 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAquila: A Hierarchically Aligned Visual-Language Model for Enhanced Remote Sensing Image Comprehension
Nov 09, 2024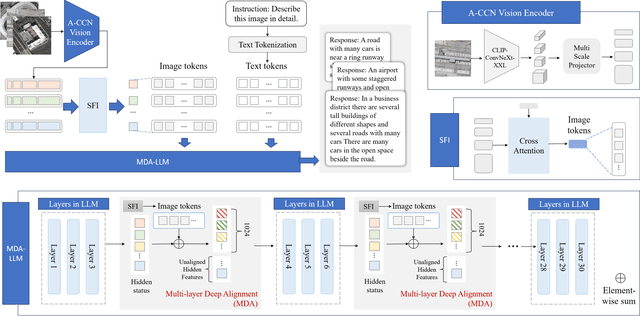

Recently, large vision language models (VLMs) have made significant strides in visual language capabilities through visual instruction tuning, showing great promise in the field of remote sensing image interpretation. However, existing remote sensing vision language models (RSVLMs) often fall short in capturing the complex characteristics of remote sensing scenes, as they typically rely on low resolution, single scale visual features and simplistic methods to map visual features to language features. In this paper, we present Aquila, an advanced visual language foundation model designed to enable richer visual feature representation and more precise visual-language feature alignment for remote sensing images. Our approach introduces a learnable Hierarchical Spatial Feature Integration (SFI) module that supports high resolution image inputs and aggregates multi scale visual features, allowing for the detailed representation of complex visual information. Additionally, the SFI module is repeatedly integrated into the layers of the large language model (LLM) to achieve deep visual language feature alignment, without compromising the model's performance in natural language processing tasks. These innovations, capturing detailed visual effects through higher resolution and multi scale input, and enhancing feature alignment significantly improve the model's ability to learn from image text data. We validate the effectiveness of Aquila through extensive quantitative experiments and qualitative analyses, demonstrating its superior performance.
Pattern Integration and Enhancement Vision Transformer for Self-Supervised Learning in Remote Sensing
Nov 09, 2024



Recent self-supervised learning (SSL) methods have demonstrated impressive results in learning visual representations from unlabeled remote sensing images. However, most remote sensing images predominantly consist of scenographic scenes containing multiple ground objects without explicit foreground targets, which limits the performance of existing SSL methods that focus on foreground targets. This raises the question: Is there a method that can automatically aggregate similar objects within scenographic remote sensing images, thereby enabling models to differentiate knowledge embedded in various geospatial patterns for improved feature representation? In this work, we present the Pattern Integration and Enhancement Vision Transformer (PIEViT), a novel self-supervised learning framework designed specifically for remote sensing imagery. PIEViT utilizes a teacher-student architecture to address both image-level and patch-level tasks. It employs the Geospatial Pattern Cohesion (GPC) module to explore the natural clustering of patches, enhancing the differentiation of individual features. The Feature Integration Projection (FIP) module further refines masked token reconstruction using geospatially clustered patches. We validated PIEViT across multiple downstream tasks, including object detection, semantic segmentation, and change detection. Experiments demonstrated that PIEViT enhances the representation of internal patch features, providing significant improvements over existing self-supervised baselines. It achieves excellent results in object detection, land cover classification, and change detection, underscoring its robustness, generalization, and transferability for remote sensing image interpretation tasks.
GLSD: The Global Large-Scale Ship Database and Baseline Evaluations
Jun 05, 2021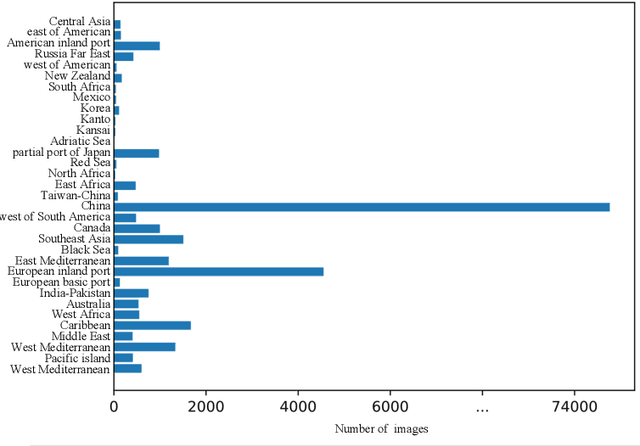


