 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTextAtari: 100K Frames Game Playing with Language Agents
Jun 04, 2025We present TextAtari, a benchmark for evaluating language agents on very long-horizon decision-making tasks spanning up to 100,000 steps. By translating the visual state representations of classic Atari games into rich textual descriptions, TextAtari creates a challenging test bed that bridges sequential decision-making with natural language processing. The benchmark includes nearly 100 distinct tasks with varying complexity, action spaces, and planning horizons, all rendered as text through an unsupervised representation learning framework (AtariARI). We evaluate three open-source large language models (Qwen2.5-7B, Gemma-7B, and Llama3.1-8B) across three agent frameworks (zero-shot, few-shot chain-of-thought, and reflection reasoning) to assess how different forms of prior knowledge affect performance on these long-horizon challenges. Four scenarios-Basic, Obscured, Manual Augmentation, and Reference-based-investigate the impact of semantic understanding, instruction comprehension, and expert demonstrations on agent decision-making. Our results reveal significant performance gaps between language agents and human players in extensive planning tasks, highlighting challenges in sequential reasoning, state tracking, and strategic planning across tens of thousands of steps. TextAtari provides standardized evaluation protocols, baseline implementations, and a framework for advancing research at the intersection of language models and planning.
FPPL: An Efficient and Non-IID Robust Federated Continual Learning Framework
Nov 04, 2024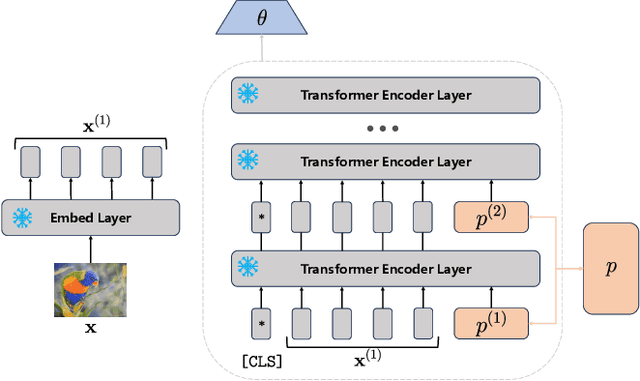
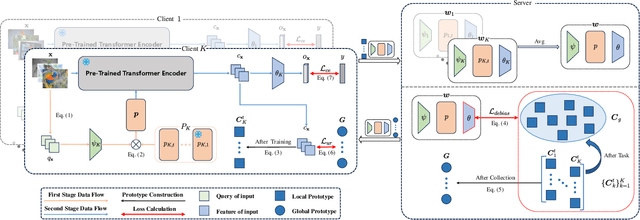
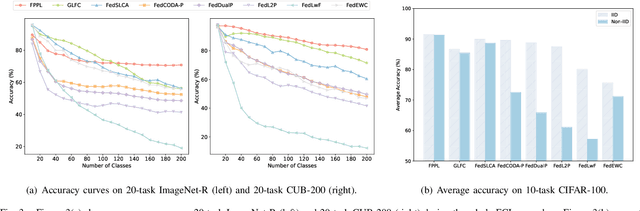
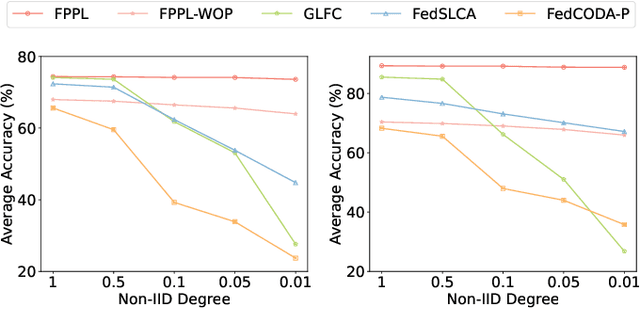
Federated continual learning (FCL) aims to learn from sequential data stream in the decentralized federated learning setting, while simultaneously mitigating the catastrophic forgetting issue in classical continual learning. Existing FCL methods usually employ typical rehearsal mechanisms, which could result in privacy violations or additional onerous storage and computational burdens. In this work, an efficient and non-IID robust federated continual learning framework, called Federated Prototype-Augmented Prompt Learning (FPPL), is proposed. The FPPL can collaboratively learn lightweight prompts augmented by prototypes without rehearsal. On the client side, a fusion function is employed to fully leverage the knowledge contained in task-specific prompts for alleviating catastrophic forgetting. Additionally, global prototypes aggregated from the server are used to obtain unified representation through contrastive learning, mitigating the impact of non-IID-derived data heterogeneity. On the server side, locally uploaded prototypes are utilized to perform debiasing on the classifier, further alleviating the performance degradation caused by both non-IID and catastrophic forgetting. Empirical evaluations demonstrate the effectiveness of FPPL, achieving notable performance with an efficient design while remaining robust to diverse non-IID degrees. Code is available at: https://github.com/ycheoo/FPPL.
