 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNAPER: Fault Protection for Real-Time Resource-Constrained Deep Neural Networks
Apr 09, 2025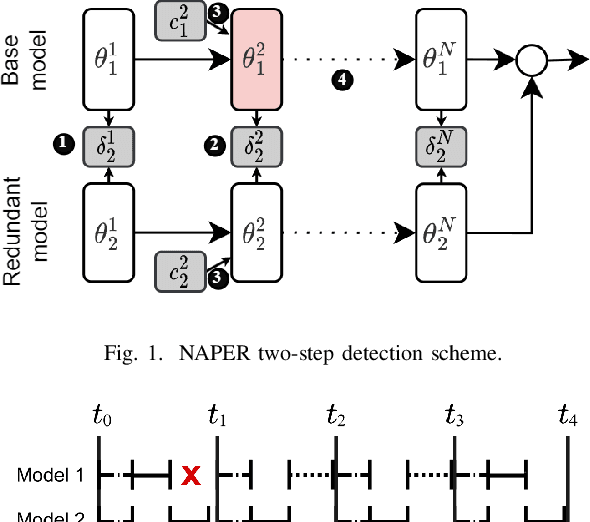
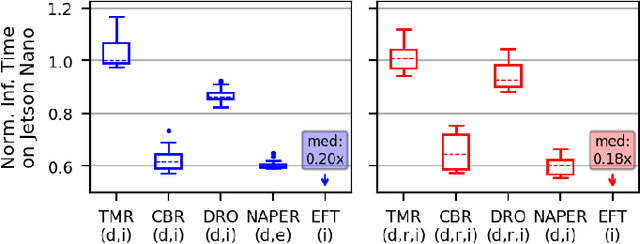
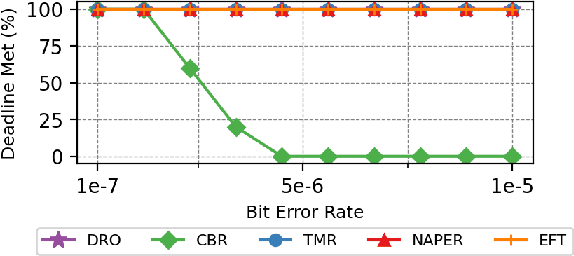
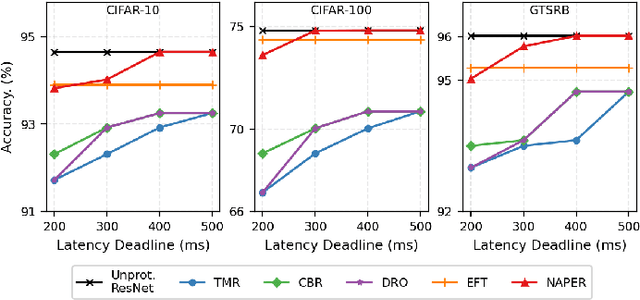
Fault tolerance in Deep Neural Networks (DNNs) deployed on resource-constrained systems presents unique challenges for high-accuracy applications with strict timing requirements. Memory bit-flips can severely degrade DNN accuracy, while traditional protection approaches like Triple Modular Redundancy (TMR) often sacrifice accuracy to maintain reliability, creating a three-way dilemma between reliability, accuracy, and timeliness. We introduce NAPER, a novel protection approach that addresses this challenge through ensemble learning. Unlike conventional redundancy methods, NAPER employs heterogeneous model redundancy, where diverse models collectively achieve higher accuracy than any individual model. This is complemented by an efficient fault detection mechanism and a real-time scheduler that prioritizes meeting deadlines by intelligently scheduling recovery operations without interrupting inference. Our evaluations demonstrate NAPER's superiority: 40% faster inference in both normal and fault conditions, maintained accuracy 4.2% higher than TMR-based strategies, and guaranteed uninterrupted operation even during fault recovery. NAPER effectively balances the competing demands of accuracy, reliability, and timeliness in real-time DNN applications
Uncovering the Hidden Threat of Text Watermarking from Users with Cross-Lingual Knowledge
Feb 23, 2025



In this study, we delve into the hidden threats posed to text watermarking by users with cross-lingual knowledge. While most research focuses on watermarking methods for English, there is a significant gap in evaluating these methods in cross-lingual contexts. This oversight neglects critical adversary scenarios involving cross-lingual users, creating uncertainty regarding the effectiveness of cross-lingual watermarking. We assess four watermarking techniques across four linguistically rich languages, examining watermark resilience and text quality across various parameters and attacks. Our focus is on a realistic scenario featuring adversaries with cross-lingual expertise, evaluating the adequacy of current watermarking methods against such challenges.
