 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeREMAC: Reference-Based Martian Asymmetrical Image Compression
Jan 26, 2026To expedite space exploration on Mars, it is indispensable to develop an efficient Martian image compression method for transmitting images through the constrained Mars-to-Earth communication channel. Although the existing learned compression methods have achieved promising results for natural images from earth, there remain two critical issues that hinder their effectiveness for Martian image compression: 1) They overlook the highly-limited computational resources on Mars; 2) They do not utilize the strong \textit{inter-image} similarities across Martian images to advance image compression performance. Motivated by our empirical analysis of the strong \textit{intra-} and \textit{inter-image} similarities from the perspective of texture, color, and semantics, we propose a reference-based Martian asymmetrical image compression (REMAC) approach, which shifts computational complexity from the encoder to the resource-rich decoder and simultaneously improves compression performance. To leverage \textit{inter-image} similarities, we propose a reference-guided entropy module and a ref-decoder that utilize useful information from reference images, reducing redundant operations at the encoder and achieving superior compression performance. To exploit \textit{intra-image} similarities, the ref-decoder adopts a deep, multi-scale architecture with enlarged receptive field size to model long-range spatial dependencies. Additionally, we develop a latent feature recycling mechanism to further alleviate the extreme computational constraints on Mars. Experimental results show that REMAC reduces encoder complexity by 43.51\% compared to the state-of-the-art method, while achieving a BD-PSNR gain of 0.2664 dB.
* Accepted for publication in IEEE Transactions on Geoscience and Remote Sensing (TGRS). 2025 IEEE. Personal use is permitted, but republication/redistribution requires IEEE permission. 18 pages, 20 figures
Pixel Adapter: A Graph-Based Post-Processing Approach for Scene Text Image Super-Resolution
Sep 16, 2023



Current Scene text image super-resolution approaches primarily focus on extracting robust features, acquiring text information, and complex training strategies to generate super-resolution images. However, the upsampling module, which is crucial in the process of converting low-resolution images to high-resolution ones, has received little attention in existing works. To address this issue, we propose the Pixel Adapter Module (PAM) based on graph attention to address pixel distortion caused by upsampling. The PAM effectively captures local structural information by allowing each pixel to interact with its neighbors and update features. Unlike previous graph attention mechanisms, our approach achieves 2-3 orders of magnitude improvement in efficiency and memory utilization by eliminating the dependency on sparse adjacency matrices and introducing a sliding window approach for efficient parallel computation. Additionally, we introduce the MLP-based Sequential Residual Block (MSRB) for robust feature extraction from text images, and a Local Contour Awareness loss ($\mathcal{L}_{lca}$) to enhance the model's perception of details. Comprehensive experiments on TextZoom demonstrate that our proposed method generates high-quality super-resolution images, surpassing existing methods in recognition accuracy. For single-stage and multi-stage strategies, we achieved improvements of 0.7\% and 2.6\%, respectively, increasing the performance from 52.6\% and 53.7\% to 53.3\% and 56.3\%. The code is available at https://github.com/wenyu1009/RTSRN.
Pixel-wise Graph Attention Networks for Person Re-identification
Jul 18, 2023



Graph convolutional networks (GCN) is widely used to handle irregular data since it updates node features by using the structure information of graph. With the help of iterated GCN, high-order information can be obtained to further enhance the representation of nodes. However, how to apply GCN to structured data (such as pictures) has not been deeply studied. In this paper, we explore the application of graph attention networks (GAT) in image feature extraction. First of all, we propose a novel graph generation algorithm to convert images into graphs through matrix transformation. It is one magnitude faster than the algorithm based on K Nearest Neighbors (KNN). Then, GAT is used on the generated graph to update the node features. Thus, a more robust representation is obtained. These two steps are combined into a module called pixel-wise graph attention module (PGA). Since the graph obtained by our graph generation algorithm can still be transformed into a picture after processing, PGA can be well combined with CNN. Based on these two modules, we consulted the ResNet and design a pixel-wise graph attention network (PGANet). The PGANet is applied to the task of person re-identification in the datasets Market1501, DukeMTMC-reID and Occluded-DukeMTMC (outperforms state-of-the-art by 0.8\%, 1.1\% and 11\% respectively, in mAP scores). Experiment results show that it achieves the state-of-the-art performance. \href{https://github.com/wenyu1009/PGANet}{The code is available here}.
Point is a Vector: A Feature Representation in Point Analysis
May 21, 2022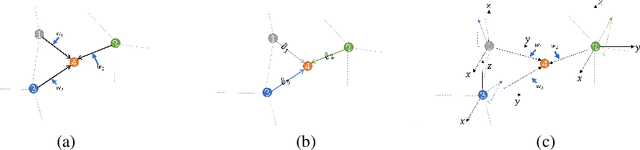