Enhancing Lesion Segmentation in PET/CT Imaging with Deep Learning and Advanced Data Preprocessing Techniques
Sep 15, 2024

The escalating global cancer burden underscores the critical need for precise diagnostic tools in oncology. This research employs deep learning to enhance lesion segmentation in PET/CT imaging, utilizing a dataset of 900 whole-body FDG-PET/CT and 600 PSMA-PET/CT studies from the AutoPET challenge III. Our methodical approach includes robust preprocessing and data augmentation techniques to ensure model robustness and generalizability. We investigate the influence of non-zero normalization and modifications to the data augmentation pipeline, such as the introduction of RandGaussianSharpen and adjustments to the Gamma transform parameter. This study aims to contribute to the standardization of preprocessing and augmentation strategies in PET/CT imaging, potentially improving the diagnostic accuracy and the personalized management of cancer patients. Our code will be open-sourced and available at https://github.com/jiayiliu-pku/DC2024.
Interactive 3D Medical Image Segmentation with SAM 2
Aug 05, 2024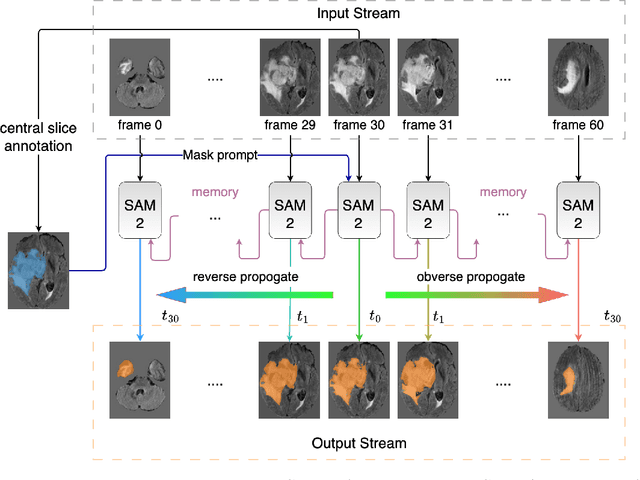
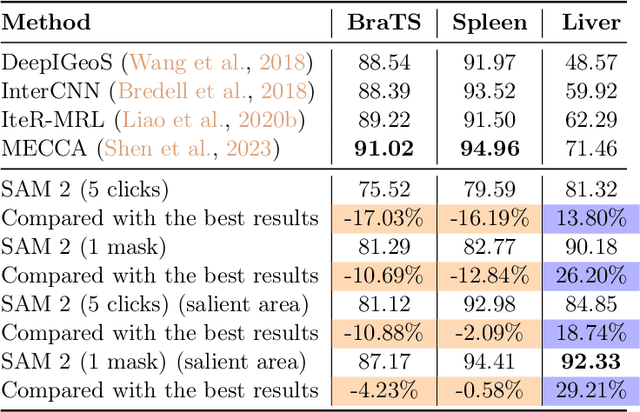
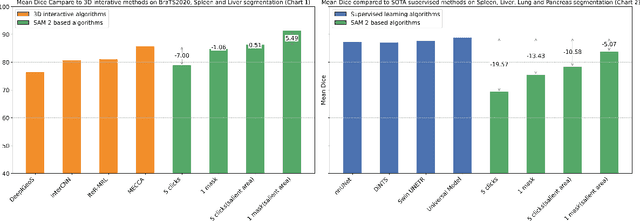
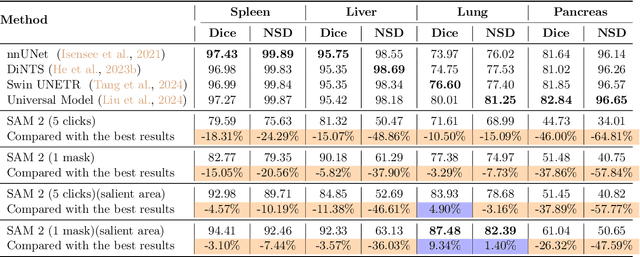
Interactive medical image segmentation (IMIS) has shown significant potential in enhancing segmentation accuracy by integrating iterative feedback from medical professionals. However, the limited availability of enough 3D medical data restricts the generalization and robustness of most IMIS methods. The Segment Anything Model (SAM), though effective for 2D images, requires expensive semi-auto slice-by-slice annotations for 3D medical images. In this paper, we explore the zero-shot capabilities of SAM 2, the next-generation Meta SAM model trained on videos, for 3D medical image segmentation. By treating sequential 2D slices of 3D images as video frames, SAM 2 can fully automatically propagate annotations from a single frame to the entire 3D volume. We propose a practical pipeline for using SAM 2 in 3D medical image segmentation and present key findings highlighting its efficiency and potential for further optimization. Concretely, numerical experiments on the BraTS2020 and the medical segmentation decathlon datasets demonstrate that SAM 2 still has a gap with supervised methods but can narrow the gap in specific settings and organ types, significantly reducing the annotation burden on medical professionals. Our code will be open-sourced and available at https://github.com/Chuyun-Shen/SAM_2_Medical_3D.
Complementary Information Mutual Learning for Multimodality Medical Image Segmentation
Jan 05, 2024



