 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobPI: Robust Private Inference against Malicious Client
Feb 23, 2026The increased deployment of machine learning inference in various applications has sparked privacy concerns. In response, private inference (PI) protocols have been created to allow parties to perform inference without revealing their sensitive data. Despite recent advances in the efficiency of PI, most current methods assume a semi-honest threat model where the data owner is honest and adheres to the protocol. However, in reality, data owners can have different motivations and act in unpredictable ways, making this assumption unrealistic. To demonstrate how a malicious client can compromise the semi-honest model, we first designed an inference manipulation attack against a range of state-of-the-art private inference protocols. This attack allows a malicious client to modify the model output with 3x to 8x fewer queries than current black-box attacks. Motivated by the attacks, we proposed and implemented RobPI, a robust and resilient private inference protocol that withstands malicious clients. RobPI integrates a distinctive cryptographic protocol that bolsters security by weaving encryption-compatible noise into the logits and features of private inference, thereby efficiently warding off malicious-client attacks. Our extensive experiments on various neural networks and datasets show that RobPI achieves ~91.9% attack success rate reduction and increases more than 10x the number of queries required by malicious-client attacks.
R2-Router: A New Paradigm for LLM Routing with Reasoning
Feb 02, 2026As LLMs proliferate with diverse capabilities and costs, LLM routing has emerged by learning to predict each LLM's quality and cost for a given query, then selecting the one with high quality and low cost. However, existing routers implicitly assume a single fixed quality and cost per LLM for each query, ignoring that the same LLM's quality varies with its output length. This causes routers to exclude powerful LLMs when their estimated cost exceeds the budget, missing the opportunity that these LLMs could still deliver high quality at reduced cost with shorter outputs. To address this, we introduce R2-Router, which treats output length budget as a controllable variable and jointly selects the best LLM and length budget, enforcing the budget via length-constrained instructions. This enables R2-Router to discover that a powerful LLM with constrained output can outperform a weaker LLM at comparable cost-efficient configurations invisible to prior methods. Together with the router framework, we construct R2-Bench, the first routing dataset capturing LLM behavior across diverse output length budgets. Experiments show that R2-Router achieves state-of-the-art performance at 4-5x lower cost compared with existing routers. This work opens a new direction: routing as reasoning, where routers evolve from reactive selectors to deliberate reasoners that explore which LLM to use and at what cost budget.
TFHE-Coder: Evaluating LLM-agentic Fully Homomorphic Encryption Code Generation
Mar 15, 2025



Fully Homomorphic Encryption over the torus (TFHE) enables computation on encrypted data without decryption, making it a cornerstone of secure and confidential computing. Despite its potential in privacy preserving machine learning, secure multi party computation, private blockchain transactions, and secure medical diagnostics, its adoption remains limited due to cryptographic complexity and usability challenges. While various TFHE libraries and compilers exist, practical code generation remains a hurdle. We propose a compiler integrated framework to evaluate LLM inference and agentic optimization for TFHE code generation, focusing on logic gates and ReLU activation. Our methodology assesses error rates, compilability, and structural similarity across open and closedsource LLMs. Results highlight significant limitations in off-the-shelf models, while agentic optimizations such as retrieval augmented generation (RAG) and few-shot prompting reduce errors and enhance code fidelity. This work establishes the first benchmark for TFHE code generation, demonstrating how LLMs, when augmented with domain-specific feedback, can bridge the expertise gap in FHE code generation.
CipherPrune: Efficient and Scalable Private Transformer Inference
Feb 24, 2025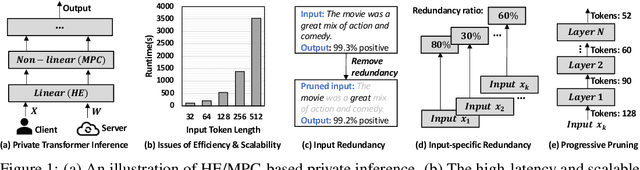
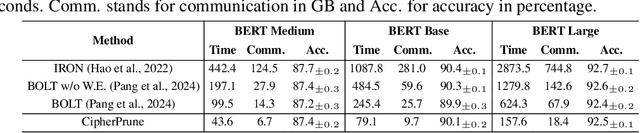
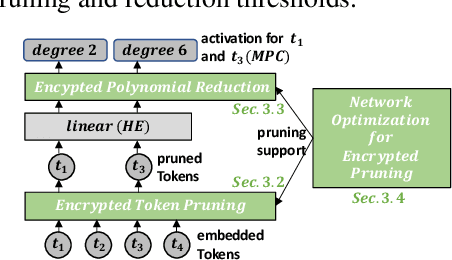
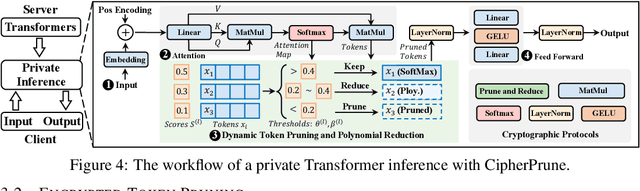
Private Transformer inference using cryptographic protocols offers promising solutions for privacy-preserving machine learning; however, it still faces significant runtime overhead (efficiency issues) and challenges in handling long-token inputs (scalability issues). We observe that the Transformer's operational complexity scales quadratically with the number of input tokens, making it essential to reduce the input token length. Notably, each token varies in importance, and many inputs contain redundant tokens. Additionally, prior private inference methods that rely on high-degree polynomial approximations for non-linear activations are computationally expensive. Therefore, reducing the polynomial degree for less important tokens can significantly accelerate private inference. Building on these observations, we propose \textit{CipherPrune}, an efficient and scalable private inference framework that includes a secure encrypted token pruning protocol, a polynomial reduction protocol, and corresponding Transformer network optimizations. At the protocol level, encrypted token pruning adaptively removes unimportant tokens from encrypted inputs in a progressive, layer-wise manner. Additionally, encrypted polynomial reduction assigns lower-degree polynomials to less important tokens after pruning, enhancing efficiency without decryption. At the network level, we introduce protocol-aware network optimization via a gradient-based search to maximize pruning thresholds and polynomial reduction conditions while maintaining the desired accuracy. Our experiments demonstrate that CipherPrune reduces the execution overhead of private Transformer inference by approximately $6.1\times$ for 128-token inputs and $10.6\times$ for 512-token inputs, compared to previous methods, with only a marginal drop in accuracy. The code is publicly available at https://github.com/UCF-Lou-Lab-PET/cipher-prune-inference.
Uncovering the Hidden Threat of Text Watermarking from Users with Cross-Lingual Knowledge
Feb 23, 2025



