 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJointformer: Single-Frame Lifting Transformer with Error Prediction and Refinement for 3D Human Pose Estimation
Aug 07, 2022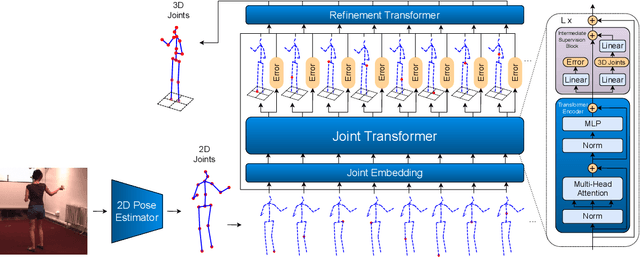
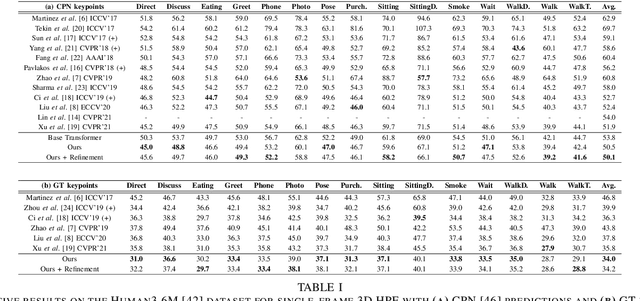
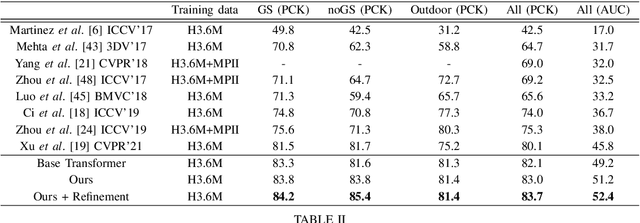
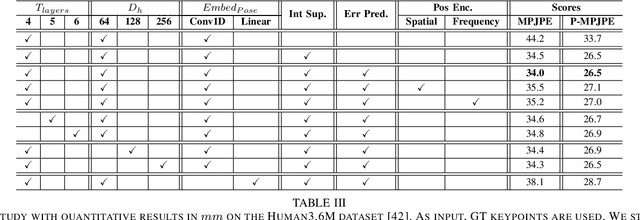
Monocular 3D human pose estimation technologies have the potential to greatly increase the availability of human movement data. The best-performing models for single-image 2D-3D lifting use graph convolutional networks (GCNs) that typically require some manual input to define the relationships between different body joints. We propose a novel transformer-based approach that uses the more generalised self-attention mechanism to learn these relationships within a sequence of tokens representing joints. We find that the use of intermediate supervision, as well as residual connections between the stacked encoders benefits performance. We also suggest that using error prediction as part of a multi-task learning framework improves performance by allowing the network to compensate for its confidence level. We perform extensive ablation studies to show that each of our contributions increases performance. Furthermore, we show that our approach outperforms the recent state of the art for single-frame 3D human pose estimation by a large margin. Our code and trained models are made publicly available on Github.
KinePose: A temporally optimized inverse kinematics technique for 6DOF human pose estimation with biomechanical constraints
Jul 26, 2022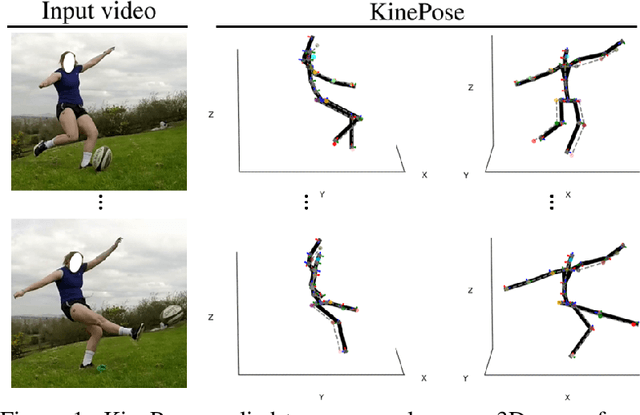

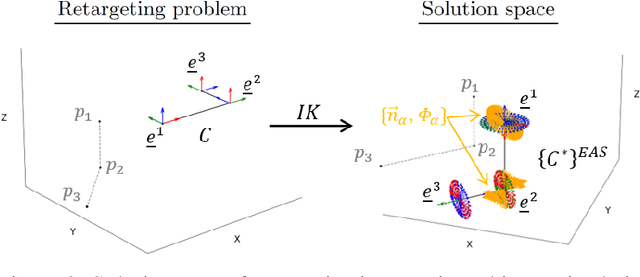
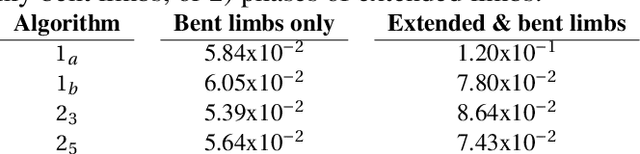
Computer vision/deep learning-based 3D human pose estimation methods aim to localize human joints from images and videos. Pose representation is normally limited to 3D joint positional/translational degrees of freedom (3DOFs), however, a further three rotational DOFs (6DOFs) are required for many potential biomechanical applications. Positional DOFs are insufficient to analytically solve for joint rotational DOFs in a 3D human skeletal model. Therefore, we propose a temporal inverse kinematics (IK) optimization technique to infer joint orientations throughout a biomechanically informed, and subject-specific kinematic chain. For this, we prescribe link directions from a position-based 3D pose estimate. Sequential least squares quadratic programming is used to solve a minimization problem that involves both frame-based pose terms, and a temporal term. The solution space is constrained using joint DOFs, and ranges of motion (ROMs). We generate 3D pose motion sequences to assess the IK approach both for general accuracy, and accuracy in boundary cases. Our temporal algorithm achieves 6DOF pose estimates with low Mean Per Joint Angular Separation (MPJAS) errors (3.7{\deg}/joint overall, & 1.6{\deg}/joint for lower limbs). With frame-by-frame IK we obtain low errors in the case of bent elbows and knees, however, motion sequences with phases of extended/straight limbs results in ambiguity in twist angle. With temporal IK, we reduce ambiguity for these poses, resulting in lower average errors.
* https://kevgildea.github.io/KinePose/