Jailbreaking LLMs with Arabic Transliteration and Arabizi
Jun 26, 2024This study identifies the potential vulnerabilities of Large Language Models (LLMs) to 'jailbreak' attacks, specifically focusing on the Arabic language and its various forms. While most research has concentrated on English-based prompt manipulation, our investigation broadens the scope to investigate the Arabic language. We initially tested the AdvBench benchmark in Standardized Arabic, finding that even with prompt manipulation techniques like prefix injection, it was insufficient to provoke LLMs into generating unsafe content. However, when using Arabic transliteration and chatspeak (or arabizi), we found that unsafe content could be produced on platforms like OpenAI GPT-4 and Anthropic Claude 3 Sonnet. Our findings suggest that using Arabic and its various forms could expose information that might remain hidden, potentially increasing the risk of jailbreak attacks. We hypothesize that this exposure could be due to the model's learned connection to specific words, highlighting the need for more comprehensive safety training across all language forms.
Group-wise Reinforcement Feature Generation for Optimal and Explainable Representation Space Reconstruction
May 28, 2022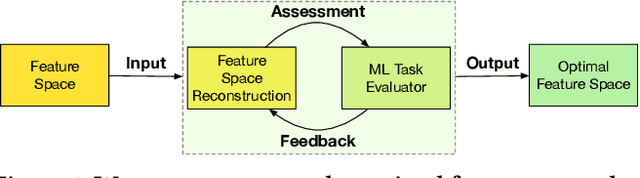
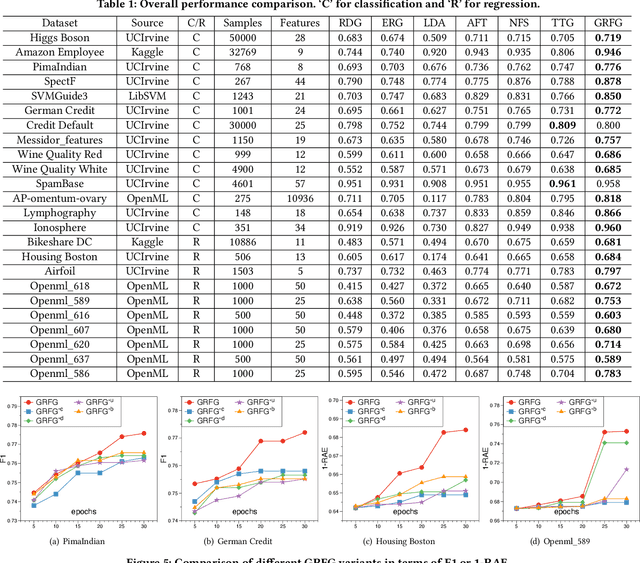
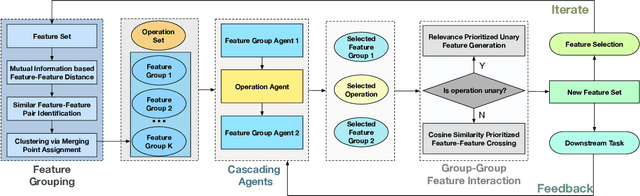
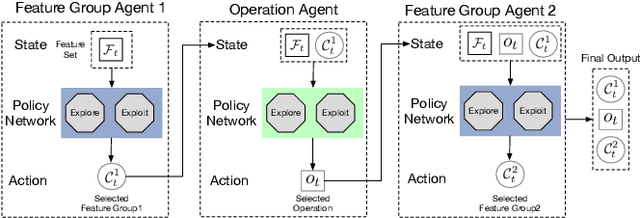
Representation (feature) space is an environment where data points are vectorized, distances are computed, patterns are characterized, and geometric structures are embedded. Extracting a good representation space is critical to address the curse of dimensionality, improve model generalization, overcome data sparsity, and increase the availability of classic models. Existing literature, such as feature engineering and representation learning, is limited in achieving full automation (e.g., over heavy reliance on intensive labor and empirical experiences), explainable explicitness (e.g., traceable reconstruction process and explainable new features), and flexible optimal (e.g., optimal feature space reconstruction is not embedded into downstream tasks). Can we simultaneously address the automation, explicitness, and optimal challenges in representation space reconstruction for a machine learning task? To answer this question, we propose a group-wise reinforcement generation perspective. We reformulate representation space reconstruction into an interactive process of nested feature generation and selection, where feature generation is to generate new meaningful and explicit features, and feature selection is to eliminate redundant features to control feature sizes. We develop a cascading reinforcement learning method that leverages three cascading Markov Decision Processes to learn optimal generation policies to automate the selection of features and operations and the feature crossing. We design a group-wise generation strategy to cross a feature group, an operation, and another feature group to generate new features and find the strategy that can enhance exploration efficiency and augment reward signals of cascading agents. Finally, we present extensive experiments to demonstrate the effectiveness, efficiency, traceability, and explicitness of our system.
