 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReal-time Face Mask Detection in Video Data
May 05, 2021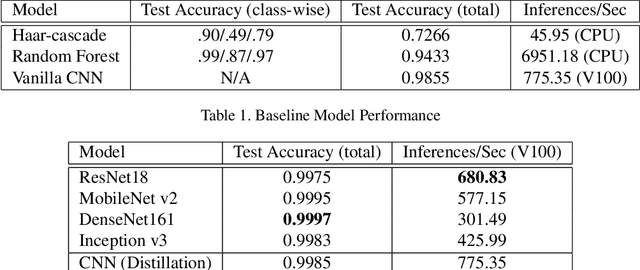
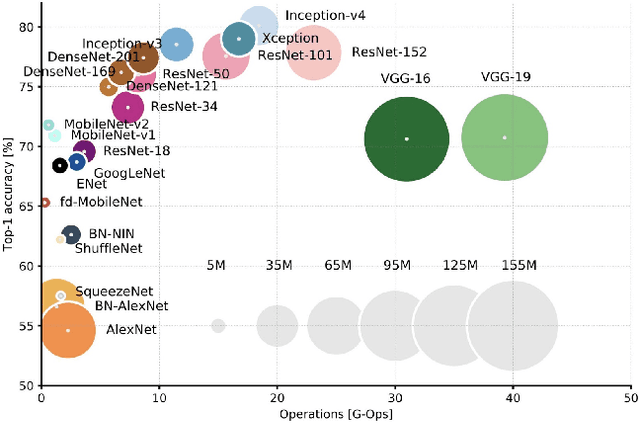
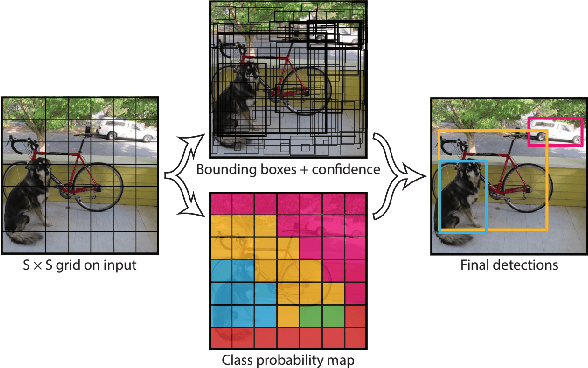
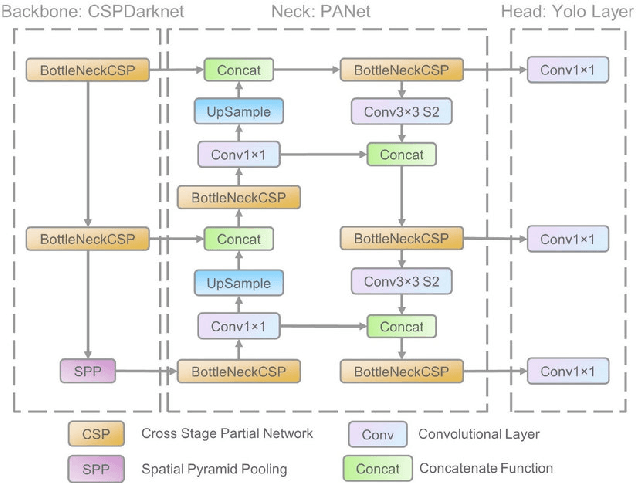
In response to the ongoing COVID-19 pandemic, we present a robust deep learning pipeline that is capable of identifying correct and incorrect mask-wearing from real-time video streams. To accomplish this goal, we devised two separate approaches and evaluated their performance and run-time efficiency. The first approach leverages a pre-trained face detector in combination with a mask-wearing image classifier trained on a large-scale synthetic dataset. The second approach utilizes a state-of-the-art object detection network to perform localization and classification of faces in one shot, fine-tuned on a small set of labeled real-world images. The first pipeline achieved a test accuracy of 99.97% on the synthetic dataset and maintained 6 FPS running on video data. The second pipeline achieved a mAP(0.5) of 89% on real-world images while sustaining 52 FPS on video data. We have concluded that if a larger dataset with bounding-box labels can be curated, this task is best suited using object detection architectures such as YOLO and SSD due to their superior inference speed and satisfactory performance on key evaluation metrics.
