 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWT-UMI: Tactile-based Whole-Body Manipulation via Force-Supervised Contact-Aware Planning
Jun 11, 2026Whole-body humanoid manipulation of bulky, deformable, and shared-load objects requires distributed contact sensing and explicit force regulation, yet most imitation policies treat contact force only implicitly. On the other hand, different demonstration sources provide complementary modalities with inherent trade-offs: human demonstrations capture natural contact forces but not robot-executable actions, while teleoperation directly records robot actions but with less natural force regulation. This paper presents \textbf{WT-UMI}, a wearable whole-body tactile interface worn by human operators or mounted on humanoids, providing accurate observations of tactile images, contact forces, and end-effector poses across both human demonstration and humanoid teleoperation modes. We introduce a force-conditioned target-pose correction module that converts measured human poses into contact-aware robot targets by learning corrections from teleoperation data. To leverage the natural force interaction in human data, we propose a force-supervised planner that predicts end-effector pose chunks and contact-force trajectories. The predicted contact force serves as the reference for a tactile-based admittance controller. Across five contact-rich tasks spanning deformable objects, bulky rigid objects, and human--humanoid collaboration, WT-UMI improves success rate and reduces contact-position tracking error over four policy baselines. Our project page is available at https://wt-umi.github.io/WTUMI/.
AscendOptimizer: Episodic Agent for Ascend NPU Operator Optimization
Mar 24, 2026AscendC (Ascend C) operator optimization on Huawei Ascend neural processing units (NPUs) faces a two-fold knowledge bottleneck: unlike the CUDA ecosystem, there are few public reference implementations to learn from, and performance hinges on a coupled two-part artifact - a host-side tiling program that orchestrates data movement and a kernel program that schedules and pipelines instructions. We present AscendOptimizer, an episodic agent that bootstraps this missing expertise by turning execution into experience. On the host side, AscendOptimizer performs profiling-in-the-loop evolutionary search to discover valid and high-performing tiling and data-movement configurations directly from hardware feedback. On the kernel side, it mines transferable optimization motifs by rewinding optimized kernels - systematically de-optimizing them to synthesize instructive "bad-to-good" trajectories - and distills these motifs into a retrievable experience bank for guided rewriting. By alternating host tuning and kernel rewriting in a closed loop, AscendOptimizer steadily expands feasibility and pushes latency down. On a benchmark of 127 real AscendC operators, AscendOptimizer achieves a 1.19x geometric-mean speedup over the open-source baseline, with 49.61% of operators outperforming their references, outperforming strong agent and search baselines.
Towards Cold-Start Drafting and Continual Refining: A Value-Driven Memory Approach with Application to NPU Kernel Synthesis
Mar 11, 2026Deploying Large Language Models to data-scarce programming domains poses significant challenges, particularly for kernel synthesis on emerging Domain-Specific Architectures where a "Data Wall" limits available training data. While models excel on data-rich platforms like CUDA, they suffer catastrophic performance drops on data-scarce ecosystems such as NPU programming. To overcome this cold-start barrier without expensive fine-tuning, we introduce EvoKernel, a self-evolving agentic framework that automates the lifecycle of kernel synthesis from initial drafting to continual refining. EvoKernel addresses this by formulating the synthesis process as a memory-based reinforcement learning task. Through a novel value-driven retrieval mechanism, it learns stage-specific Q-values that prioritize experiences based on their contribution to the current objective, whether bootstrapping a feasible draft or iteratively refining latency. Furthermore, by enabling cross-task memory sharing, the agent generalizes insights from simple to complex operators. By building an NPU variant of KernelBench and evaluating on it, EvoKernel improves frontier models' correctness from 11.0% to 83.0% and achieves a median speedup of 3.60x over initial drafts through iterative refinement. This demonstrates that value-guided experience accumulation allows general-purpose models to master the kernel synthesis task on niche hardware ecosystems. Our official page is available at https://evokernel.zhuo.li.
