 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComplementary Information Mutual Learning for Multimodality Medical Image Segmentation
Jan 05, 2024



Radiologists must utilize multiple modal images for tumor segmentation and diagnosis due to the limitations of medical imaging and the diversity of tumor signals. This leads to the development of multimodal learning in segmentation. However, the redundancy among modalities creates challenges for existing subtraction-based joint learning methods, such as misjudging the importance of modalities, ignoring specific modal information, and increasing cognitive load. These thorny issues ultimately decrease segmentation accuracy and increase the risk of overfitting. This paper presents the complementary information mutual learning (CIML) framework, which can mathematically model and address the negative impact of inter-modal redundant information. CIML adopts the idea of addition and removes inter-modal redundant information through inductive bias-driven task decomposition and message passing-based redundancy filtering. CIML first decomposes the multimodal segmentation task into multiple subtasks based on expert prior knowledge, minimizing the information dependence between modalities. Furthermore, CIML introduces a scheme in which each modality can extract information from other modalities additively through message passing. To achieve non-redundancy of extracted information, the redundant filtering is transformed into complementary information learning inspired by the variational information bottleneck. The complementary information learning procedure can be efficiently solved by variational inference and cross-modal spatial attention. Numerical results from the verification task and standard benchmarks indicate that CIML efficiently removes redundant information between modalities, outperforming SOTA methods regarding validation accuracy and segmentation effect.
Interactive Medical Image Segmentation with Self-Adaptive Confidence Calibration
Nov 15, 2021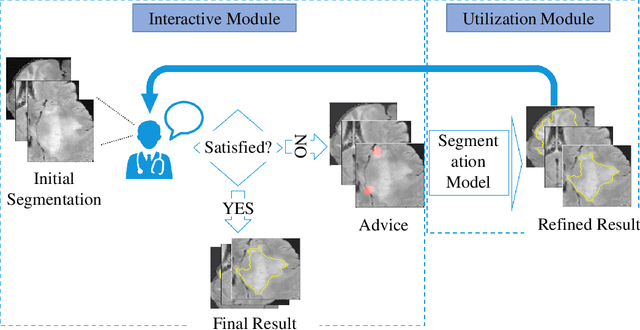
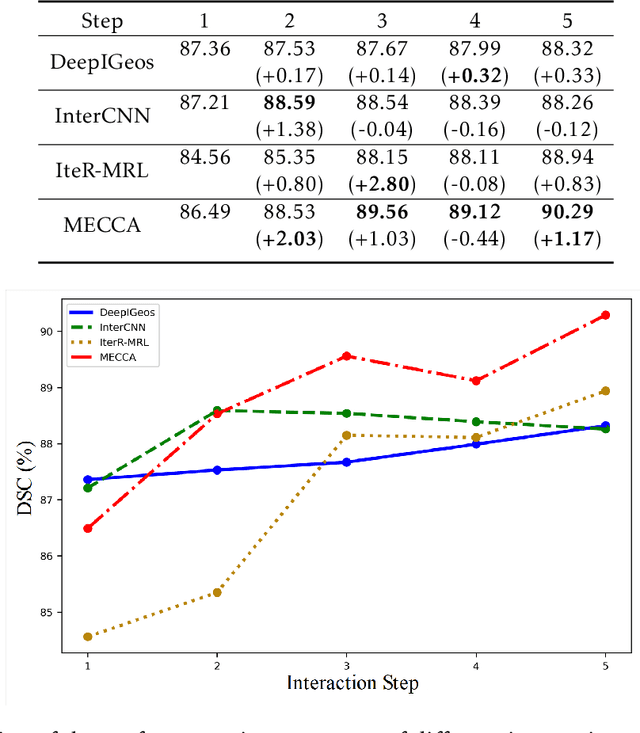
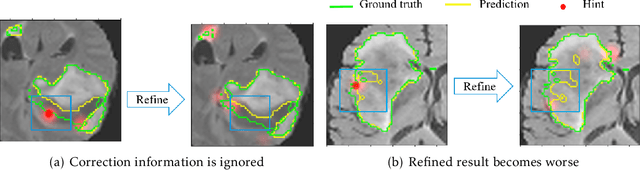

Medical image segmentation is one of the fundamental problems for artificial intelligence-based clinical decision systems. Current automatic medical image segmentation methods are often failed to meet clinical requirements. As such, a series of interactive segmentation algorithms are proposed to utilize expert correction information. However, existing methods suffer from some segmentation refining failure problems after long-term interactions and some cost problems from expert annotation, which hinder clinical applications. This paper proposes an interactive segmentation framework, called interactive MEdical segmentation with self-adaptive Confidence CAlibration (MECCA), by introducing the corrective action evaluation, which combines the action-based confidence learning and multi-agent reinforcement learning (MARL). The evaluation is established through a novel action-based confidence network, and the corrective actions are obtained from MARL. Based on the confidential information, a self-adaptive reward function is designed to provide more detailed feedback, and a simulated label generation mechanism is proposed on unsupervised data to reduce over-reliance on labeled data. Experimental results on various medical image datasets have shown the significant performance of the proposed algorithm.