 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpenRR-1k: A Scalable Dataset for Real-World Reflection Removal
Jun 10, 2025Reflection removal technology plays a crucial role in photography and computer vision applications. However, existing techniques are hindered by the lack of high-quality in-the-wild datasets. In this paper, we propose a novel paradigm for collecting reflection datasets from a fresh perspective. Our approach is convenient, cost-effective, and scalable, while ensuring that the collected data pairs are of high quality, perfectly aligned, and represent natural and diverse scenarios. Following this paradigm, we collect a Real-world, Diverse, and Pixel-aligned dataset (named OpenRR-1k dataset), which contains 1,000 high-quality transmission-reflection image pairs collected in the wild. Through the analysis of several reflection removal methods and benchmark evaluation experiments on our dataset, we demonstrate its effectiveness in improving robustness in challenging real-world environments. Our dataset is available at https://github.com/caijie0620/OpenRR-1k.
F2T2-HiT: A U-Shaped FFT Transformer and Hierarchical Transformer for Reflection Removal
Jun 05, 2025Single Image Reflection Removal (SIRR) technique plays a crucial role in image processing by eliminating unwanted reflections from the background. These reflections, often caused by photographs taken through glass surfaces, can significantly degrade image quality. SIRR remains a challenging problem due to the complex and varied reflections encountered in real-world scenarios. These reflections vary significantly in intensity, shapes, light sources, sizes, and coverage areas across the image, posing challenges for most existing methods to effectively handle all cases. To address these challenges, this paper introduces a U-shaped Fast Fourier Transform Transformer and Hierarchical Transformer (F2T2-HiT) architecture, an innovative Transformer-based design for SIRR. Our approach uniquely combines Fast Fourier Transform (FFT) Transformer blocks and Hierarchical Transformer blocks within a UNet framework. The FFT Transformer blocks leverage the global frequency domain information to effectively capture and separate reflection patterns, while the Hierarchical Transformer blocks utilize multi-scale feature extraction to handle reflections of varying sizes and complexities. Extensive experiments conducted on three publicly available testing datasets demonstrate state-of-the-art performance, validating the effectiveness of our approach.
TokenMotion: Decoupled Motion Control via Token Disentanglement for Human-centric Video Generation
Apr 11, 2025Human-centric motion control in video generation remains a critical challenge, particularly when jointly controlling camera movements and human poses in scenarios like the iconic Grammy Glambot moment. While recent video diffusion models have made significant progress, existing approaches struggle with limited motion representations and inadequate integration of camera and human motion controls. In this work, we present TokenMotion, the first DiT-based video diffusion framework that enables fine-grained control over camera motion, human motion, and their joint interaction. We represent camera trajectories and human poses as spatio-temporal tokens to enable local control granularity. Our approach introduces a unified modeling framework utilizing a decouple-and-fuse strategy, bridged by a human-aware dynamic mask that effectively handles the spatially-and-temporally varying nature of combined motion signals. Through extensive experiments, we demonstrate TokenMotion's effectiveness across both text-to-video and image-to-video paradigms, consistently outperforming current state-of-the-art methods in human-centric motion control tasks. Our work represents a significant advancement in controllable video generation, with particular relevance for creative production applications.
Survey on Single-Image Reflection Removal using Deep Learning Techniques
Feb 12, 2025The phenomenon of reflection is quite common in digital images, posing significant challenges for various applications such as computer vision, photography, and image processing. Traditional methods for reflection removal often struggle to achieve clean results while maintaining high fidelity and robustness, particularly in real-world scenarios. Over the past few decades, numerous deep learning-based approaches for reflection removal have emerged, yielding impressive results. In this survey, we conduct a comprehensive review of the current literature by focusing on key venues such as ICCV, ECCV, CVPR, NeurIPS, etc., as these conferences and journals have been central to advances in the field. Our review follows a structured paper selection process, and we critically assess both single-stage and two-stage deep learning methods for reflection removal. The contribution of this survey is three-fold: first, we provide a comprehensive summary of the most recent work on single-image reflection removal; second, we outline task hypotheses, current deep learning techniques, publicly available datasets, and relevant evaluation metrics; and third, we identify key challenges and opportunities in deep learning-based reflection removal, highlighting the potential of this rapidly evolving research area.
EVD4UAV: An Altitude-Sensitive Benchmark to Evade Vehicle Detection in UAV
Mar 08, 2024