In this study, we delve into the hidden threats posed to text watermarking by users with cross-lingual knowledge. While most research focuses on watermarking methods for English, there is a significant gap in evaluating these methods in cross-lingual contexts. This oversight neglects critical adversary scenarios involving cross-lingual users, creating uncertainty regarding the effectiveness of cross-lingual watermarking. We assess four watermarking techniques across four linguistically rich languages, examining watermark resilience and text quality across various parameters and attacks. Our focus is on a realistic scenario featuring adversaries with cross-lingual expertise, evaluating the adequacy of current watermarking methods against such challenges.
BadFair: Backdoored Fairness Attacks with Group-conditioned Triggers
Oct 23, 2024Attacking fairness is crucial because compromised models can introduce biased outcomes, undermining trust and amplifying inequalities in sensitive applications like hiring, healthcare, and law enforcement. This highlights the urgent need to understand how fairness mechanisms can be exploited and to develop defenses that ensure both fairness and robustness. We introduce BadFair, a novel backdoored fairness attack methodology. BadFair stealthily crafts a model that operates with accuracy and fairness under regular conditions but, when activated by certain triggers, discriminates and produces incorrect results for specific groups. This type of attack is particularly stealthy and dangerous, as it circumvents existing fairness detection methods, maintaining an appearance of fairness in normal use. Our findings reveal that BadFair achieves a more than 85% attack success rate in attacks aimed at target groups on average while only incurring a minimal accuracy loss. Moreover, it consistently exhibits a significant discrimination score, distinguishing between pre-defined target and non-target attacked groups across various datasets and models.
CryptoTrain: Fast Secure Training on Encrypted Datase
Sep 25, 2024



Secure training, while protecting the confidentiality of both data and model weights, typically incurs significant training overhead. Traditional Fully Homomorphic Encryption (FHE)-based non-inter-active training models are heavily burdened by computationally demanding bootstrapping. To develop an efficient secure training system, we established a foundational framework, CryptoTrain-B, utilizing a hybrid cryptographic protocol that merges FHE with Oblivious Transfer (OT) for handling linear and non-linear operations, respectively. This integration eliminates the need for costly bootstrapping. Although CryptoTrain-B sets a new baseline in performance, reducing its training overhead remains essential. We found that ciphertext-ciphertext multiplication (CCMul) is a critical bottleneck in operations involving encrypted inputs and models. Our solution, the CCMul-Precompute technique, involves precomputing CCMul offline and resorting to the less resource-intensive ciphertext-plaintext multiplication (CPMul) during private training. Furthermore, conventional polynomial convolution in FHE systems tends to encode irrelevant and redundant values into polynomial slots, necessitating additional polynomials and ciphertexts for input representation and leading to extra multiplications. Addressing this, we introduce correlated polynomial convolution, which encodes only related input values into polynomials, thus drastically reducing the number of computations and overheads. By integrating CCMul-Precompute and correlated polynomial convolution into CryptoTrain-B, we facilitate a rapid and efficient secure training framework, CryptoTrain. Extensive experiments demonstrate that CryptoTrain achieves a ~5.3X training time reduction compared to prior methods.
CR-UTP: Certified Robustness against Universal Text Perturbations
Jun 04, 2024



