 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTokenMotion: Decoupled Motion Control via Token Disentanglement for Human-centric Video Generation
Apr 11, 2025Human-centric motion control in video generation remains a critical challenge, particularly when jointly controlling camera movements and human poses in scenarios like the iconic Grammy Glambot moment. While recent video diffusion models have made significant progress, existing approaches struggle with limited motion representations and inadequate integration of camera and human motion controls. In this work, we present TokenMotion, the first DiT-based video diffusion framework that enables fine-grained control over camera motion, human motion, and their joint interaction. We represent camera trajectories and human poses as spatio-temporal tokens to enable local control granularity. Our approach introduces a unified modeling framework utilizing a decouple-and-fuse strategy, bridged by a human-aware dynamic mask that effectively handles the spatially-and-temporally varying nature of combined motion signals. Through extensive experiments, we demonstrate TokenMotion's effectiveness across both text-to-video and image-to-video paradigms, consistently outperforming current state-of-the-art methods in human-centric motion control tasks. Our work represents a significant advancement in controllable video generation, with particular relevance for creative production applications.
ROIFormer: Semantic-Aware Region of Interest Transformer for Efficient Self-Supervised Monocular Depth Estimation
Dec 16, 2022The exploration of mutual-benefit cross-domains has shown great potential toward accurate self-supervised depth estimation. In this work, we revisit feature fusion between depth and semantic information and propose an efficient local adaptive attention method for geometric aware representation enhancement. Instead of building global connections or deforming attention across the feature space without restraint, we bound the spatial interaction within a learnable region of interest. In particular, we leverage geometric cues from semantic information to learn local adaptive bounding boxes to guide unsupervised feature aggregation. The local areas preclude most irrelevant reference points from attention space, yielding more selective feature learning and faster convergence. We naturally extend the paradigm into a multi-head and hierarchic way to enable the information distillation in different semantic levels and improve the feature discriminative ability for fine-grained depth estimation. Extensive experiments on the KITTI dataset show that our proposed method establishes a new state-of-the-art in self-supervised monocular depth estimation task, demonstrating the effectiveness of our approach over former Transformer variants.
1st Workshop on Maritime Computer Vision 2023: Challenge Results
Nov 28, 2022

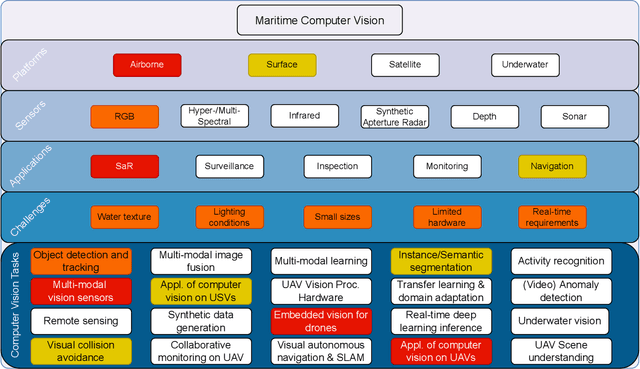
The 1$^{\text{st}}$ Workshop on Maritime Computer Vision (MaCVi) 2023 focused on maritime computer vision for Unmanned Aerial Vehicles (UAV) and Unmanned Surface Vehicle (USV), and organized several subchallenges in this domain: (i) UAV-based Maritime Object Detection, (ii) UAV-based Maritime Object Tracking, (iii) USV-based Maritime Obstacle Segmentation and (iv) USV-based Maritime Obstacle Detection. The subchallenges were based on the SeaDronesSee and MODS benchmarks. This report summarizes the main findings of the individual subchallenges and introduces a new benchmark, called SeaDronesSee Object Detection v2, which extends the previous benchmark by including more classes and footage. We provide statistical and qualitative analyses, and assess trends in the best-performing methodologies of over 130 submissions. The methods are summarized in the appendix. The datasets, evaluation code and the leaderboard are publicly available at https://seadronessee.cs.uni-tuebingen.de/macvi.
Siamese Transformer Pyramid Networks for Real-Time UAV Tracking
Oct 17, 2021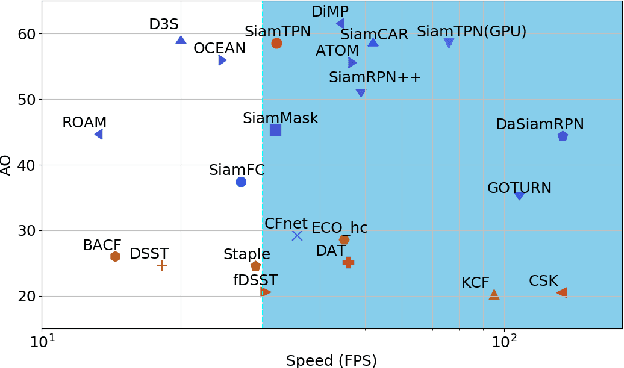