Radiologists must utilize multiple modal images for tumor segmentation and diagnosis due to the limitations of medical imaging and the diversity of tumor signals. This leads to the development of multimodal learning in segmentation. However, the redundancy among modalities creates challenges for existing subtraction-based joint learning methods, such as misjudging the importance of modalities, ignoring specific modal information, and increasing cognitive load. These thorny issues ultimately decrease segmentation accuracy and increase the risk of overfitting. This paper presents the complementary information mutual learning (CIML) framework, which can mathematically model and address the negative impact of inter-modal redundant information. CIML adopts the idea of addition and removes inter-modal redundant information through inductive bias-driven task decomposition and message passing-based redundancy filtering. CIML first decomposes the multimodal segmentation task into multiple subtasks based on expert prior knowledge, minimizing the information dependence between modalities. Furthermore, CIML introduces a scheme in which each modality can extract information from other modalities additively through message passing. To achieve non-redundancy of extracted information, the redundant filtering is transformed into complementary information learning inspired by the variational information bottleneck. The complementary information learning procedure can be efficiently solved by variational inference and cross-modal spatial attention. Numerical results from the verification task and standard benchmarks indicate that CIML efficiently removes redundant information between modalities, outperforming SOTA methods regarding validation accuracy and segmentation effect.
Can language agents be alternatives to PPO? A Preliminary Empirical Study On OpenAI Gym
Dec 06, 2023The formidable capacity for zero- or few-shot decision-making in language agents encourages us to pose a compelling question: Can language agents be alternatives to PPO agents in traditional sequential decision-making tasks? To investigate this, we first take environments collected in OpenAI Gym as our testbeds and ground them to textual environments that construct the TextGym simulator. This allows for straightforward and efficient comparisons between PPO agents and language agents, given the widespread adoption of OpenAI Gym. To ensure a fair and effective benchmarking, we introduce $5$ levels of scenario for accurate domain-knowledge controlling and a unified RL-inspired framework for language agents. Additionally, we propose an innovative explore-exploit-guided language (EXE) agent to solve tasks within TextGym. Through numerical experiments and ablation studies, we extract valuable insights into the decision-making capabilities of language agents and make a preliminary evaluation of their potential to be alternatives to PPO in classical sequential decision-making problems. This paper sheds light on the performance of language agents and paves the way for future research in this exciting domain. Our code is publicly available at~\url{https://github.com/mail-ecnu/Text-Gym-Agents}.