TextAtari: 100K Frames Game Playing with Language Agents
Jun 04, 2025We present TextAtari, a benchmark for evaluating language agents on very long-horizon decision-making tasks spanning up to 100,000 steps. By translating the visual state representations of classic Atari games into rich textual descriptions, TextAtari creates a challenging test bed that bridges sequential decision-making with natural language processing. The benchmark includes nearly 100 distinct tasks with varying complexity, action spaces, and planning horizons, all rendered as text through an unsupervised representation learning framework (AtariARI). We evaluate three open-source large language models (Qwen2.5-7B, Gemma-7B, and Llama3.1-8B) across three agent frameworks (zero-shot, few-shot chain-of-thought, and reflection reasoning) to assess how different forms of prior knowledge affect performance on these long-horizon challenges. Four scenarios-Basic, Obscured, Manual Augmentation, and Reference-based-investigate the impact of semantic understanding, instruction comprehension, and expert demonstrations on agent decision-making. Our results reveal significant performance gaps between language agents and human players in extensive planning tasks, highlighting challenges in sequential reasoning, state tracking, and strategic planning across tens of thousands of steps. TextAtari provides standardized evaluation protocols, baseline implementations, and a framework for advancing research at the intersection of language models and planning.
Learning Virtual Machine Scheduling in Cloud Computing through Language Agents
May 15, 2025



In cloud services, virtual machine (VM) scheduling is a typical Online Dynamic Multidimensional Bin Packing (ODMBP) problem, characterized by large-scale complexity and fluctuating demands. Traditional optimization methods struggle to adapt to real-time changes, domain-expert-designed heuristic approaches suffer from rigid strategies, and existing learning-based methods often lack generalizability and interpretability. To address these limitations, this paper proposes a hierarchical language agent framework named MiCo, which provides a large language model (LLM)-driven heuristic design paradigm for solving ODMBP. Specifically, ODMBP is formulated as a Semi-Markov Decision Process with Options (SMDP-Option), enabling dynamic scheduling through a two-stage architecture, i.e., Option Miner and Option Composer. Option Miner utilizes LLMs to discover diverse and useful non-context-aware strategies by interacting with constructed environments. Option Composer employs LLMs to discover a composing strategy that integrates the non-context-aware strategies with the contextual ones. Extensive experiments on real-world enterprise datasets demonstrate that MiCo achieves a 96.9\% competitive ratio in large-scale scenarios involving more than 10,000 virtual machines. It maintains high performance even under nonstationary request flows and diverse configurations, thus validating its effectiveness in complex and large-scale cloud environments.
GraphThought: Graph Combinatorial Optimization with Thought Generation
Feb 17, 2025Large language models (LLMs) have demonstrated remarkable capabilities across various domains, especially in text processing and generative tasks. Recent advancements in the reasoning capabilities of state-of-the-art LLMs, such as OpenAI-o1, have significantly broadened their applicability, particularly in complex problem-solving and logical inference. However, most existing LLMs struggle with notable limitations in handling graph combinatorial optimization (GCO) problems. To bridge this gap, we formally define the Optimal Thoughts Design (OTD) problem, including its state and action thought space. We then introduce a novel framework, GraphThought, designed to generate high-quality thought datasets for GCO problems. Leveraging these datasets, we fine-tune the Llama-3-8B-Instruct model to develop Llama-GT. Notably, despite its compact 8B-parameter architecture, Llama-GT matches the performance of state-of-the-art LLMs on the GraphArena benchmark. Experimental results show that our approach outperforms both proprietary and open-source models, even rivaling specialized models like o1-mini. This work sets a new state-of-the-art benchmark while challenging the prevailing notion that model scale is the primary driver of reasoning capability.
