and Refinement for 3D Human Pose Estimation
Aug 07, 2022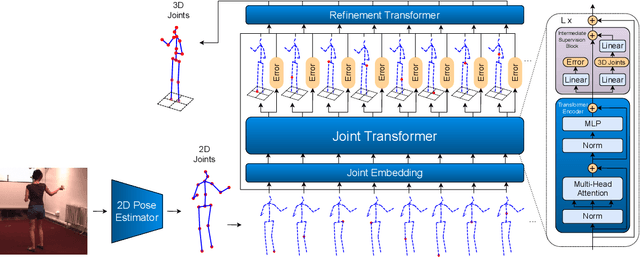
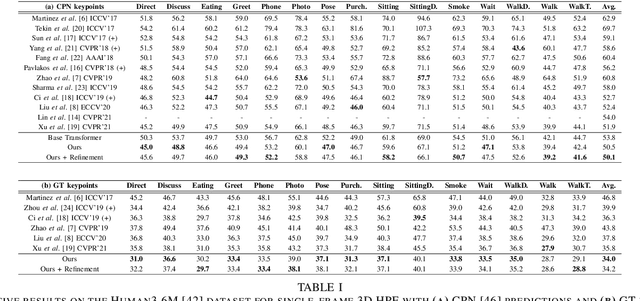
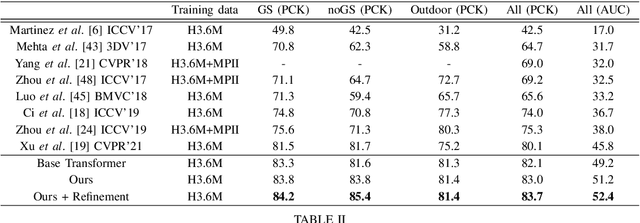
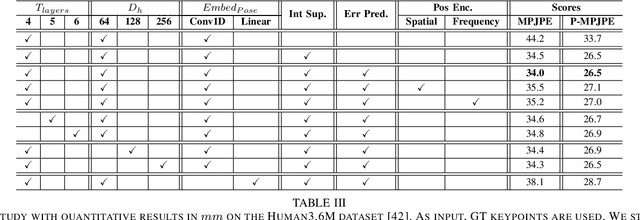
Monocular 3D human pose estimation technologies have the potential to greatly increase the availability of human movement data. The best-performing models for single-image 2D-3D lifting use graph convolutional networks (GCNs) that typically require some manual input to define the relationships between different body joints. We propose a novel transformer-based approach that uses the more generalised self-attention mechanism to learn these relationships within a sequence of tokens representing joints. We find that the use of intermediate supervision, as well as residual connections between the stacked encoders benefits performance. We also suggest that using error prediction as part of a multi-task learning framework improves performance by allowing the network to compensate for its confidence level. We perform extensive ablation studies to show that each of our contributions increases performance. Furthermore, we show that our approach outperforms the recent state of the art for single-frame 3D human pose estimation by a large margin. Our code and trained models are made publicly available on Github.