Temporally-Extended Prompts Optimization for SAM in Interactive Medical Image Segmentation
Jun 15, 2023The Segmentation Anything Model (SAM) has recently emerged as a foundation model for addressing image segmentation. Owing to the intrinsic complexity of medical images and the high annotation cost, the medical image segmentation (MIS) community has been encouraged to investigate SAM's zero-shot capabilities to facilitate automatic annotation. Inspired by the extraordinary accomplishments of interactive medical image segmentation (IMIS) paradigm, this paper focuses on assessing the potential of SAM's zero-shot capabilities within the IMIS paradigm to amplify its benefits in the MIS domain. Regrettably, we observe that SAM's vulnerability to prompt forms (e.g., points, bounding boxes) becomes notably pronounced in IMIS. This leads us to develop a framework that adaptively offers suitable prompt forms for human experts. We refer to the framework above as temporally-extended prompts optimization (TEPO) and model it as a Markov decision process, solvable through reinforcement learning. Numerical experiments on the standardized benchmark BraTS2020 demonstrate that the learned TEPO agent can further enhance SAM's zero-shot capability in the MIS context.
Interactive Medical Image Segmentation with Self-Adaptive Confidence Calibration
Nov 15, 2021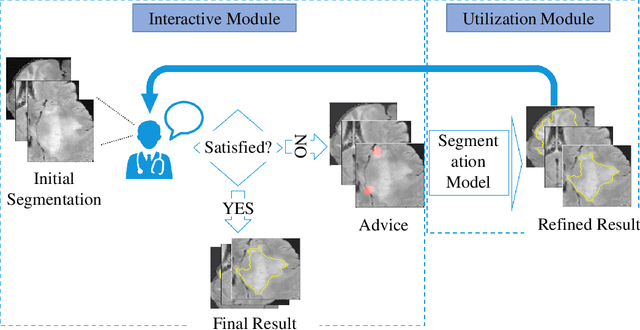
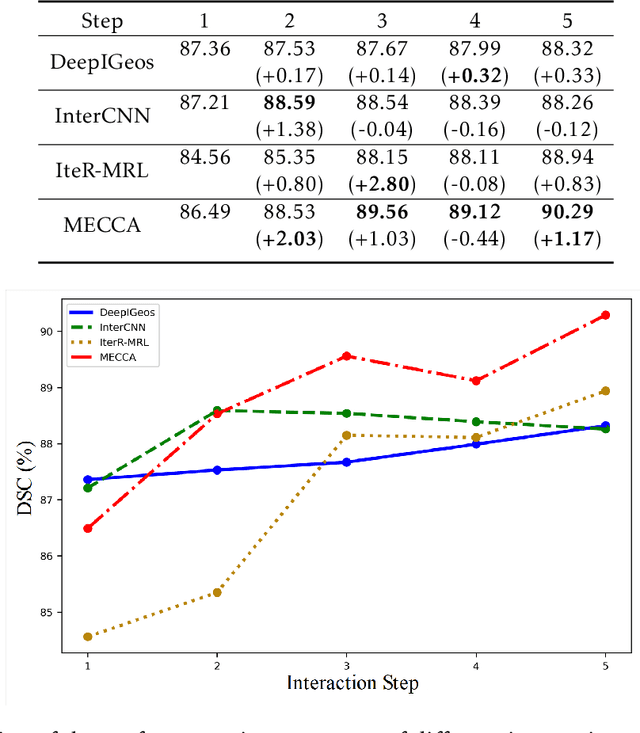
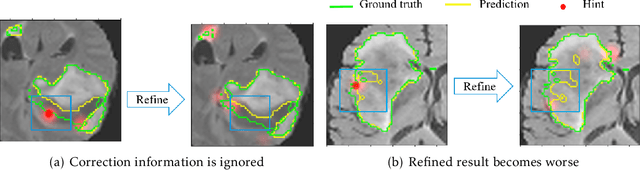

Medical image segmentation is one of the fundamental problems for artificial intelligence-based clinical decision systems. Current automatic medical image segmentation methods are often failed to meet clinical requirements. As such, a series of interactive segmentation algorithms are proposed to utilize expert correction information. However, existing methods suffer from some segmentation refining failure problems after long-term interactions and some cost problems from expert annotation, which hinder clinical applications. This paper proposes an interactive segmentation framework, called interactive MEdical segmentation with self-adaptive Confidence CAlibration (MECCA), by introducing the corrective action evaluation, which combines the action-based confidence learning and multi-agent reinforcement learning (MARL). The evaluation is established through a novel action-based confidence network, and the corrective actions are obtained from MARL. Based on the confidential information, a self-adaptive reward function is designed to provide more detailed feedback, and a simulated label generation mechanism is proposed on unsupervised data to reduce over-reliance on labeled data. Experimental results on various medical image datasets have shown the significant performance of the proposed algorithm.