 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Self- and Cross-Triplet Correlations for Human-Object Interaction Detection
Jan 11, 2024



Human-Object Interaction (HOI) detection plays a vital role in scene understanding, which aims to predict the HOI triplet in the form of <human, object, action>. Existing methods mainly extract multi-modal features (e.g., appearance, object semantics, human pose) and then fuse them together to directly predict HOI triplets. However, most of these methods focus on seeking for self-triplet aggregation, but ignore the potential cross-triplet dependencies, resulting in ambiguity of action prediction. In this work, we propose to explore Self- and Cross-Triplet Correlations (SCTC) for HOI detection. Specifically, we regard each triplet proposal as a graph where Human, Object represent nodes and Action indicates edge, to aggregate self-triplet correlation. Also, we try to explore cross-triplet dependencies by jointly considering instance-level, semantic-level, and layout-level relations. Besides, we leverage the CLIP model to assist our SCTC obtain interaction-aware feature by knowledge distillation, which provides useful action clues for HOI detection. Extensive experiments on HICO-DET and V-COCO datasets verify the effectiveness of our proposed SCTC.
CountingMOT: Joint Counting, Detection and Re-Identification for Multiple Object Tracking
Dec 12, 2022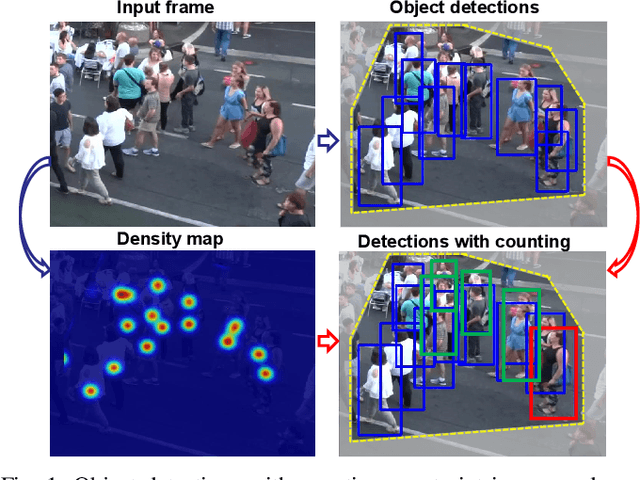
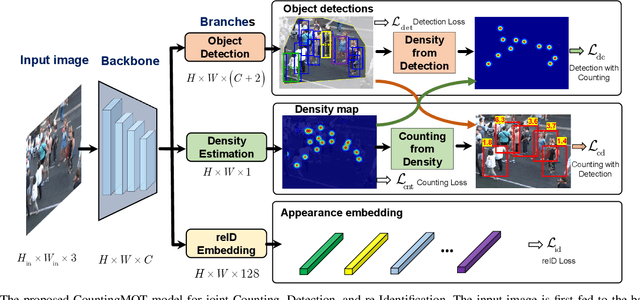


The recent trend in multiple object tracking (MOT) is jointly solving detection and tracking, where object detection and appearance feature (or motion) are learned simultaneously. Despite competitive performance, in crowded scenes, joint detection and tracking usually fail to find accurate object associations due to missed or false detections. In this paper, we jointly model counting, detection and re-identification in an end-to-end framework, named CountingMOT, tailored for crowded scenes. By imposing mutual object-count constraints between detection and counting, the CountingMOT tries to find a balance between object detection and crowd density map estimation, which can help it to recover missed detections or reject false detections. Our approach is an attempt to bridge the gap of object detection, counting, and re-Identification. This is in contrast to prior MOT methods that either ignore the crowd density and thus are prone to failure in crowded scenes, or depend on local correlations to build a graphical relationship for matching targets. The proposed MOT tracker can perform online and real-time tracking, and achieves the state-of-the-art results on public benchmarks MOT16 (MOTA of 77.6), MOT17 (MOTA of 78.0%) and MOT20 (MOTA of 70.2%).