 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Lesion Segmentation in PET/CT Imaging with Deep Learning and Advanced Data Preprocessing Techniques
Sep 15, 2024

The escalating global cancer burden underscores the critical need for precise diagnostic tools in oncology. This research employs deep learning to enhance lesion segmentation in PET/CT imaging, utilizing a dataset of 900 whole-body FDG-PET/CT and 600 PSMA-PET/CT studies from the AutoPET challenge III. Our methodical approach includes robust preprocessing and data augmentation techniques to ensure model robustness and generalizability. We investigate the influence of non-zero normalization and modifications to the data augmentation pipeline, such as the introduction of RandGaussianSharpen and adjustments to the Gamma transform parameter. This study aims to contribute to the standardization of preprocessing and augmentation strategies in PET/CT imaging, potentially improving the diagnostic accuracy and the personalized management of cancer patients. Our code will be open-sourced and available at https://github.com/jiayiliu-pku/DC2024.
Interactive 3D Medical Image Segmentation with SAM 2
Aug 05, 2024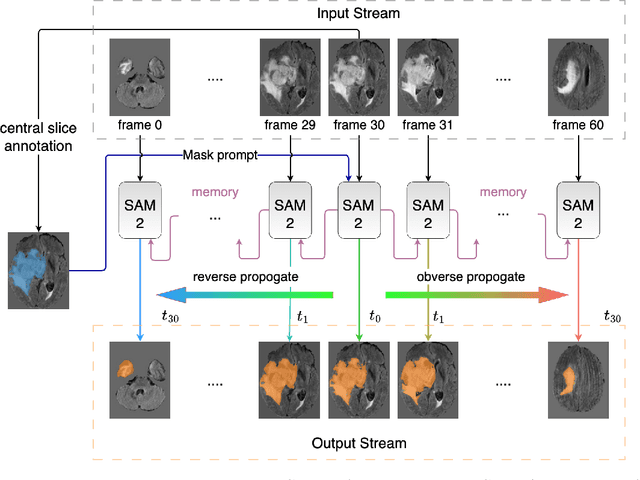
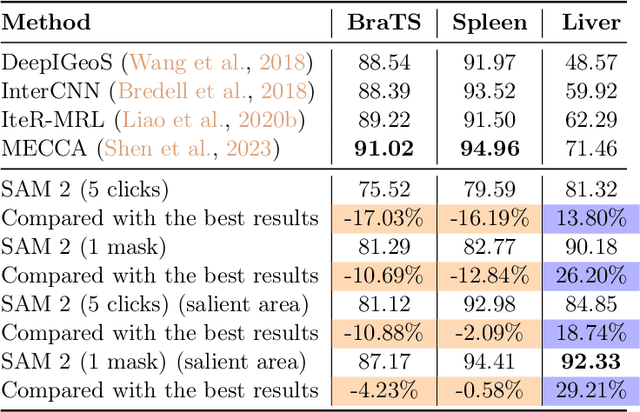
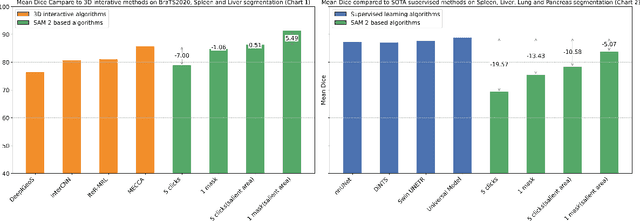
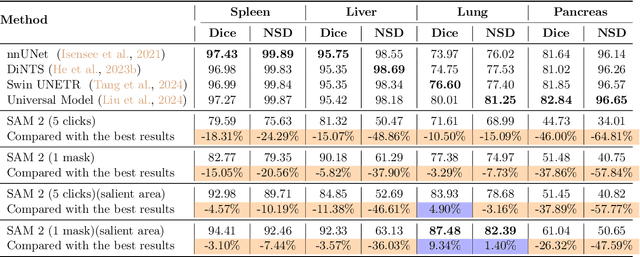
Interactive medical image segmentation (IMIS) has shown significant potential in enhancing segmentation accuracy by integrating iterative feedback from medical professionals. However, the limited availability of enough 3D medical data restricts the generalization and robustness of most IMIS methods. The Segment Anything Model (SAM), though effective for 2D images, requires expensive semi-auto slice-by-slice annotations for 3D medical images. In this paper, we explore the zero-shot capabilities of SAM 2, the next-generation Meta SAM model trained on videos, for 3D medical image segmentation. By treating sequential 2D slices of 3D images as video frames, SAM 2 can fully automatically propagate annotations from a single frame to the entire 3D volume. We propose a practical pipeline for using SAM 2 in 3D medical image segmentation and present key findings highlighting its efficiency and potential for further optimization. Concretely, numerical experiments on the BraTS2020 and the medical segmentation decathlon datasets demonstrate that SAM 2 still has a gap with supervised methods but can narrow the gap in specific settings and organ types, significantly reducing the annotation burden on medical professionals. Our code will be open-sourced and available at https://github.com/Chuyun-Shen/SAM_2_Medical_3D.