Can language agents be alternatives to PPO? A Preliminary Empirical Study On OpenAI Gym
Dec 06, 2023The formidable capacity for zero- or few-shot decision-making in language agents encourages us to pose a compelling question: Can language agents be alternatives to PPO agents in traditional sequential decision-making tasks? To investigate this, we first take environments collected in OpenAI Gym as our testbeds and ground them to textual environments that construct the TextGym simulator. This allows for straightforward and efficient comparisons between PPO agents and language agents, given the widespread adoption of OpenAI Gym. To ensure a fair and effective benchmarking, we introduce $5$ levels of scenario for accurate domain-knowledge controlling and a unified RL-inspired framework for language agents. Additionally, we propose an innovative explore-exploit-guided language (EXE) agent to solve tasks within TextGym. Through numerical experiments and ablation studies, we extract valuable insights into the decision-making capabilities of language agents and make a preliminary evaluation of their potential to be alternatives to PPO in classical sequential decision-making problems. This paper sheds light on the performance of language agents and paves the way for future research in this exciting domain. Our code is publicly available at~\url{https://github.com/mail-ecnu/Text-Gym-Agents}.
Negotiated Reasoning: On Provably Addressing Relative Over-Generalization
Jun 08, 2023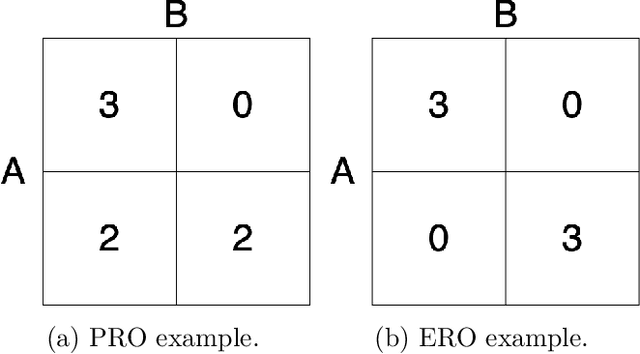

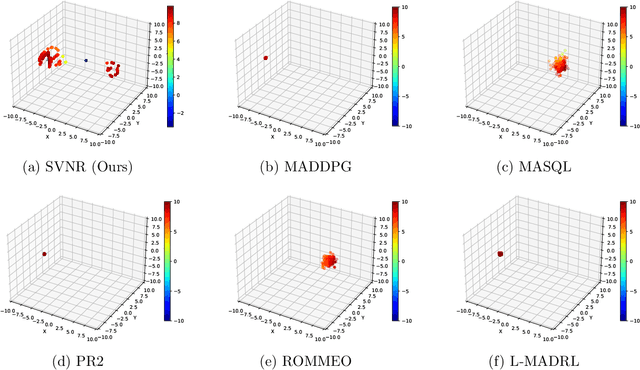
Over-generalization is a thorny issue in cognitive science, where people may become overly cautious due to past experiences. Agents in multi-agent reinforcement learning (MARL) also have been found to suffer relative over-generalization (RO) as people do and stuck to sub-optimal cooperation. Recent methods have shown that assigning reasoning ability to agents can mitigate RO algorithmically and empirically, but there has been a lack of theoretical understanding of RO, let alone designing provably RO-free methods. This paper first proves that RO can be avoided when the MARL method satisfies a consistent reasoning requirement under certain conditions. Then we introduce a novel reasoning framework, called negotiated reasoning, that first builds the connection between reasoning and RO with theoretical justifications. After that, we propose an instantiated algorithm, Stein variational negotiated reasoning (SVNR), which uses Stein variational gradient descent to derive a negotiation policy that provably avoids RO in MARL under maximum entropy policy iteration. The method is further parameterized with neural networks for amortized learning, making computation efficient. Numerical experiments on many RO-challenged environments demonstrate the superiority and efficiency of SVNR compared to state-of-the-art methods in addressing RO.
ReAssigner: A Plug-and-Play Virtual Machine Scheduling Intensifier for Heterogeneous Requests
Nov 29, 2022With the rapid development of cloud computing, virtual machine scheduling has become one of the most important but challenging issues for the cloud computing community, especially for practical heterogeneous request sequences. By analyzing the impact of request heterogeneity on some popular heuristic schedulers, it can be found that existing scheduling algorithms can not handle the request heterogeneity properly and efficiently. In this paper, a plug-and-play virtual machine scheduling intensifier, called Resource Assigner (ReAssigner), is proposed to enhance the scheduling efficiency of any given scheduler for heterogeneous requests. The key idea of ReAssigner is to pre-assign roles to physical resources and let resources of the same role form a virtual cluster to handle homogeneous requests. ReAssigner can cooperate with arbitrary schedulers by restricting their scheduling space to virtual clusters. With evaluations on the real dataset from Huawei Cloud, the proposed ReAssigner achieves significant scheduling performance improvement compared with some state-of-the-art scheduling methods.