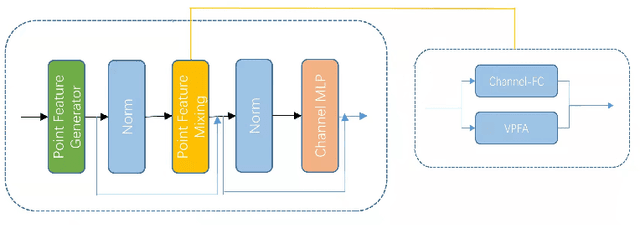

The irregularity and disorder of point clouds bring many challenges to point cloud analysis. PointMLP suggests that geometric information is not the only critical point in point cloud analysis. It achieves promising result based on a simple multi-layer perception (MLP) structure with geometric affine module. However, these MLP-like structures aggregate features only with fixed weights, while differences in the semantic information of different point features are ignored. So we propose a novel Point-Vector Representation of the point feature to improve feature aggregation by using inductive bias. The direction of the introduced vector representation can dynamically modulate the aggregation of two point features according to the semantic relationship. Based on it, we design a novel Point2Vector MLP architecture. Experiments show that it achieves state-of-the-art performance on the classification task of ScanObjectNN dataset, with 1% increase, compared with the previous best method. We hope our method can help people better understand the role of semantic information in point cloud analysis and lead to explore more and better feature representations or other ways.
GLSD: The Global Large-Scale Ship Database and Baseline Evaluations
Jun 05, 2021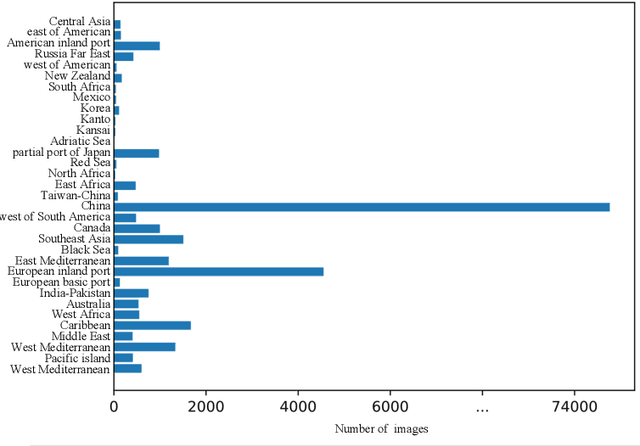


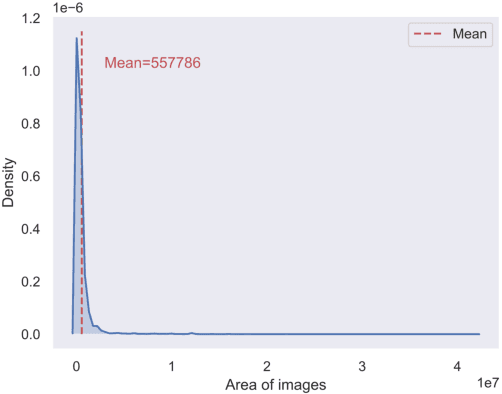
In this paper, we introduce a challenging global large-scale ship database (called GLSD), designed specifically for ship detection tasks. The designed GLSD database includes a total of 140,616 annotated instances from 100,729 images. Based on the collected images, we propose 13 categories that widely exists in international routes. These categories include sailing boat, fishing boat, passenger ship, war ship, general cargo ship, container ship, bulk cargo carrier, barge, ore carrier, speed boat, canoe, oil carrier, and tug. The motivations of developing GLSD include the following: 1) providing a refined ship detection database; 2) providing the worldwide researchers of ship detection and exhaustive label information (bounding box and ship class label) in one uniform global database; and 3) providing a large-scale ship database with geographic information (port and country information) that benefits multi-modal analysis. In addition, we discuss the evaluation protocols given image characteristics in GLSD and analyze the performance of selected state-of-the-art object detection algorithms on GSLD, providing baselines for future studies. More information regarding the designed GLSD can be found at https://github.com/jiaming-wang/GLSD.