Channel-Feedback-Free Transmission for Downlink FD-RAN: A Radio Map based Complex-valued Precoding Network Approach
Nov 30, 2023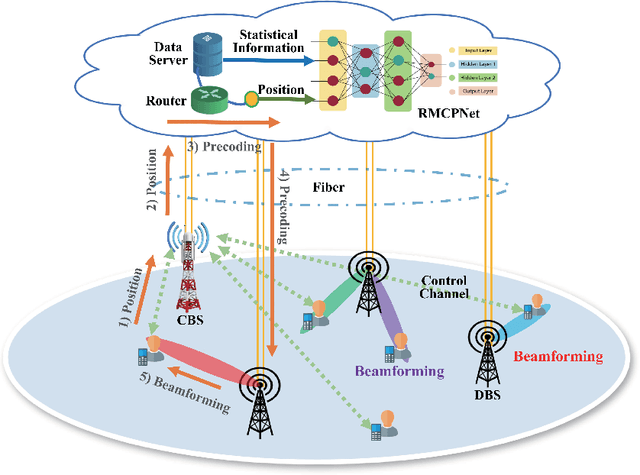
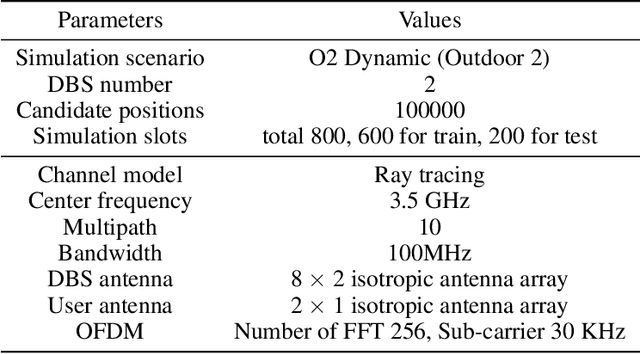
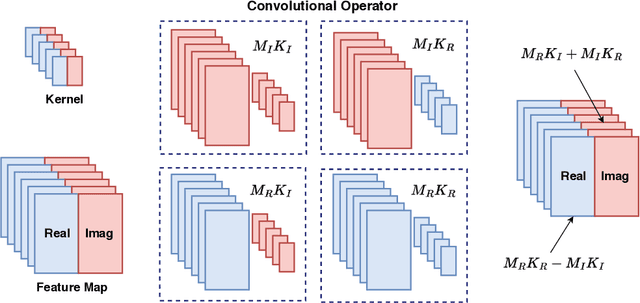
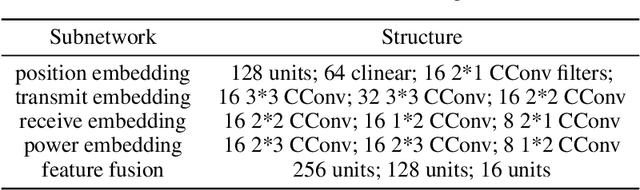
As the demand for high-quality services proliferates, an innovative network architecture, the fully-decoupled RAN (FD-RAN), has emerged for more flexible spectrum resource utilization and lower network costs. However, with the decoupling of uplink base stations and downlink base stations in FD-RAN, the traditional transmission mechanism, which relies on real-time channel feedback, is not suitable as the receiver is not able to feedback accurate and timely channel state information to the transmitter. This paper proposes a novel transmission scheme without relying on physical layer channel feedback. Specifically, we design a radio map based complex-valued precoding network~(RMCPNet) model, which outputs the base station precoding based on user location. RMCPNet comprises multiple subnets, with each subnet responsible for extracting unique modal features from diverse input modalities. Furthermore, the multi-modal embeddings derived from these distinct subnets are integrated within the information fusion layer, culminating in a unified representation. We also develop a specific RMCPNet training algorithm that employs the negative spectral efficiency as the loss function. We evaluate the performance of the proposed scheme on the public DeepMIMO dataset and show that RMCPNet can achieve 16\% and 76\% performance improvements over the conventional real-valued neural network and statistical codebook approach, respectively.
