 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Learning for Perishable Inventory Systems with Human Knowledge
Jan 22, 2026Managing perishable products with limited lifetimes is a fundamental challenge in inventory management, as poor ordering decisions can quickly lead to stockouts or excessive waste. We study a perishable inventory system with random lead times in which both the demand process and the lead time distribution are unknown. We consider a practical setting where orders are placed using limited historical data together with observed covariates and current system states. To improve learning efficiency under limited data, we adopt a marginal cost accounting scheme that assigns each order a single lifetime cost and yields a unified loss function for end-to-end learning. This enables training a deep learning-based policy that maps observed covariates and system states directly to order quantities. We develop two end-to-end variants: a purely black-box approach that outputs order quantities directly (E2E-BB), and a structure-guided approach that embeds the projected inventory level (PIL) policy, capturing inventory effects through explicit computation rather than additional learning (E2E-PIL). We further show that the objective induced by E2E-PIL is homogeneous of degree one, enabling a boosting technique from operational data analytics (ODA) that yields an enhanced policy (E2E-BPIL). Experiments on synthetic and real data establish a robust performance ordering: E2E-BB is dominated by E2E-PIL, which is further improved by E2E-BPIL. Using an excess-risk decomposition, we show that embedding heuristic policy structure reduces effective model complexity and improves learning efficiency with only a modest loss of flexibility. More broadly, our results suggest that deep learning-based decision tools are more effective and robust when guided by human knowledge, highlighting the value of integrating advanced analytics with inventory theory.
A Novel Solution for Drone Photogrammetry with Low-overlap Aerial Images using Monocular Depth Estimation
Mar 06, 2025



Low-overlap aerial imagery poses significant challenges to traditional photogrammetric methods, which rely heavily on high image overlap to produce accurate and complete mapping products. In this study, we propose a novel workflow based on monocular depth estimation to address the limitations of conventional techniques. Our method leverages tie points obtained from aerial triangulation to establish a relationship between monocular depth and metric depth, thus transforming the original depth map into a metric depth map, enabling the generation of dense depth information and the comprehensive reconstruction of the scene. For the experiments, a high-overlap drone dataset containing 296 images is processed using Metashape to generate depth maps and DSMs as ground truth. Subsequently, we create a low-overlap dataset by selecting 20 images for experimental evaluation. Results demonstrate that while the recovered depth maps and resulting DSMs achieve meter-level accuracy, they provide significantly better completeness compared to traditional methods, particularly in regions covered by single images. This study showcases the potential of monocular depth estimation in low-overlap aerial photogrammetry.
Cutting-edge 3D reconstruction solutions for underwater coral reef images: A review and comparison
Feb 27, 2025Corals serve as the foundational habitat-building organisms within reef ecosystems, constructing extensive structures that extend over vast distances. However, their inherent fragility and vulnerability to various threats render them susceptible to significant damage and destruction. The application of advanced 3D reconstruction technologies for high-quality modeling is crucial for preserving them. These technologies help scientists to accurately document and monitor the state of coral reefs, including their structure, species distribution and changes over time. Photogrammetry-based approaches stand out among existing solutions, especially with recent advancements in underwater videography, photogrammetric computer vision, and machine learning. Despite continuous progress in image-based 3D reconstruction techniques, there remains a lack of systematic reviews and comprehensive evaluations of cutting-edge solutions specifically applied to underwater coral reef images. The emerging advanced methods may have difficulty coping with underwater imaging environments, complex coral structures, and computational resource constraints. They need to be reviewed and evaluated to bridge the gap between many cutting-edge technical studies and practical applications. This paper focuses on the two critical stages of these approaches: camera pose estimation and dense surface reconstruction. We systematically review and summarize classical and emerging methods, conducting comprehensive evaluations through real-world and simulated datasets. Based on our findings, we offer reference recommendations and discuss the development potential and challenges of existing approaches in depth. This work equips scientists and managers with a technical foundation and practical guidance for processing underwater coral reef images for 3D reconstruction....
Iteratively-Refined Interactive 3D Medical Image Segmentation with Multi-Agent Reinforcement Learning
Nov 23, 2019
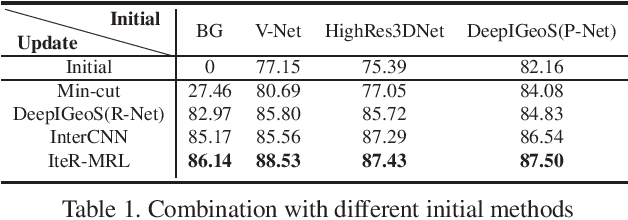
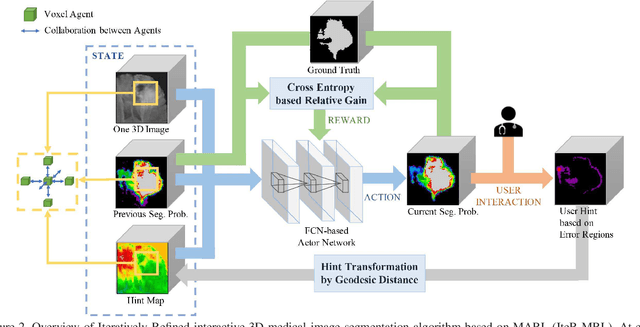
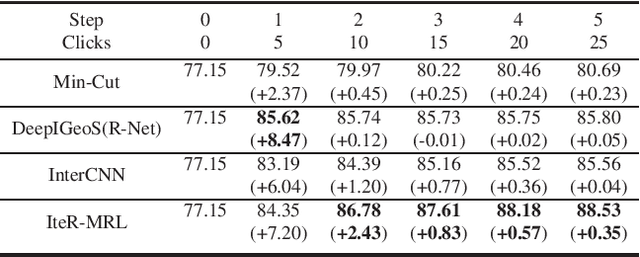
Existing automatic 3D image segmentation methods usually fail to meet the clinic use. Many studies have explored an interactive strategy to improve the image segmentation performance by iteratively incorporating user hints. However, the dynamic process for successive interactions is largely ignored. We here propose to model the dynamic process of iterative interactive image segmentation as a Markov decision process (MDP) and solve it with reinforcement learning (RL). Unfortunately, it is intractable to use single-agent RL for voxel-wise prediction due to the large exploration space. To reduce the exploration space to a tractable size, we treat each voxel as an agent with a shared voxel-level behavior strategy so that it can be solved with multi-agent reinforcement learning. An additional advantage of this multi-agent model is to capture the dependency among voxels for segmentation task. Meanwhile, to enrich the information of previous segmentations, we reserve the prediction uncertainty in the state space of MDP and derive an adjustment action space leading to a more precise and finer segmentation. In addition, to improve the efficiency of exploration, we design a relative cross-entropy gain-based reward to update the policy in a constrained direction. Experimental results on various medical datasets have shown that our method significantly outperforms existing state-of-the-art methods, with the advantage of fewer interactions and a faster convergence.