Recent object tracking methods depend upon deep networks or convoluted architectures. Most of those trackers can hardly meet real-time processing requirements on mobile platforms with limited computing resources. In this work, we introduce the Siamese Transformer Pyramid Network (SiamTPN), which inherits the advantages from both CNN and Transformer architectures. Specifically, we exploit the inherent feature pyramid of a lightweight network (ShuffleNetV2) and reinforce it with a Transformer to construct a robust target-specific appearance model. A centralized architecture with lateral cross attention is developed for building augmented high-level feature maps. To avoid the computation and memory intensity while fusing pyramid representations with the Transformer, we further introduce the pooling attention module, which significantly reduces memory and time complexity while improving the robustness. Comprehensive experiments on both aerial and prevalent tracking benchmarks achieve competitive results while operating at high speed, demonstrating the effectiveness of SiamTPN. Moreover, our fastest variant tracker operates over 30 Hz on a single CPU-core and obtaining an AUC score of 58.1% on the LaSOT dataset. Source codes are available at https://github.com/RISCNYUAD/SiamTPNTracker
ArbiText: Arbitrary-Oriented Text Detection in Unconstrained Scene
Nov 30, 2017

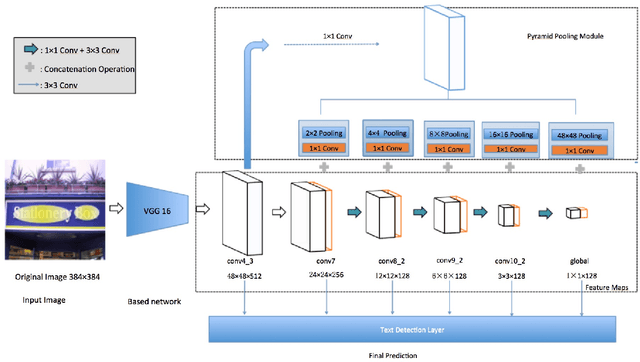
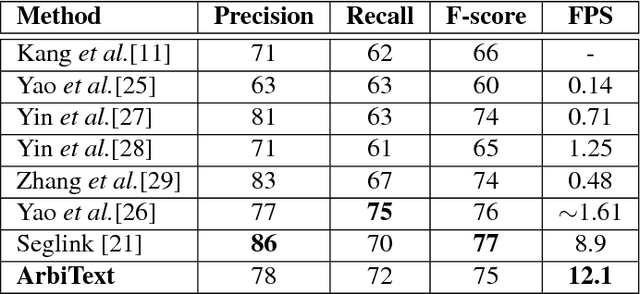
Arbitrary-oriented text detection in the wild is a very challenging task, due to the aspect ratio, scale, orientation, and illumination variations. In this paper, we propose a novel method, namely Arbitrary-oriented Text (or ArbText for short) detector, for efficient text detection in unconstrained natural scene images. Specifically, we first adopt the circle anchors rather than the rectangular ones to represent bounding boxes, which is more robust to orientation variations. Subsequently, we incorporate a pyramid pooling module into the Single Shot MultiBox Detector framework, in order to simultaneously explore the local and global visual information, which can, therefore, generate more confidential detection results. Experiments on established scene-text datasets, such as the ICDAR 2015 and MSRA-TD500 datasets, have demonstrated the supe rior performance of the proposed method, compared to the state-of-the-art approaches.