 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGrabDAE: An Innovative Framework for Unsupervised Domain Adaptation Utilizing Grab-Mask and Denoise Auto-Encoder
Oct 10, 2024Unsupervised Domain Adaptation (UDA) aims to adapt a model trained on a labeled source domain to an unlabeled target domain by addressing the domain shift. Existing Unsupervised Domain Adaptation (UDA) methods often fall short in fully leveraging contextual information from the target domain, leading to suboptimal decision boundary separation during source and target domain alignment. To address this, we introduce GrabDAE, an innovative UDA framework designed to tackle domain shift in visual classification tasks. GrabDAE incorporates two key innovations: the Grab-Mask module, which blurs background information in target domain images, enabling the model to focus on essential, domain-relevant features through contrastive learning; and the Denoising Auto-Encoder (DAE), which enhances feature alignment by reconstructing features and filtering noise, ensuring a more robust adaptation to the target domain. These components empower GrabDAE to effectively handle unlabeled target domain data, significantly improving both classification accuracy and robustness. Extensive experiments on benchmark datasets, including VisDA-2017, Office-Home, and Office31, demonstrate that GrabDAE consistently surpasses state-of-the-art UDA methods, setting new performance benchmarks. By tackling UDA's critical challenges with its novel feature masking and denoising approach, GrabDAE offers both significant theoretical and practical advancements in domain adaptation.
VehicleGAN: Pair-flexible Pose Guided Image Synthesis for Vehicle Re-identification
Nov 27, 2023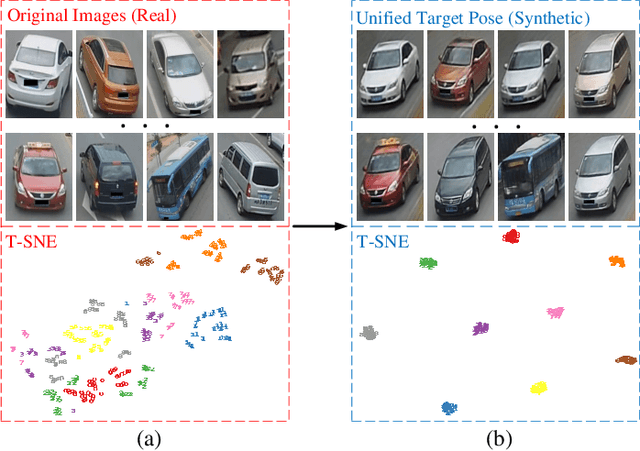
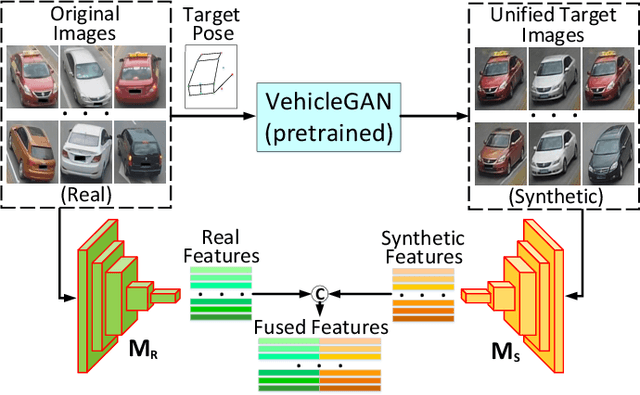
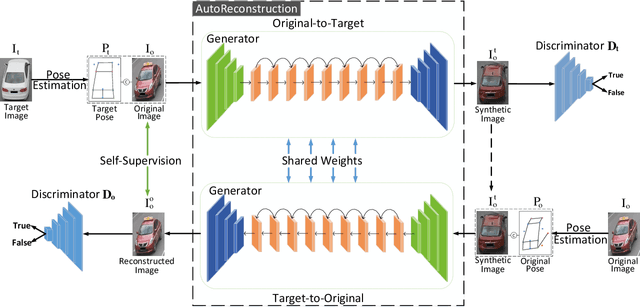
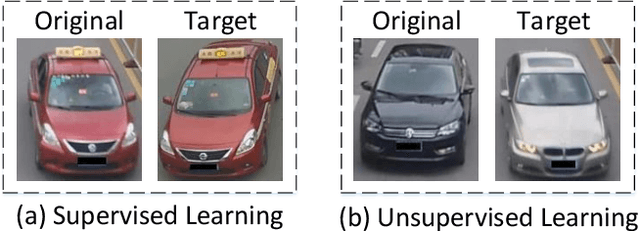
Vehicle Re-identification (Re-ID) has been broadly studied in the last decade; however, the different camera view angle leading to confused discrimination in the feature subspace for the vehicles of various poses, is still challenging for the Vehicle Re-ID models in the real world. To promote the Vehicle Re-ID models, this paper proposes to synthesize a large number of vehicle images in the target pose, whose idea is to project the vehicles of diverse poses into the unified target pose so as to enhance feature discrimination. Considering that the paired data of the same vehicles in different traffic surveillance cameras might be not available in the real world, we propose the first Pair-flexible Pose Guided Image Synthesis method for Vehicle Re-ID, named as VehicleGAN in this paper, which works for both supervised and unsupervised settings without the knowledge of geometric 3D models. Because of the feature distribution difference between real and synthetic data, simply training a traditional metric learning based Re-ID model with data-level fusion (i.e., data augmentation) is not satisfactory, therefore we propose a new Joint Metric Learning (JML) via effective feature-level fusion from both real and synthetic data. Intensive experimental results on the public VeRi-776 and VehicleID datasets prove the accuracy and effectiveness of our proposed VehicleGAN and JML.
Deep Transfer Learning for Intelligent Vehicle Perception: a Survey
Jun 26, 2023



Deep learning-based intelligent vehicle perception has been developing prominently in recent years to provide a reliable source for motion planning and decision making in autonomous driving. A large number of powerful deep learning-based methods can achieve excellent performance in solving various perception problems of autonomous driving. However, these deep learning methods still have several limitations, for example, the assumption that lab-training (source domain) and real-testing (target domain) data follow the same feature distribution may not be practical in the real world. There is often a dramatic domain gap between them in many real-world cases. As a solution to this challenge, deep transfer learning can handle situations excellently by transferring the knowledge from one domain to another. Deep transfer learning aims to improve task performance in a new domain by leveraging the knowledge of similar tasks learned in another domain before. Nevertheless, there are currently no survey papers on the topic of deep transfer learning for intelligent vehicle perception. To the best of our knowledge, this paper represents the first comprehensive survey on the topic of the deep transfer learning for intelligent vehicle perception. This paper discusses the domain gaps related to the differences of sensor, data, and model for the intelligent vehicle perception. The recent applications, challenges, future researches in intelligent vehicle perception are also explored.