Learning Cooperative Oversubscription for Cloud by Chance-Constrained Multi-Agent Reinforcement Learning
Nov 21, 2022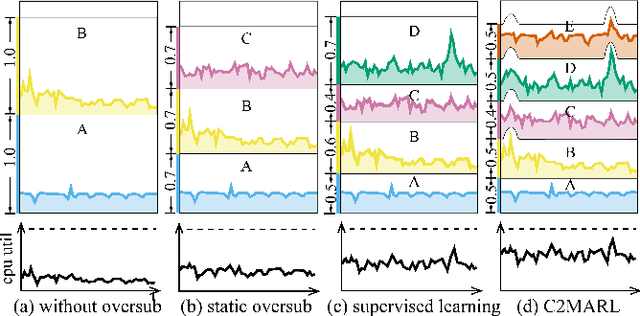
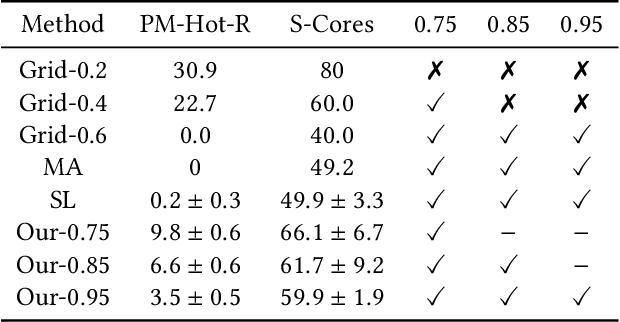
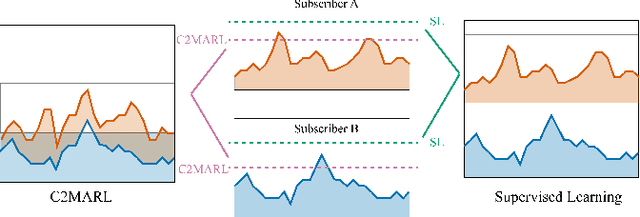
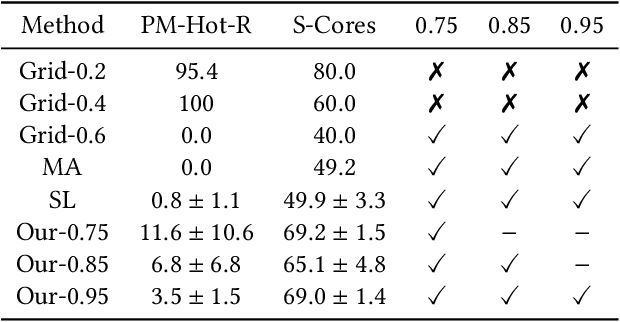
Oversubscription is a common practice for improving cloud resource utilization. It allows the cloud service provider to sell more resources than the physical limit, assuming not all users would fully utilize the resources simultaneously. However, how to design an oversubscription policy that improves utilization while satisfying the some safety constraints remains an open problem. Existing methods and industrial practices are over-conservative, ignoring the coordination of diverse resource usage patterns and probabilistic constraints. To address these two limitations, this paper formulates the oversubscription for cloud as a chance-constrained optimization problem and propose an effective Chance Constrained Multi-Agent Reinforcement Learning (C2MARL) method to solve this problem. Specifically, C2MARL reduces the number of constraints by considering their upper bounds and leverages a multi-agent reinforcement learning paradigm to learn a safe and optimal coordination policy. We evaluate our C2MARL on an internal cloud platform and public cloud datasets. Experiments show that our C2MARL outperforms existing methods in improving utilization ($20\%\sim 86\%$) under different levels of safety constraints.