It is imperative to ensure the stability of every prediction made by a language model; that is, a language's prediction should remain consistent despite minor input variations, like word substitutions. In this paper, we investigate the problem of certifying a language model's robustness against Universal Text Perturbations (UTPs), which have been widely used in universal adversarial attacks and backdoor attacks. Existing certified robustness based on random smoothing has shown considerable promise in certifying the input-specific text perturbations (ISTPs), operating under the assumption that any random alteration of a sample's clean or adversarial words would negate the impact of sample-wise perturbations. However, with UTPs, masking only the adversarial words can eliminate the attack. A naive method is to simply increase the masking ratio and the likelihood of masking attack tokens, but it leads to a significant reduction in both certified accuracy and the certified radius due to input corruption by extensive masking. To solve this challenge, we introduce a novel approach, the superior prompt search method, designed to identify a superior prompt that maintains higher certified accuracy under extensive masking. Additionally, we theoretically motivate why ensembles are a particularly suitable choice as base prompts for random smoothing. The method is denoted by superior prompt ensembling technique. We also empirically confirm this technique, obtaining state-of-the-art results in multiple settings. These methodologies, for the first time, enable high certified accuracy against both UTPs and ISTPs. The source code of CR-UTP is available at https://github.com/UCFML-Research/CR-UTP.
BadRAG: Identifying Vulnerabilities in Retrieval Augmented Generation of Large Language Models
Jun 03, 2024



Large Language Models (LLMs) are constrained by outdated information and a tendency to generate incorrect data, commonly referred to as "hallucinations." Retrieval-Augmented Generation (RAG) addresses these limitations by combining the strengths of retrieval-based methods and generative models. This approach involves retrieving relevant information from a large, up-to-date dataset and using it to enhance the generation process, leading to more accurate and contextually appropriate responses. Despite its benefits, RAG introduces a new attack surface for LLMs, particularly because RAG databases are often sourced from public data, such as the web. In this paper, we propose \TrojRAG{} to identify the vulnerabilities and attacks on retrieval parts (RAG database) and their indirect attacks on generative parts (LLMs). Specifically, we identify that poisoning several customized content passages could achieve a retrieval backdoor, where the retrieval works well for clean queries but always returns customized poisoned adversarial queries. Triggers and poisoned passages can be highly customized to implement various attacks. For example, a trigger could be a semantic group like "The Republican Party, Donald Trump, etc." Adversarial passages can be tailored to different contents, not only linked to the triggers but also used to indirectly attack generative LLMs without modifying them. These attacks can include denial-of-service attacks on RAG and semantic steering attacks on LLM generations conditioned by the triggers. Our experiments demonstrate that by just poisoning 10 adversarial passages can induce 98.2\% success rate to retrieve the adversarial passages. Then, these passages can increase the reject ratio of RAG-based GPT-4 from 0.01\% to 74.6\% or increase the rate of negative responses from 0.22\% to 72\% for targeted queries.
TrojFair: Trojan Fairness Attacks
Dec 16, 2023



Deep learning models have been incorporated into high-stakes sectors, including healthcare diagnosis, loan approvals, and candidate recruitment, among others. Consequently, any bias or unfairness in these models can harm those who depend on such models. In response, many algorithms have emerged to ensure fairness in deep learning. However, while the potential for harm is substantial, the resilience of these fair deep learning models against malicious attacks has never been thoroughly explored, especially in the context of emerging Trojan attacks. Moving beyond prior research, we aim to fill this void by introducing \textit{TrojFair}, a Trojan fairness attack. Unlike existing attacks, TrojFair is model-agnostic and crafts a Trojaned model that functions accurately and equitably for clean inputs. However, it displays discriminatory behaviors \text{-} producing both incorrect and unfair results \text{-} for specific groups with tainted inputs containing a trigger. TrojFair is a stealthy Fairness attack that is resilient to existing model fairness audition detectors since the model for clean inputs is fair. TrojFair achieves a target group attack success rate exceeding $88.77\%$, with an average accuracy loss less than $0.44\%$. It also maintains a high discriminative score between the target and non-target groups across various datasets and models.