 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePose Guided Human Image Synthesis with Partially Decoupled GAN
Oct 07, 2022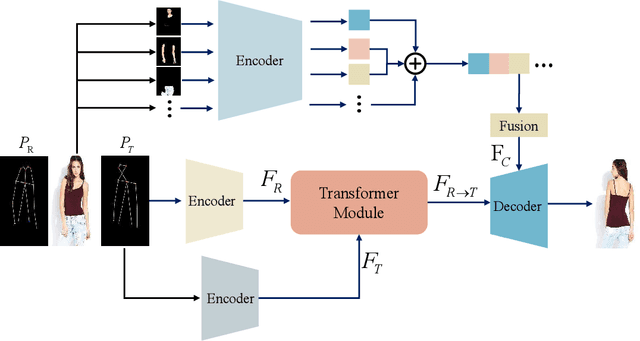
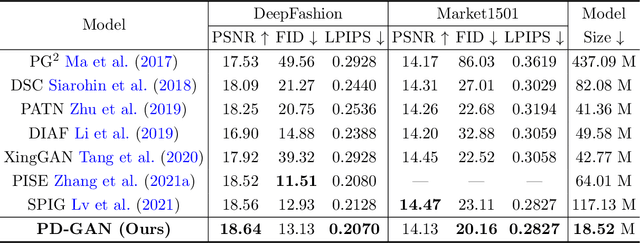

Pose Guided Human Image Synthesis (PGHIS) is a challenging task of transforming a human image from the reference pose to a target pose while preserving its style. Most existing methods encode the texture of the whole reference human image into a latent space, and then utilize a decoder to synthesize the image texture of the target pose. However, it is difficult to recover the detailed texture of the whole human image. To alleviate this problem, we propose a method by decoupling the human body into several parts (\eg, hair, face, hands, feet, \etc) and then using each of these parts to guide the synthesis of a realistic image of the person, which preserves the detailed information of the generated images. In addition, we design a multi-head attention-based module for PGHIS. Because most convolutional neural network-based methods have difficulty in modeling long-range dependency due to the convolutional operation, the long-range modeling capability of attention mechanism is more suitable than convolutional neural networks for pose transfer task, especially for sharp pose deformation. Extensive experiments on Market-1501 and DeepFashion datasets reveal that our method almost outperforms other existing state-of-the-art methods in terms of both qualitative and quantitative metrics.
Improving Human Image Synthesis with Residual Fast Fourier Transformation and Wasserstein Distance
May 26, 2022
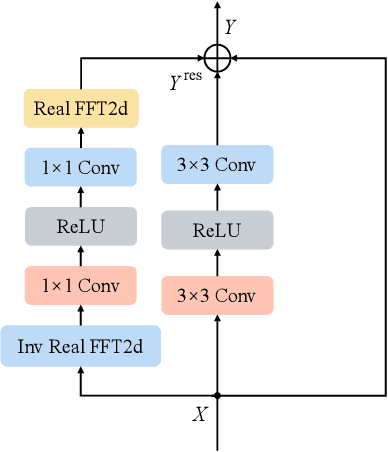
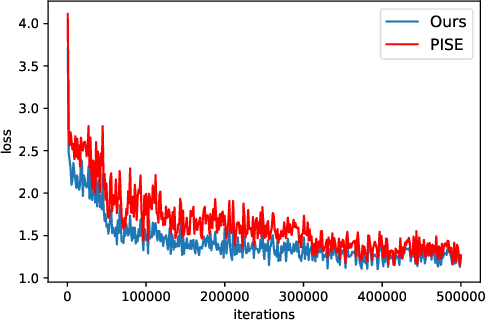