CountingMOT: Joint Counting, Detection and Re-Identification for Multiple Object Tracking
Dec 12, 2022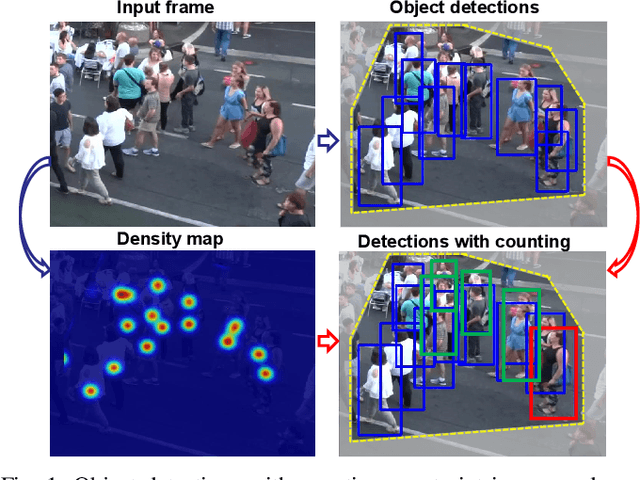
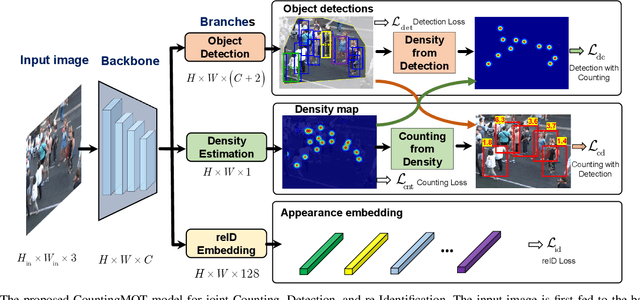


The recent trend in multiple object tracking (MOT) is jointly solving detection and tracking, where object detection and appearance feature (or motion) are learned simultaneously. Despite competitive performance, in crowded scenes, joint detection and tracking usually fail to find accurate object associations due to missed or false detections. In this paper, we jointly model counting, detection and re-identification in an end-to-end framework, named CountingMOT, tailored for crowded scenes. By imposing mutual object-count constraints between detection and counting, the CountingMOT tries to find a balance between object detection and crowd density map estimation, which can help it to recover missed detections or reject false detections. Our approach is an attempt to bridge the gap of object detection, counting, and re-Identification. This is in contrast to prior MOT methods that either ignore the crowd density and thus are prone to failure in crowded scenes, or depend on local correlations to build a graphical relationship for matching targets. The proposed MOT tracker can perform online and real-time tracking, and achieves the state-of-the-art results on public benchmarks MOT16 (MOTA of 77.6), MOT17 (MOTA of 78.0%) and MOT20 (MOTA of 70.2%).
