 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDutyTTE: Deciphering Uncertainty in Origin-Destination Travel Time Estimation
Aug 23, 2024Uncertainty quantification in travel time estimation (TTE) aims to estimate the confidence interval for travel time, given the origin (O), destination (D), and departure time (T). Accurately quantifying this uncertainty requires generating the most likely path and assessing travel time uncertainty along the path. This involves two main challenges: 1) Predicting a path that aligns with the ground truth, and 2) modeling the impact of travel time in each segment on overall uncertainty under varying conditions. We propose DutyTTE to address these challenges. For the first challenge, we introduce a deep reinforcement learning method to improve alignment between the predicted path and the ground truth, providing more accurate travel time information from road segments to improve TTE. For the second challenge, we propose a mixture of experts guided uncertainty quantification mechanism to better capture travel time uncertainty for each segment under varying contexts. Additionally, we calibrate our results using Hoeffding's upper-confidence bound to provide statistical guarantees for the estimated confidence intervals. Extensive experiments on two real-world datasets demonstrate the superiority of our proposed method.
Boundary-aware Supervoxel-level Iteratively Refined Interactive 3D Image Segmentation with Multi-agent Reinforcement Learning
Mar 19, 2023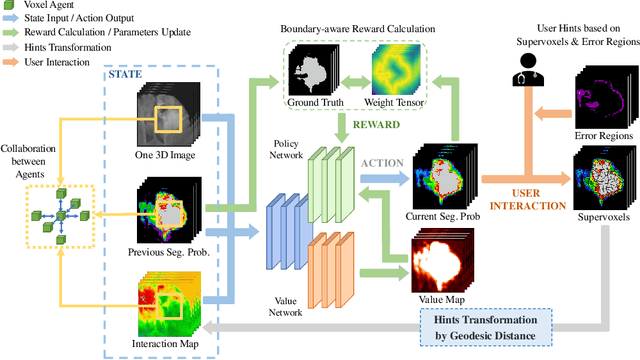
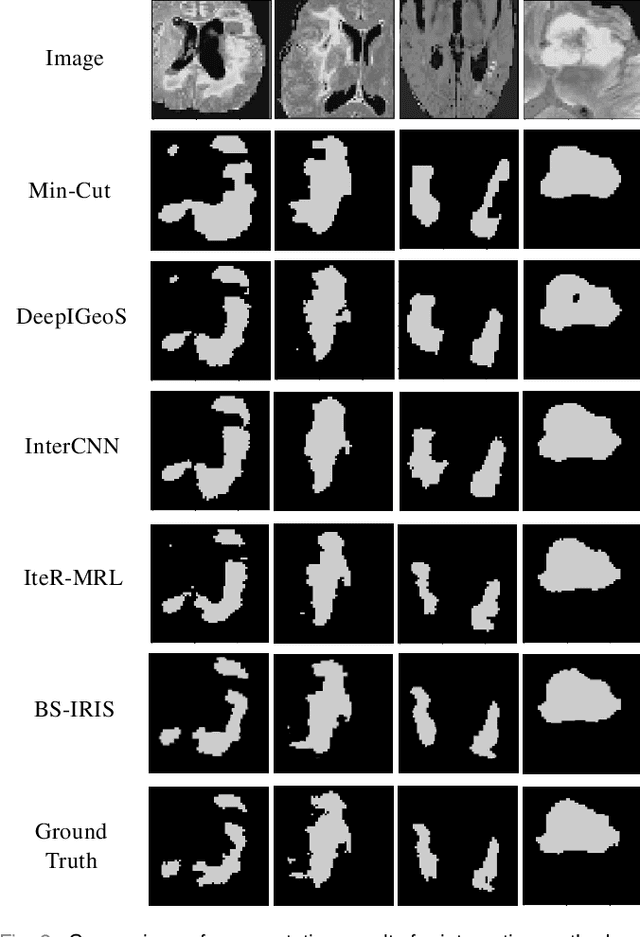
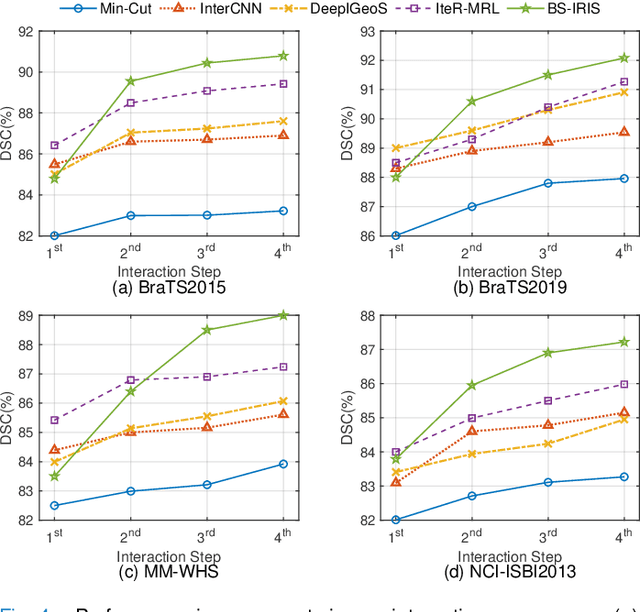
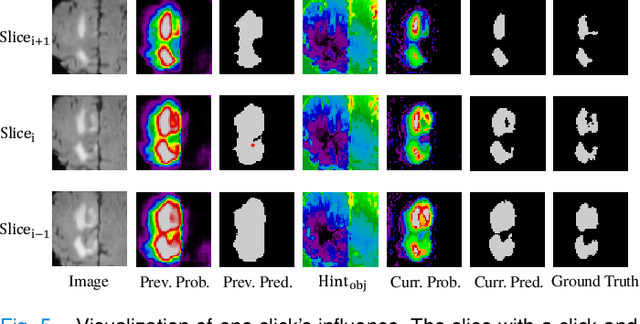
Interactive segmentation has recently been explored to effectively and efficiently harvest high-quality segmentation masks by iteratively incorporating user hints. While iterative in nature, most existing interactive segmentation methods tend to ignore the dynamics of successive interactions and take each interaction independently. We here propose to model iterative interactive image segmentation with a Markov decision process (MDP) and solve it with reinforcement learning (RL) where each voxel is treated as an agent. Considering the large exploration space for voxel-wise prediction and the dependence among neighboring voxels for the segmentation tasks, multi-agent reinforcement learning is adopted, where the