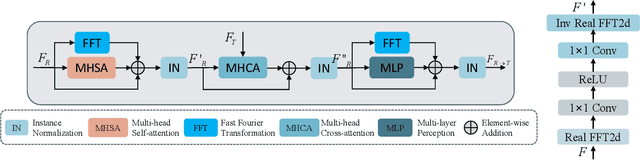
With the rapid development of the Metaverse, virtual humans have emerged, and human image synthesis and editing techniques, such as pose transfer, have recently become popular. Most of the existing techniques rely on GANs, which can generate good human images even with large variants and occlusions. But from our best knowledge, the existing state-of-the-art method still has the following problems: the first is that the rendering effect of the synthetic image is not realistic, such as poor rendering of some regions. And the second is that the training of GAN is unstable and slow to converge, such as model collapse. Based on the above two problems, we propose several methods to solve them. To improve the rendering effect, we use the Residual Fast Fourier Transform Block to replace the traditional Residual Block. Then, spectral normalization and Wasserstein distance are used to improve the speed and stability of GAN training. Experiments demonstrate that the methods we offer are effective at solving the problems listed above, and we get state-of-the-art scores in LPIPS and PSNR.
Augmentation-induced Consistency Regularization for Classification
May 26, 2022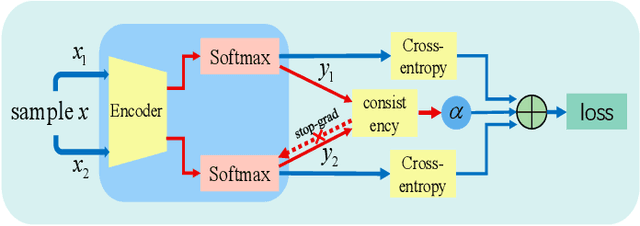
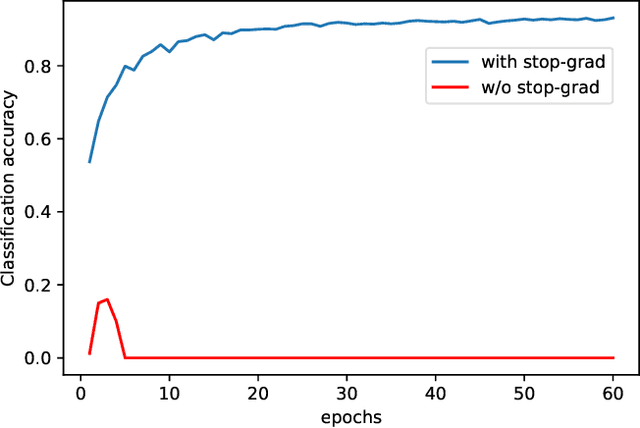
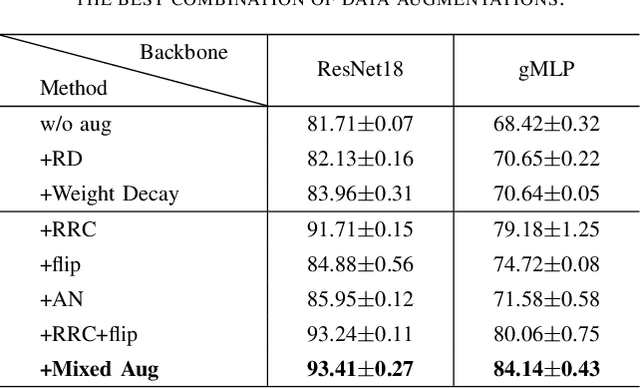
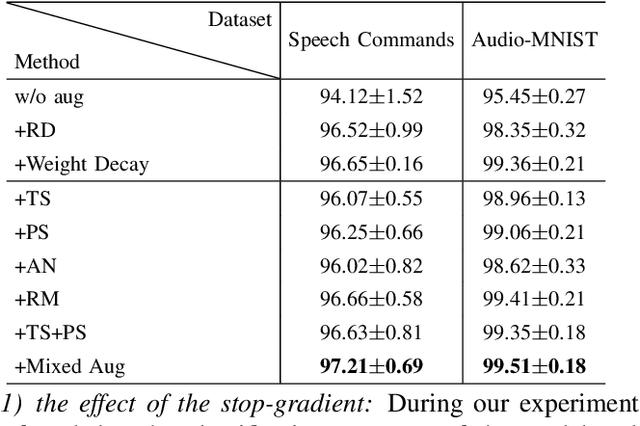
Deep neural networks have become popular in many supervised learning tasks, but they may suffer from overfitting when the training dataset is limited. To mitigate this, many researchers use data augmentation, which is a widely used and effective method for increasing the variety of datasets. However, the randomness introduced by data augmentation causes inevitable inconsistency between training and inference, which leads to poor improvement. In this paper, we propose a consistency regularization framework based on data augmentation, called CR-Aug, which forces the output distributions of different sub models generated by data augmentation to be consistent with each other. Specifically, CR-Aug evaluates the discrepancy between the output distributions of two augmented versions of each sample, and it utilizes a stop-gradient operation to minimize the consistency loss. We implement CR-Aug to image and audio classification tasks and conduct extensive experiments to verify its effectiveness in improving the generalization ability of classifiers. Our CR-Aug framework is ready-to-use, it can be easily adapted to many state-of-the-art network architectures. Our empirical results show that CR-Aug outperforms baseline methods by a significant margin.
Variational Information Bottleneck for Effective Low-resource Audio Classification
Jul 10, 2021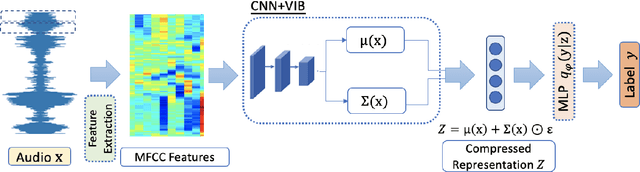
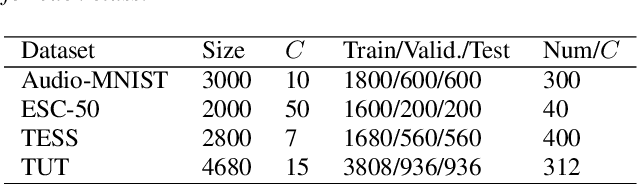

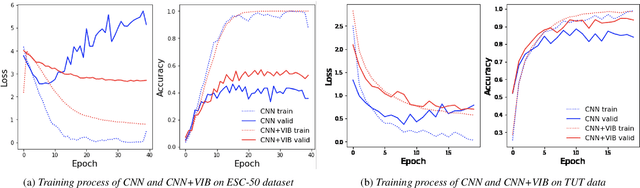
Large-scale deep neural networks (DNNs) such as convolutional neural networks (CNNs) have achieved impressive performance in audio classification for their powerful capacity and strong generalization ability. However, when training a DNN model on low-resource tasks, it is usually prone to overfitting the small data and learning too much redundant information. To address this issue, we propose to use variational information bottleneck (VIB) to mitigate overfitting and suppress irrelevant information. In this work, we conduct experiments ona 4-layer CNN. However, the VIB framework is ready-to-use and could be easily utilized with many other state-of-the-art network architectures. Evaluation on a few audio datasets shows that our approach significantly outperforms baseline methods, yielding more than 5.0% improvement in terms of classification accuracy in some low-source settings.