Image Aesthetics Assessment Using Graph Attention Network
Jun 28, 2022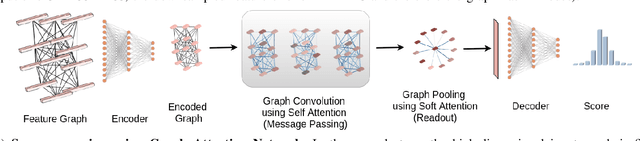
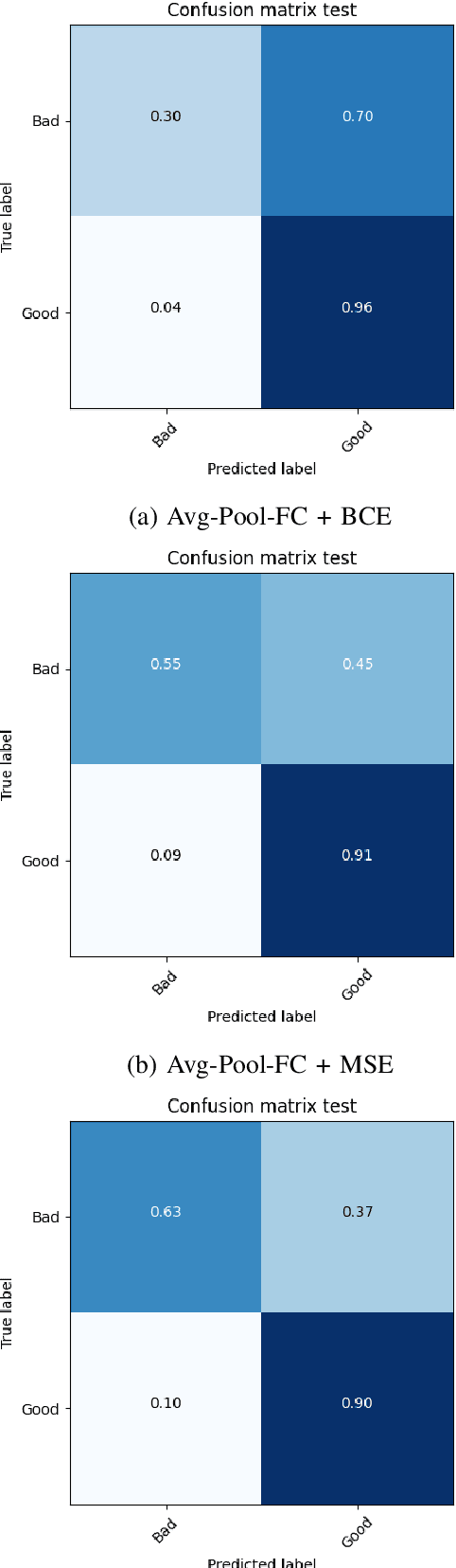
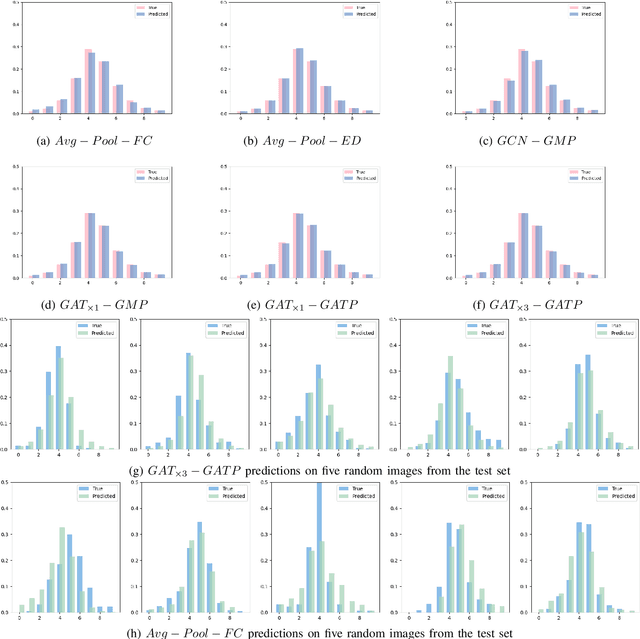

Aspect ratio and spatial layout are two of the principal factors determining the aesthetic value of a photograph. But, incorporating these into the traditional convolution-based frameworks for the task of image aesthetics assessment is problematic. The aspect ratio of the photographs gets distorted while they are resized/cropped to a fixed dimension to facilitate training batch sampling. On the other hand, the convolutional filters process information locally and are limited in their ability to model the global spatial layout of a photograph. In this work, we present a two-stage framework based on graph neural networks and address both these problems jointly. First, we propose a feature-graph representation in which the input image is modelled as a graph, maintaining its original aspect ratio and resolution. Second, we propose a graph neural network architecture that takes this feature-graph and captures the semantic relationship between the different regions of the input image using visual attention. Our experiments show that the proposed framework advances the state-of-the-art results in aesthetic score regression on the Aesthetic Visual Analysis (AVA) benchmark.