voxel-level policy is shared among agents. Considering that boundary voxels are more important for segmentation, we further introduce a boundary-aware reward, which consists of a global reward in the form of relative cross-entropy gain, to update the policy in a constrained direction, and a boundary reward in the form of relative weight, to emphasize the correctness of boundary predictions. To combine the advantages of different types of interactions, i.e., simple and efficient for point-clicking, and stable and robust for scribbles, we propose a supervoxel-clicking based interaction design. Experimental results on four benchmark datasets have shown that the proposed method significantly outperforms the state-of-the-arts, with the advantage of fewer interactions, higher accuracy, and enhanced robustness.
* Accepted by IEEE Transactions on Medical Imaging
Interactive Medical Image Segmentation with Self-Adaptive Confidence Calibration
Nov 15, 2021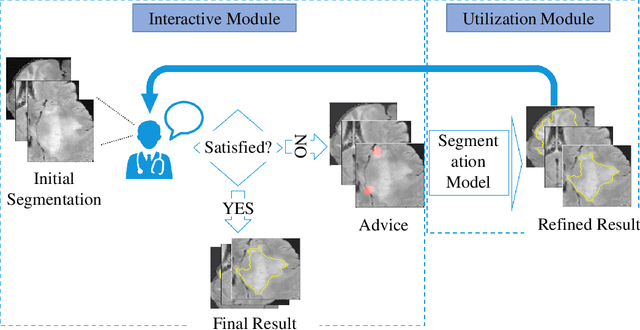
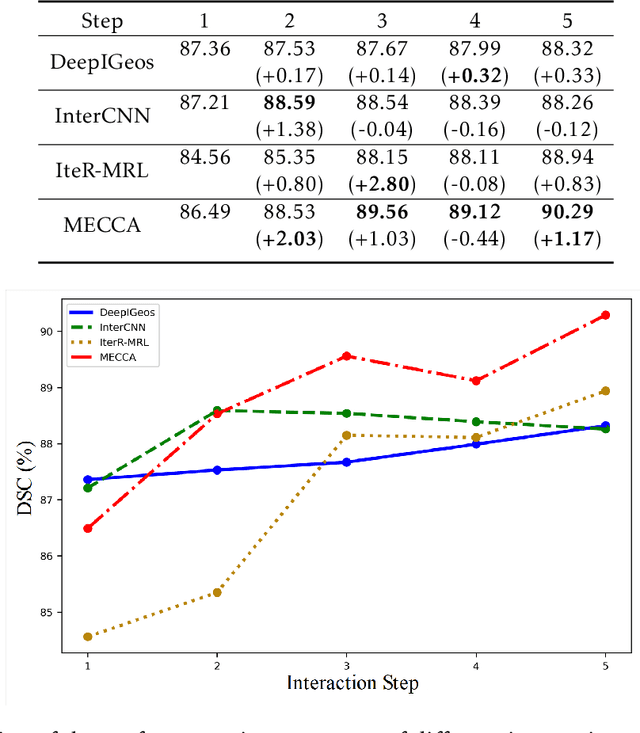
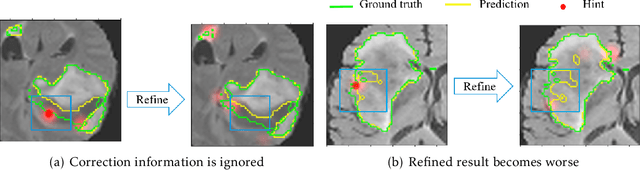

Medical image segmentation is one of the fundamental problems for artificial intelligence-based clinical decision systems. Current automatic medical image segmentation methods are often failed to meet clinical requirements. As such, a series of interactive segmentation algorithms are proposed to utilize expert correction information. However, existing methods suffer from some segmentation refining failure problems after long-term interactions and some cost problems from expert annotation, which hinder clinical applications. This paper proposes an interactive segmentation framework, called interactive MEdical segmentation with self-adaptive Confidence CAlibration (MECCA), by introducing the corrective action evaluation, which combines the action-based confidence learning and multi-agent reinforcement learning (MARL). The evaluation is established through a novel action-based confidence network, and the corrective actions are obtained from MARL. Based on the confidential information, a self-adaptive reward function is designed to provide more detailed feedback, and a simulated label generation mechanism is proposed on unsupervised data to reduce over-reliance on labeled data. Experimental results on various medical image datasets have shown the significant performance of the proposed algorithm.
