 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Structured Sparse Network for Efficient CNNs with Feature Regularization
Oct 21, 2020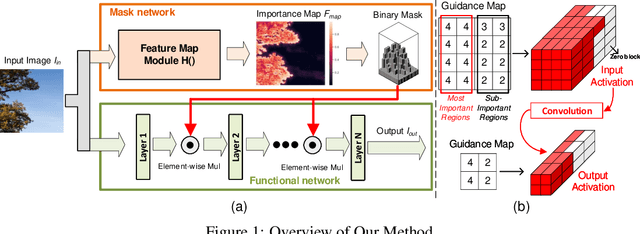
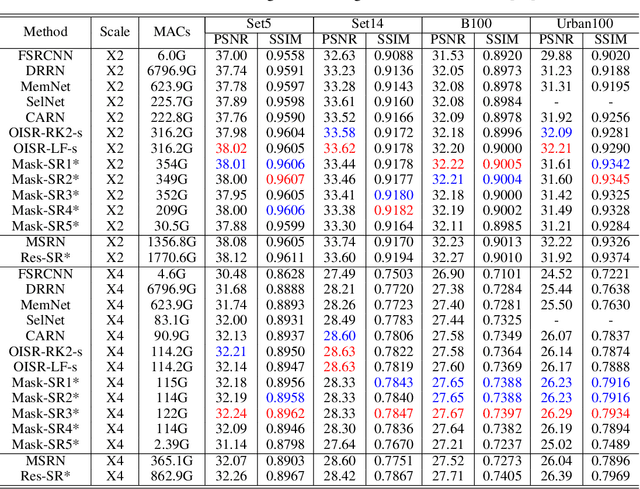
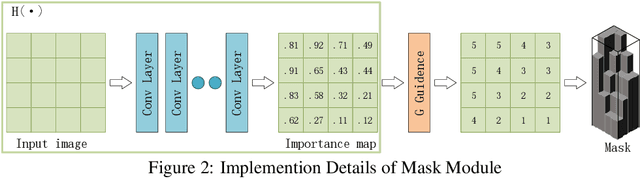
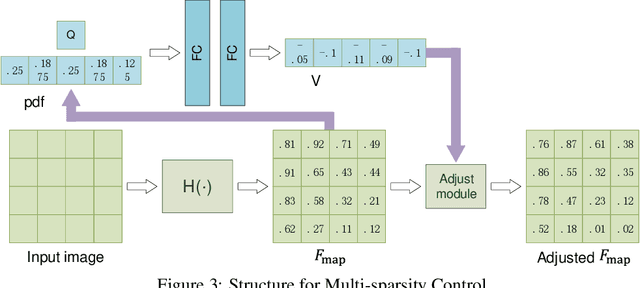
Neural networks have made great progress in pixel to pixel image processing tasks, e.g. super resolution, style transfer and image denoising. However, recent algorithms have a tendency to be too structurally complex to deploy on embedded systems. Traditional accelerating methods fix the options for pruning network weights to produce unstructured or structured sparsity. Many of them lack flexibility for different inputs. In this paper, we propose a Feature Regularization method that can generate input-dependent structured sparsity for hidden features. Our method can improve sparsity level in intermediate features by 60% to over 95% through pruning along the channel dimension for each pixel, thus relieving the computational and memory burden. On BSD100 dataset, the multiply-accumulate operations can be reduced by over 80% for super resolution tasks. In addition, we propose a method to quantitatively control the level of sparsity and design a way to train one model that supports multi-sparsity. We identify the effectiveness of our method for pixel to pixel tasks by qualitative theoretical analysis and experiments.
ADMP: An Adversarial Double Masks Based Pruning Framework For Unsupervised Cross-Domain Compression
Jun 07, 2020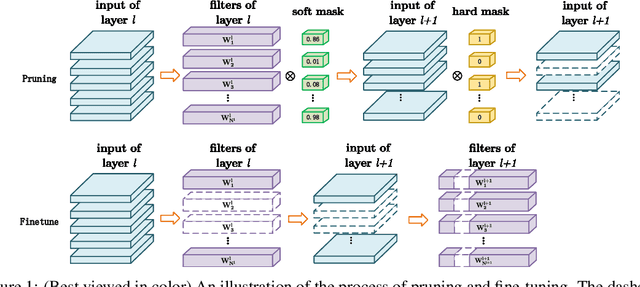
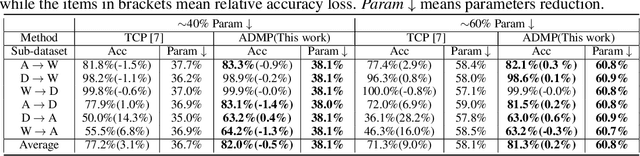
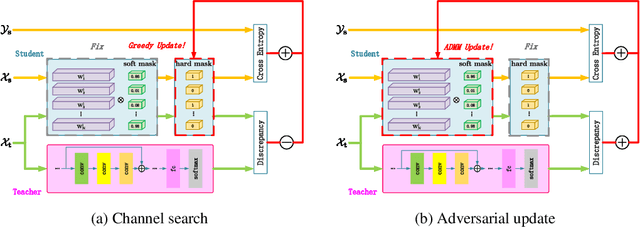
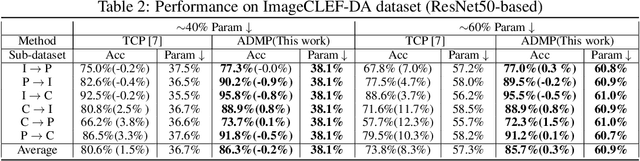
Despite the recent progress of network pruning, directly applying it to the Internet of Things (IoT) applications still faces two challenges, i.e. the distribution divergence between end and cloud data and the missing of data label on end devices. One straightforward solution is to combine the unsupervised domain adaptation (UDA) technique and pruning. For example, the model is first pruned on the cloud and then transferred from cloud to end by UDA. However, such a naive combination faces high performance degradation. Hence this work proposes an Adversarial Double Masks based Pruning (ADMP) for such cross-domain compression. In ADMP, we construct a Knowledge Distillation framework not only to produce pseudo labels but also to provide a measurement of domain divergence as the output difference between the full-size teacher and the pruned student. Unlike existing mask-based pruning works, two adversarial masks, i.e. soft and hard masks, are adopted in ADMP. So ADMP can prune the model effectively while still allowing the model to extract strong domain-invariant features and robust classification boundaries. During training, the Alternating Direction Multiplier Method is used to overcome the binary constraint of {0,1}-masks. On Office31 and ImageCLEF-DA datasets, the proposed ADMP can prune 60% channels with only 0.2% and 0.3% average accuracy loss respectively. Compared with the state of art, we can achieve about 1.63x parameters reduction and 4.1% and 5.1% accuracy improvement.