Frequency Domain Loss Function for Deep Exposure Correction of Dark Images
May 21, 2021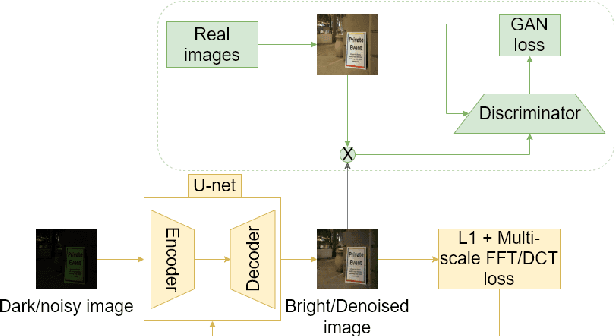
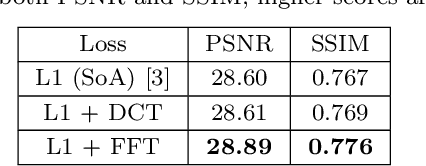
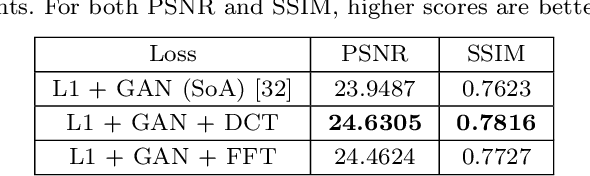

We address the problem of exposure correction of dark, blurry and noisy images captured in low-light conditions in the wild. Classical image-denoising filters work well in the frequency space but are constrained by several factors such as the correct choice of thresholds, frequency estimates etc. On the other hand, traditional deep networks are trained end-to-end in the RGB space by formulating this task as an image-translation problem. However, that is done without any explicit constraints on the inherent noise of the dark images and thus produce noisy and blurry outputs. To this end we propose a DCT/FFT based multi-scale loss function, which when combined with traditional losses, trains a network to translate the important features for visually pleasing output. Our loss function is end-to-end differentiable, scale-agnostic, and generic; i.e., it can be applied to both RAW and JPEG images in most existing frameworks without additional overhead. Using this loss function, we report significant improvements over the state-of-the-art using quantitative metrics and subjective tests.
STaDA: Style Transfer as Data Augmentation
Sep 03, 2019
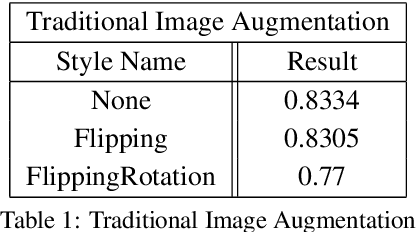

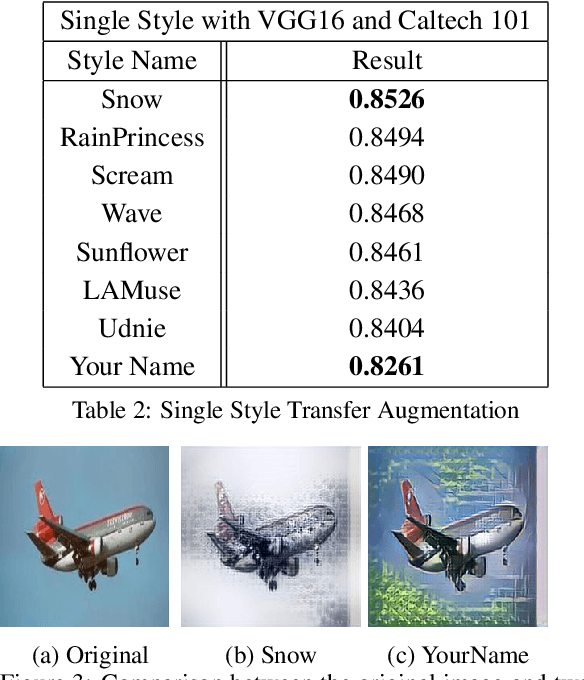
The success of training deep Convolutional Neural Networks (CNNs) heavily depends on a significant amount of labelled data. Recent research has found that neural style transfer algorithms can apply the artistic style of one image to another image without changing the latter's high-level semantic content, which makes it feasible to employ neural style transfer as a data augmentation method to add more variation to the training dataset. The contribution of this paper is a thorough evaluation of the effectiveness of the neural style transfer as a data augmentation method for image classification tasks. We explore the state-of-the-art neural style transfer algorithms and apply them as a data augmentation method on Caltech 101 and Caltech 256 dataset, where we found around 2% improvement from 83% to 85% of the image classification accuracy with VGG16, compared with traditional data augmentation strategies. We also combine this new method with conventional data augmentation approaches to further improve the performance of image classification. This work shows the potential of neural style transfer in computer vision field, such as helping us to reduce the difficulty of collecting sufficient labelled data and improve the performance of generic image-based deep learning algorithms.