Iteratively-Refined Interactive 3D Medical Image Segmentation with Multi-Agent Reinforcement Learning
Nov 23, 2019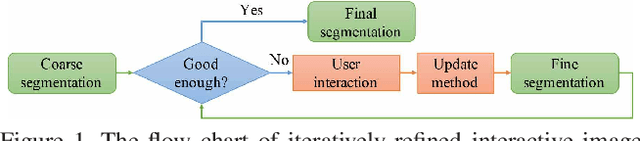
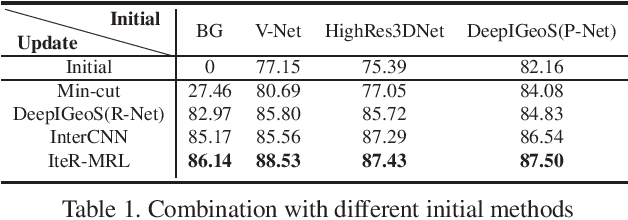
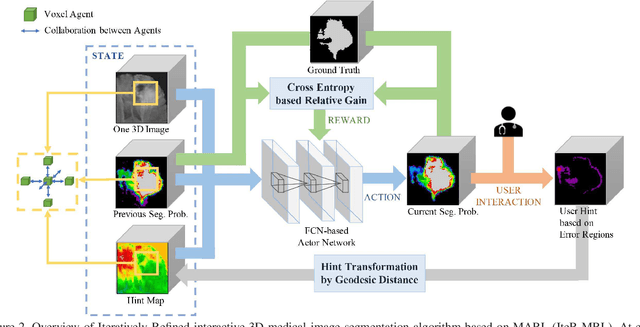
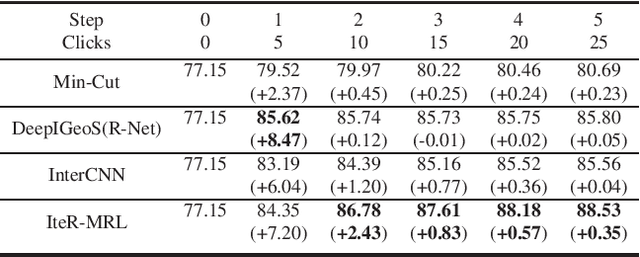
Existing automatic 3D image segmentation methods usually fail to meet the clinic use. Many studies have explored an interactive strategy to improve the image segmentation performance by iteratively incorporating user hints. However, the dynamic process for successive interactions is largely ignored. We here propose to model the dynamic process of iterative interactive image segmentation as a Markov decision process (MDP) and solve it with reinforcement learning (RL). Unfortunately, it is intractable to use single-agent RL for voxel-wise prediction due to the large exploration space. To reduce the exploration space to a tractable size, we treat each voxel as an agent with a shared voxel-level behavior strategy so that it can be solved with multi-agent reinforcement learning. An additional advantage of this multi-agent model is to capture the dependency among voxels for segmentation task. Meanwhile, to enrich the information of previous segmentations, we reserve the prediction uncertainty in the state space of MDP and derive an adjustment action space leading to a more precise and finer segmentation. In addition, to improve the efficiency of exploration, we design a relative cross-entropy gain-based reward to update the policy in a constrained direction. Experimental results on various medical datasets have shown that our method significantly outperforms existing state-of-the-art methods, with the advantage of fewer interactions and a faster convergence.