Whole-Body Lesion Segmentation in 18F-FDG PET/CT
Sep 16, 2022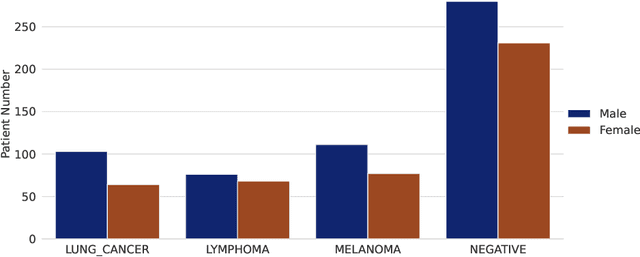
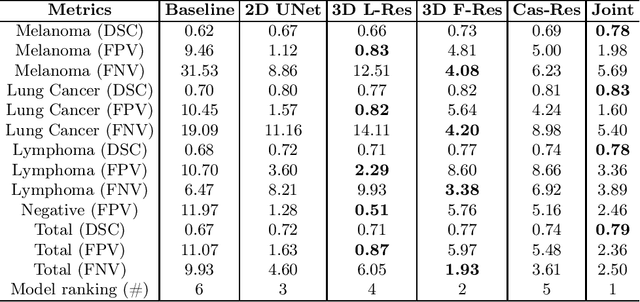
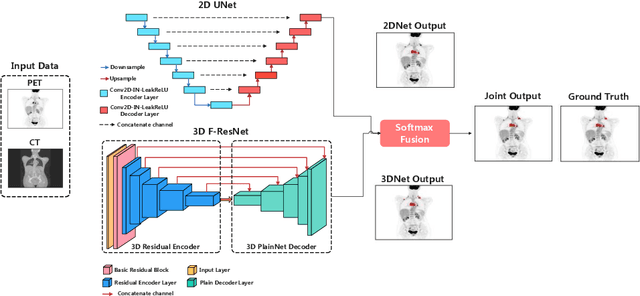
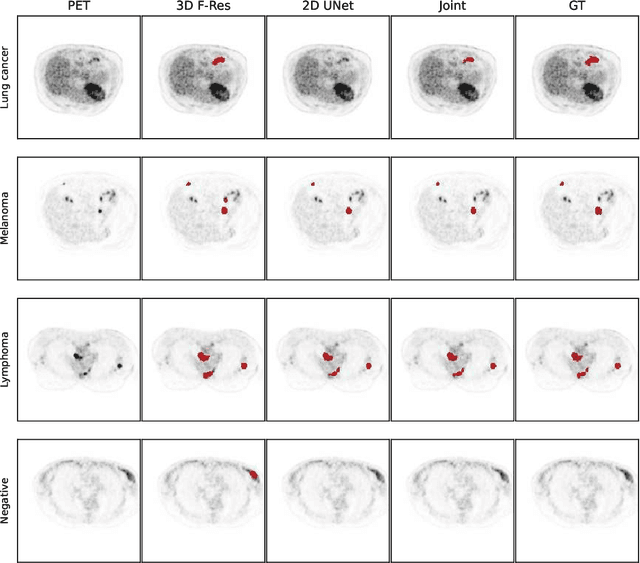
There has been growing research interest in using deep learning based method to achieve fully automated segmentation of lesion in Positron emission tomography computed tomography(PET CT) scans for the prognosis of various cancers. Recent advances in the medical image segmentation shows the nnUNET is feasible for diverse tasks. However, lesion segmentation in the PET images is not straightforward, because lesion and physiological uptake has similar distribution patterns. The Distinction of them requires extra structural information in the CT images. The present paper introduces a nnUNet based method for the lesion segmentation task. The proposed model is designed on the basis of the joint 2D and 3D nnUNET architecture to predict lesions across the whole body. It allows for automated segmentation of potential lesions. We evaluate the proposed method in the context of AutoPet Challenge, which measures the lesion segmentation performance in the metrics of dice score, false-positive volume and false-negative volume.