 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePose Guided Human Image Synthesis with Partially Decoupled GAN
Paper and Code
Oct 07, 2022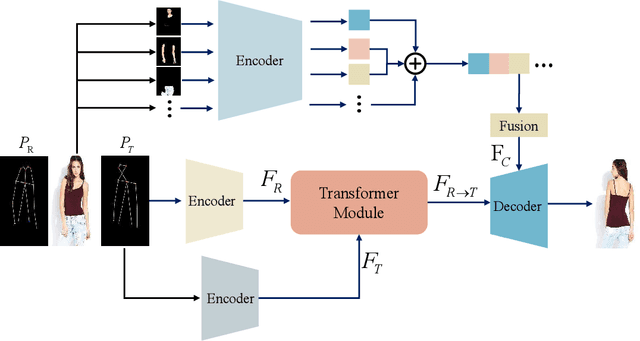
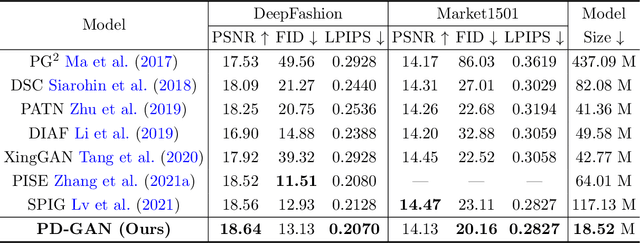
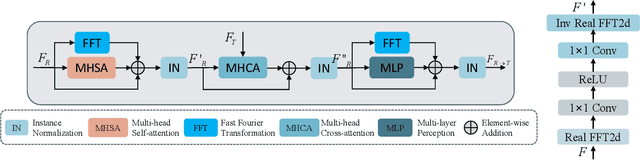

Pose Guided Human Image Synthesis (PGHIS) is a challenging task of transforming a human image from the reference pose to a target pose while preserving its style. Most existing methods encode the texture of the whole reference human image into a latent space, and then utilize a decoder to synthesize the image texture of the target pose. However, it is difficult to recover the detailed texture of the whole human image. To alleviate this problem, we propose a method by decoupling the human body into several parts (\eg, hair, face, hands, feet, \etc) and then using each of these parts to guide the synthesis of a realistic image of the person, which preserves the detailed information of the generated images. In addition, we design a multi-head attention-based module for PGHIS. Because most convolutional neural network-based methods have difficulty in modeling long-range dependency due to the convolutional operation, the long-range modeling capability of attention mechanism is more suitable than convolutional neural networks for pose transfer task, especially for sharp pose deformation. Extensive experiments on Market-1501 and DeepFashion datasets reveal that our method almost outperforms other existing state-of-the-art methods in terms of both qualitative and quantitative metrics.