MILR: Mathematically Induced Layer Recovery for Plaintext Space Error Correction of CNNs
Oct 28, 2020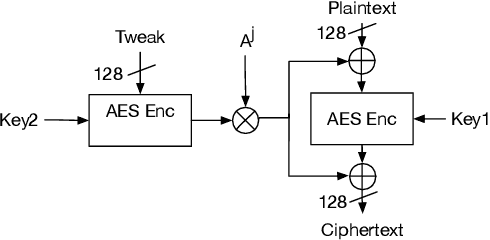

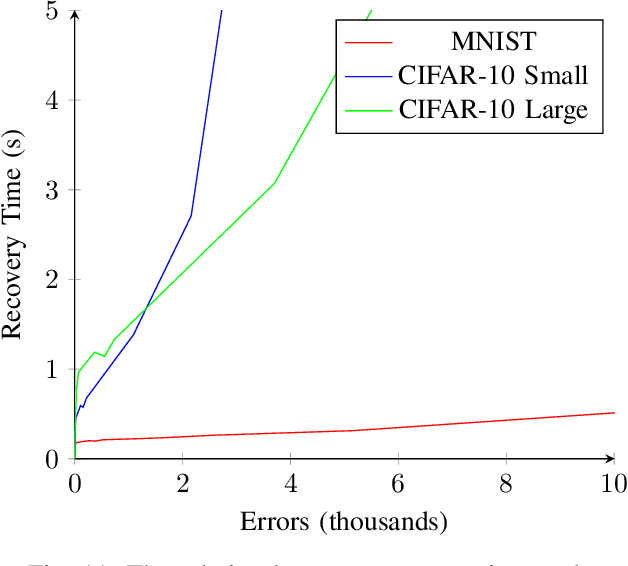
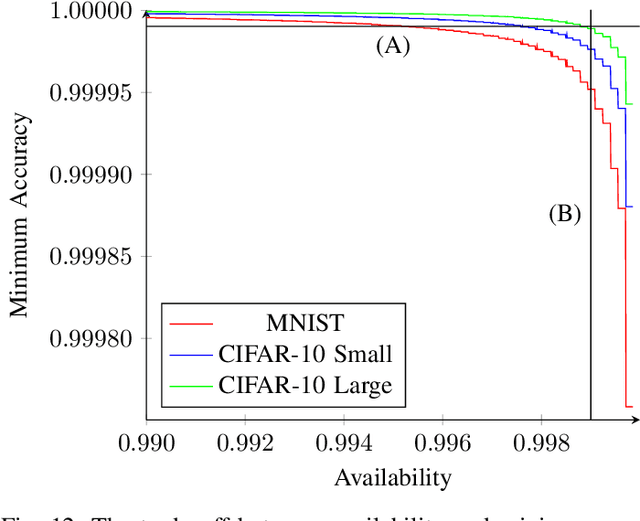
The increased use of Convolutional Neural Networks (CNN) in mission critical systems has increased the need for robust and resilient networks in the face of both naturally occurring faults as well as security attacks. The lack of robustness and resiliency can lead to unreliable inference results. Current methods that address CNN robustness require hardware modification, network modification, or network duplication. This paper proposes MILR a software based CNN error detection and error correction system that enables self-healing of the network from single and multi bit errors. The self-healing capabilities are based on mathematical relationships between the inputs,outputs, and parameters(weights) of a layers, exploiting these relationships allow the recovery of erroneous parameters (weights) throughout a layer and the network. MILR is suitable for plaintext-space error correction (PSEC) given its ability to correct whole-weight and even whole-layer errors in CNNs.