Vehicle detection in Unmanned Aerial Vehicle (UAV) captured images has wide applications in aerial photography and remote sensing. There are many public benchmark datasets proposed for the vehicle detection and tracking in UAV images. Recent studies show that adding an adversarial patch on objects can fool the well-trained deep neural networks based object detectors, posing security concerns to the downstream tasks. However, the current public UAV datasets might ignore the diverse altitudes, vehicle attributes, fine-grained instance-level annotation in mostly side view with blurred vehicle roof, so none of them is good to study the adversarial patch based vehicle detection attack problem. In this paper, we propose a new dataset named EVD4UAV as an altitude-sensitive benchmark to evade vehicle detection in UAV with 6,284 images and 90,886 fine-grained annotated vehicles. The EVD4UAV dataset has diverse altitudes (50m, 70m, 90m), vehicle attributes (color, type), fine-grained annotation (horizontal and rotated bounding boxes, instance-level mask) in top view with clear vehicle roof. One white-box and two black-box patch based attack methods are implemented to attack three classic deep neural networks based object detectors on EVD4UAV. The experimental results show that these representative attack methods could not achieve the robust altitude-insensitive attack performance.
Defense against Adversarial Cloud Attack on Remote Sensing Salient Object Detection
Jul 05, 2023Detecting the salient objects in a remote sensing image has wide applications for the interdisciplinary research. Many existing deep learning methods have been proposed for Salient Object Detection (SOD) in remote sensing images and get remarkable results. However, the recent adversarial attack examples, generated by changing a few pixel values on the original remote sensing image, could result in a collapse for the well-trained deep learning based SOD model. Different with existing methods adding perturbation to original images, we propose to jointly tune adversarial exposure and additive perturbation for attack and constrain image close to cloudy image as Adversarial Cloud. Cloud is natural and common in remote sensing images, however, camouflaging cloud based adversarial attack and defense for remote sensing images are not well studied before. Furthermore, we design DefenseNet as a learn-able pre-processing to the adversarial cloudy images so as to preserve the performance of the deep learning based remote sensing SOD model, without tuning the already deployed deep SOD model. By considering both regular and generalized adversarial examples, the proposed DefenseNet can defend the proposed Adversarial Cloud in white-box setting and other attack methods in black-box setting. Experimental results on a synthesized benchmark from the public remote sensing SOD dataset (EORSSD) show the promising defense against adversarial cloud attacks.
Deep Transfer Learning for Intelligent Vehicle Perception: a Survey
Jun 26, 2023



Deep learning-based intelligent vehicle perception has been developing prominently in recent years to provide a reliable source for motion planning and decision making in autonomous driving. A large number of powerful deep learning-based methods can achieve excellent performance in solving various perception problems of autonomous driving. However, these deep learning methods still have several limitations, for example, the assumption that lab-training (source domain) and real-testing (target domain) data follow the same feature distribution may not be practical in the real world. There is often a dramatic domain gap between them in many real-world cases. As a solution to this challenge, deep transfer learning can handle situations excellently by transferring the knowledge from one domain to another. Deep transfer learning aims to improve task performance in a new domain by leveraging the knowledge of similar tasks learned in another domain before. Nevertheless, there are currently no survey papers on the topic of deep transfer learning for intelligent vehicle perception. To the best of our knowledge, this paper represents the first comprehensive survey on the topic of the deep transfer learning for intelligent vehicle perception. This paper discusses the domain gaps related to the differences of sensor, data, and model for the intelligent vehicle perception. The recent applications, challenges, future researches in intelligent vehicle perception are also explored.
Coarse-to-fine Task-driven Inpainting for Geoscience Images
Dec 06, 2022



The processing and recognition of geoscience images have wide applications. Most of existing researches focus on understanding the high-quality geoscience images by assuming that all the images are clear. However, in many real-world cases, the geoscience images might contain occlusions during the image acquisition. This problem actually implies the image inpainting problem in computer vision and multimedia. To the best of our knowledge, all the existing image inpainting algorithms learn to repair the occluded regions for a better visualization quality, they are excellent for natural images but not good enough for geoscience images by ignoring the geoscience related tasks. This paper aims to repair the occluded regions for a better geoscience task performance with the advanced visualization quality simultaneously, without changing the current deployed deep learning based geoscience models. Because of the complex context of geoscience images, we propose a coarse-to-fine encoder-decoder network with coarse-to-fine adversarial context discriminators to reconstruct the occluded image regions. Due to the limited data of geoscience images, we use a MaskMix based data augmentation method to exploit more information from limited geoscience image data. The experimental results on three public geoscience datasets for remote sensing scene recognition, cross-view geolocation and semantic segmentation tasks respectively show the effectiveness and accuracy of the proposed method.
Variational Information Bottleneck for Effective Low-resource Audio Classification
Jul 10, 2021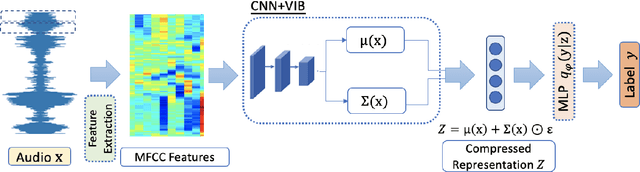
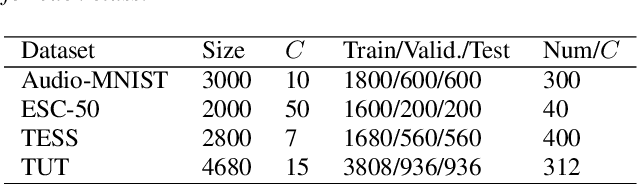

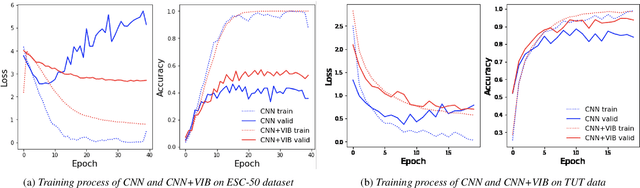
Large-scale deep neural networks (DNNs) such as convolutional neural networks (CNNs) have achieved impressive performance in audio classification for their powerful capacity and strong generalization ability. However, when training a DNN model on low-resource tasks, it is usually prone to overfitting the small data and learning too much redundant information. To address this issue, we propose to use variational information bottleneck (VIB) to mitigate overfitting and suppress irrelevant information. In this work, we conduct experiments ona 4-layer CNN. However, the VIB framework is ready-to-use and could be easily utilized with many other state-of-the-art network architectures. Evaluation on a few audio datasets shows that our approach significantly outperforms baseline methods, yielding more than 5.0% improvement in terms of classification accuracy in some low-source settings.