 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDealing with Non-Stationarity in Multi-Agent Reinforcement Learning via Trust Region Decomposition
Paper and Code
Feb 21, 2021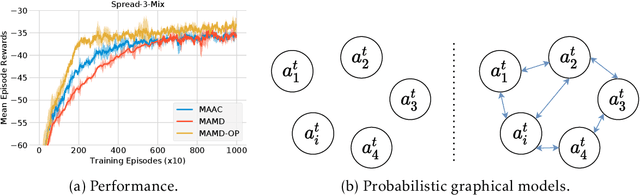
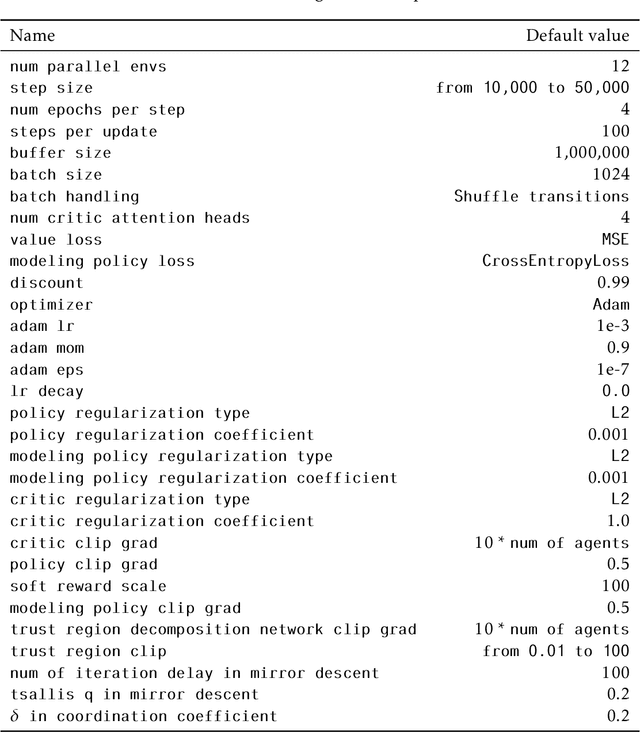

Non-stationarity is one thorny issue in multi-agent reinforcement learning, which is caused by the policy changes of agents during the learning procedure. Current works to solve this problem have their own limitations in effectiveness and scalability, such as centralized critic and decentralized actor (CCDA), population-based self-play, modeling of others and etc. In this paper, we novelly introduce a $\delta$-stationarity measurement to explicitly model the stationarity of a policy sequence, which is theoretically proved to be proportional to the joint policy divergence. However, simple policy factorization like mean-field approximation will mislead to larger policy divergence, which can be considered as trust region decomposition dilemma. We model the joint policy as a general Markov random field and propose a trust region decomposition network based on message passing to estimate the joint policy divergence more accurately. The Multi-Agent Mirror descent policy algorithm with Trust region decomposition, called MAMT, is established with the purpose to satisfy $\delta$-stationarity. MAMT can adjust the trust region of the local policies adaptively in an end-to-end manner, thereby approximately constraining the divergence of joint policy to alleviate the non-stationary problem. Our method can bring noticeable and stable performance improvement compared with baselines in coordination tasks of different complexity.