A Geometry-Sensitive Approach for Photographic Style Classification
Sep 03, 2019

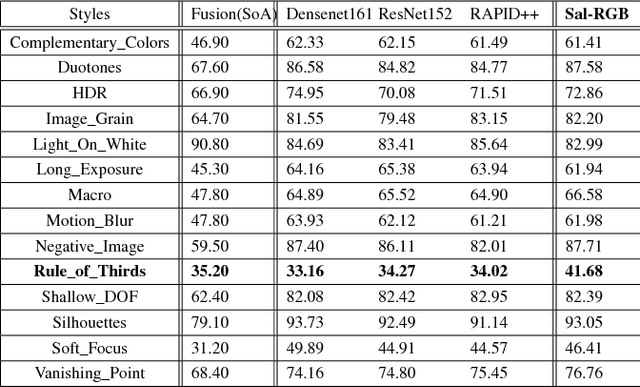

Photographs are characterized by different compositional attributes like the Rule of Thirds, depth of field, vanishing-lines etc. The presence or absence of one or more of these attributes contributes to the overall artistic value of an image. In this work, we analyze the ability of deep learning based methods to learn such photographic style attributes. We observe that although a standard CNN learns the texture and appearance based features reasonably well, its understanding of global and geometric features is limited by two factors. First, the data-augmentation strategies (cropping, warping, etc.) distort the composition of a photograph and affect the performance. Secondly, the CNN features, in principle, are translation-invariant and appearance-dependent. But some geometric properties important for aesthetics, e.g. the Rule of Thirds (RoT), are position-dependent and appearance-invariant. Therefore, we propose a novel input representation which is geometry-sensitive, position-cognizant and appearance-invariant. We further introduce a two-column CNN architecture that performs better than the state-of-the-art (SoA) in photographic style classification. From our results, we observe that the proposed network learns both the geometric and appearance-based attributes better than the SoA.
* Irish Machine Vision and Image Processing Conference, Belfast, 2018
Aesthetic Image Captioning From Weakly-Labelled Photographs
Aug 29, 2019


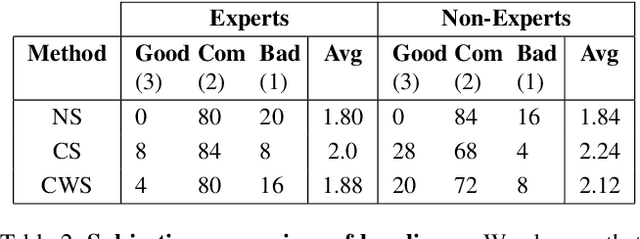
Aesthetic image captioning (AIC) refers to the multi-modal task of generating critical textual feedbacks for photographs. While in natural image captioning (NIC), deep models are trained in an end-to-end manner using large curated datasets such as MS-COCO, no such large-scale, clean dataset exists for AIC. Towards this goal, we propose an automatic cleaning strategy to create a benchmarking AIC dataset, by exploiting the images and noisy comments easily available from photography websites. We propose a probabilistic caption-filtering method for cleaning the noisy web-data, and compile a large-scale, clean dataset "AVA-Captions", (230, 000 images with 5 captions per image). Additionally, by exploiting the latent associations between aesthetic attributes, we propose a strategy for training the convolutional neural network (CNN) based visual feature extractor, the first component of the AIC framework. The strategy is weakly supervised and can be effectively used to learn rich aesthetic representations, without requiring expensive ground-truth annotations. We finally show-case a thorough analysis of the proposed contributions using automatic metrics and subjective evaluations.