 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStep-GUI Technical Report
Dec 19, 2025



Recent advances in multimodal large language models unlock unprecedented opportunities for GUI automation. However, a fundamental challenge remains: how to efficiently acquire high-quality training data while maintaining annotation reliability? We introduce a self-evolving training pipeline powered by the Calibrated Step Reward System, which converts model-generated trajectories into reliable training signals through trajectory-level calibration, achieving >90% annotation accuracy with 10-100x lower cost. Leveraging this pipeline, we introduce Step-GUI, a family of models (4B/8B) that achieves state-of-the-art GUI performance (8B: 80.2% AndroidWorld, 48.5% OSWorld, 62.6% ScreenShot-Pro) while maintaining robust general capabilities. As GUI agent capabilities improve, practical deployment demands standardized interfaces across heterogeneous devices while protecting user privacy. To this end, we propose GUI-MCP, the first Model Context Protocol for GUI automation with hierarchical architecture that combines low-level atomic operations and high-level task delegation to local specialist models, enabling high-privacy execution where sensitive data stays on-device. Finally, to assess whether agents can handle authentic everyday usage, we introduce AndroidDaily, a benchmark grounded in real-world mobile usage patterns with 3146 static actions and 235 end-to-end tasks across high-frequency daily scenarios (8B: static 89.91%, end-to-end 52.50%). Our work advances the development of practical GUI agents and demonstrates strong potential for real-world deployment in everyday digital interactions.
Step-Audio 2 Technical Report
Jul 24, 2025



This paper presents Step-Audio 2, an end-to-end multi-modal large language model designed for industry-strength audio understanding and speech conversation. By integrating a latent audio encoder and reasoning-centric reinforcement learning (RL), Step-Audio 2 achieves promising performance in automatic speech recognition (ASR) and audio understanding. To facilitate genuine end-to-end speech conversation, Step-Audio 2 incorporates the generation of discrete audio tokens into language modeling, significantly enhancing its responsiveness to paralinguistic information such as speaking styles and emotions. To effectively leverage the rich textual and acoustic knowledge in real-world data, Step-Audio 2 integrates retrieval-augmented generation (RAG) and is able to call external tools such as web search to mitigate hallucination and audio search to switch timbres. Trained on millions of hours of speech and audio data, Step-Audio 2 delivers intelligence and expressiveness across diverse conversational scenarios. Evaluation results demonstrate that Step-Audio 2 achieves state-of-the-art performance on various audio understanding and conversational benchmarks compared to other open-source and commercial solutions. Please visit https://github.com/stepfun-ai/Step-Audio2 for more information.
Step-Audio: Unified Understanding and Generation in Intelligent Speech Interaction
Feb 18, 2025Real-time speech interaction, serving as a fundamental interface for human-machine collaboration, holds immense potential. However, current open-source models face limitations such as high costs in voice data collection, weakness in dynamic control, and limited intelligence. To address these challenges, this paper introduces Step-Audio, the first production-ready open-source solution. Key contributions include: 1) a 130B-parameter unified speech-text multi-modal model that achieves unified understanding and generation, with the Step-Audio-Chat version open-sourced; 2) a generative speech data engine that establishes an affordable voice cloning framework and produces the open-sourced lightweight Step-Audio-TTS-3B model through distillation; 3) an instruction-driven fine control system enabling dynamic adjustments across dialects, emotions, singing, and RAP; 4) an enhanced cognitive architecture augmented with tool calling and role-playing abilities to manage complex tasks effectively. Based on our new StepEval-Audio-360 evaluation benchmark, Step-Audio achieves state-of-the-art performance in human evaluations, especially in terms of instruction following. On open-source benchmarks like LLaMA Question, shows 9.3% average performance improvement, demonstrating our commitment to advancing the development of open-source multi-modal language technologies. Our code and models are available at https://github.com/stepfun-ai/Step-Audio.
GrabDAE: An Innovative Framework for Unsupervised Domain Adaptation Utilizing Grab-Mask and Denoise Auto-Encoder
Oct 10, 2024Unsupervised Domain Adaptation (UDA) aims to adapt a model trained on a labeled source domain to an unlabeled target domain by addressing the domain shift. Existing Unsupervised Domain Adaptation (UDA) methods often fall short in fully leveraging contextual information from the target domain, leading to suboptimal decision boundary separation during source and target domain alignment. To address this, we introduce GrabDAE, an innovative UDA framework designed to tackle domain shift in visual classification tasks. GrabDAE incorporates two key innovations: the Grab-Mask module, which blurs background information in target domain images, enabling the model to focus on essential, domain-relevant features through contrastive learning; and the Denoising Auto-Encoder (DAE), which enhances feature alignment by reconstructing features and filtering noise, ensuring a more robust adaptation to the target domain. These components empower GrabDAE to effectively handle unlabeled target domain data, significantly improving both classification accuracy and robustness. Extensive experiments on benchmark datasets, including VisDA-2017, Office-Home, and Office31, demonstrate that GrabDAE consistently surpasses state-of-the-art UDA methods, setting new performance benchmarks. By tackling UDA's critical challenges with its novel feature masking and denoising approach, GrabDAE offers both significant theoretical and practical advancements in domain adaptation.
Multiple EffNet/ResNet Architectures for Melanoma Classification
Apr 21, 2022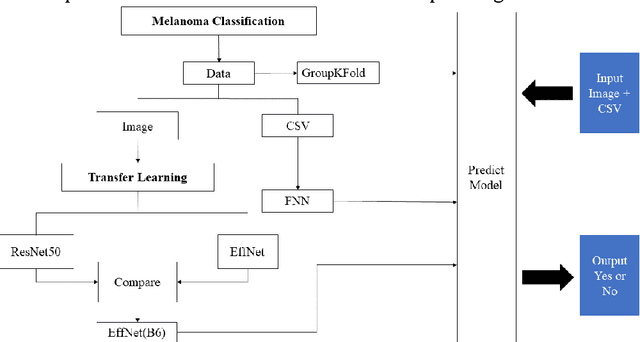