Lane Boundary Geometry Extraction from Satellite Imagery
Feb 06, 2020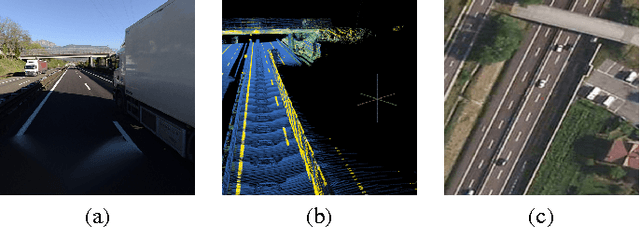



Autonomous driving car is becoming more of a reality, as a key component,high-definition(HD) maps shows its value in both market place and industry. Even though HD maps generation from LiDAR or stereo/perspective imagery has achieved impressive success, its inherent defects cannot be ignored. In this paper, we proposal a novel method for Highway HD maps modeling using pixel-wise segmentation on satellite imagery and formalized hypotheses linking, which is cheaper and faster than current HD maps modeling approaches from LiDAR point cloud and perspective view imagery, and let it becomes an ideal complementary of state of the art. We also manual code/label an HD road model dataset as ground truth, aligned with Bing tile image server, to train, test and evaluate our methodology. This dataset will be publish at same time to contribute research in HD maps modeling from aerial imagery.
ArbiText: Arbitrary-Oriented Text Detection in Unconstrained Scene
Nov 30, 2017

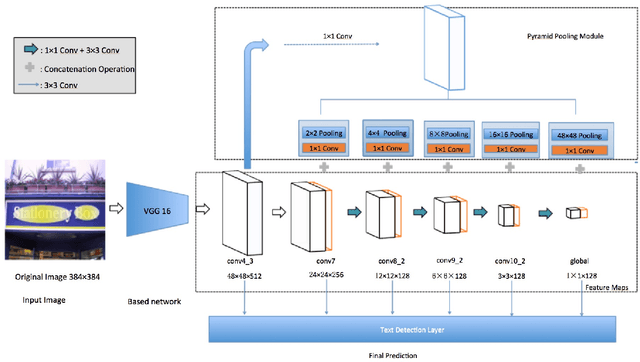
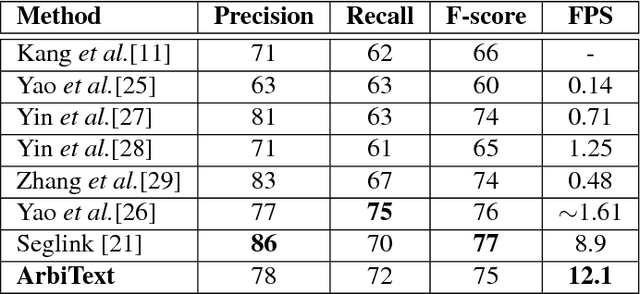
Arbitrary-oriented text detection in the wild is a very challenging task, due to the aspect ratio, scale, orientation, and illumination variations. In this paper, we propose a novel method, namely Arbitrary-oriented Text (or ArbText for short) detector, for efficient text detection in unconstrained natural scene images. Specifically, we first adopt the circle anchors rather than the rectangular ones to represent bounding boxes, which is more robust to orientation variations. Subsequently, we incorporate a pyramid pooling module into the Single Shot MultiBox Detector framework, in order to simultaneously explore the local and global visual information, which can, therefore, generate more confidential detection results. Experiments on established scene-text datasets, such as the ICDAR 2015 and MSRA-TD500 datasets, have demonstrated the supe rior performance of the proposed method, compared to the state-of-the-art approaches.