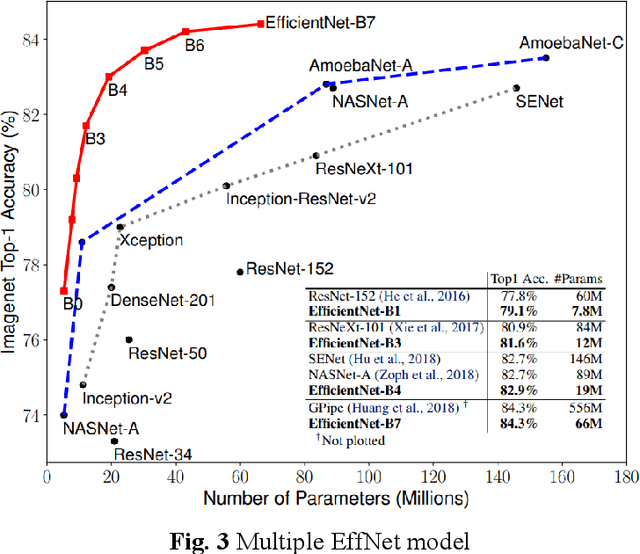
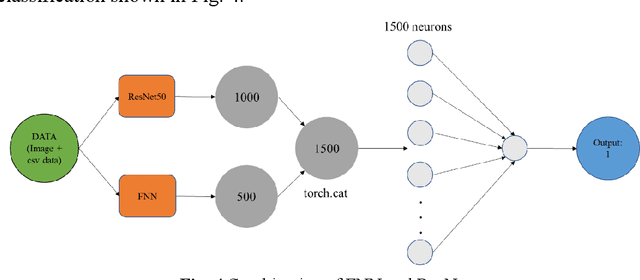
Melanoma is the most malignant skin tumor and usually cancerates from normal moles, which is difficult to distinguish benign from malignant in the early stage. Therefore, many machine learning methods are trying to make auxiliary prediction. However, these methods attach more attention to the image data of suspected tumor, and focus on improving the accuracy of image classification, but ignore the significance of patient-level contextual information for disease diagnosis in actual clinical diagnosis. To make more use of patient information and improve the accuracy of diagnosis, we propose a new melanoma classification model based on EffNet and Resnet. Our model not only uses images within the same patient but also consider patient-level contextual information for better cancer prediction. The experimental results demonstrated that the proposed model achieved 0.981 ACC. Furthermore, we note that the overall ROC value of the model is 0.976 which is better than the previous state-of-the-art approaches.
* 16 pages,20 figures
Actor-Action Video Classification CSC 249/449 Spring 2020 Challenge Report
Aug 18, 2020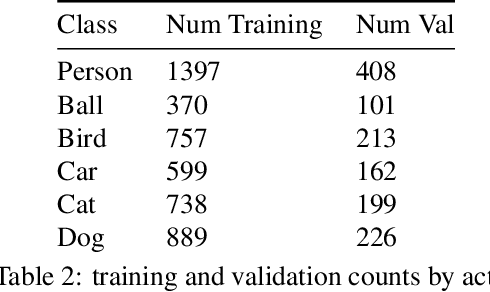
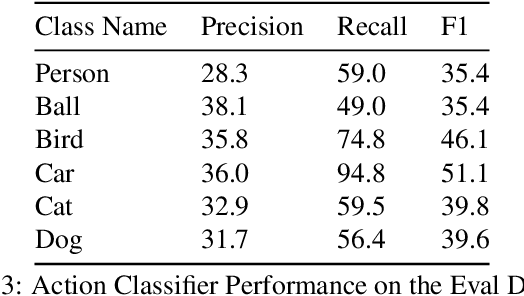
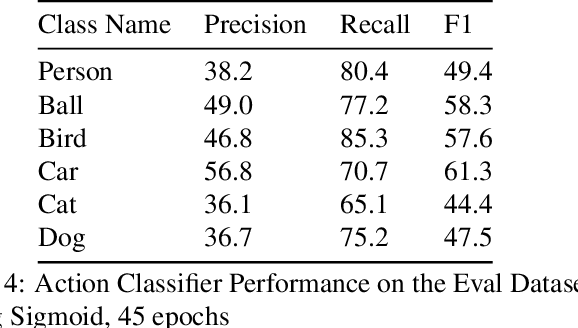
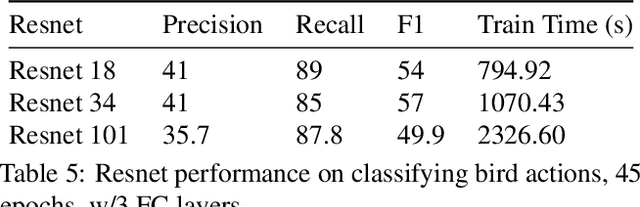
This technical report summarizes submissions and compiles from Actor-Action video classification challenge held as a final project in CSC 249/449 Machine Vision course (Spring 2020) at University of Rochester