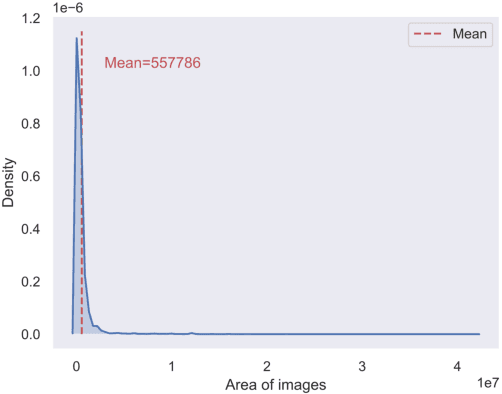
In this paper, we introduce a challenging global large-scale ship database (called GLSD), designed specifically for ship detection tasks. The designed GLSD database includes a total of 140,616 annotated instances from 100,729 images. Based on the collected images, we propose 13 categories that widely exists in international routes. These categories include sailing boat, fishing boat, passenger ship, war ship, general cargo ship, container ship, bulk cargo carrier, barge, ore carrier, speed boat, canoe, oil carrier, and tug. The motivations of developing GLSD include the following: 1) providing a refined ship detection database; 2) providing the worldwide researchers of ship detection and exhaustive label information (bounding box and ship class label) in one uniform global database; and 3) providing a large-scale ship database with geographic information (port and country information) that benefits multi-modal analysis. In addition, we discuss the evaluation protocols given image characteristics in GLSD and analyze the performance of selected state-of-the-art object detection algorithms on GSLD, providing baselines for future studies. More information regarding the designed GLSD can be found at https://github.com/jiaming-wang/GLSD.
Pan-sharpening via High-pass Modification Convolutional Neural Network
May 24, 2021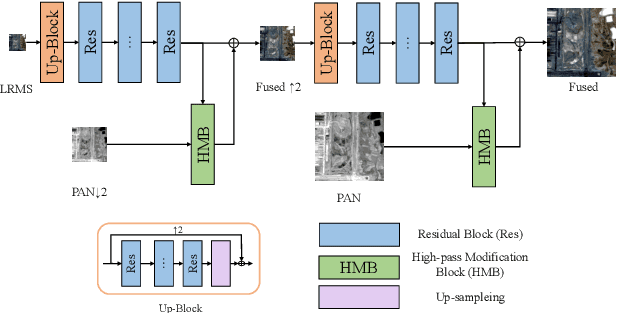

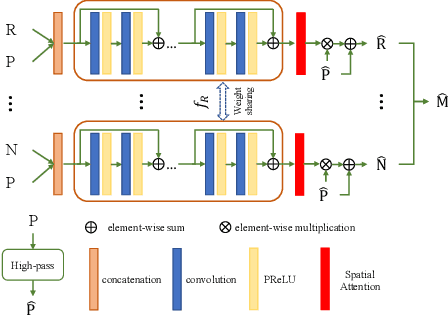

Most existing deep learning-based pan-sharpening methods have several widely recognized issues, such as spectral distortion and insufficient spatial texture enhancement, we propose a novel pan-sharpening convolutional neural network based on a high-pass modification block. Different from existing methods, the proposed block is designed to learn the high-pass information, leading to enhance spatial information in each band of the multi-spectral-resolution images. To facilitate the generation of visually appealing pan-sharpened images, we propose a perceptual loss function and further optimize the model based on high-level features in the near-infrared space. Experiments demonstrate the superior performance of the proposed method compared to the state-of-the-art pan-sharpening methods, both quantitatively and qualitatively. The proposed model is open-sourced at https://github.com/jiaming-wang/HMB.
Unsupervised Remote Sensing Super-Resolution via Migration Image Prior
May 23, 2021

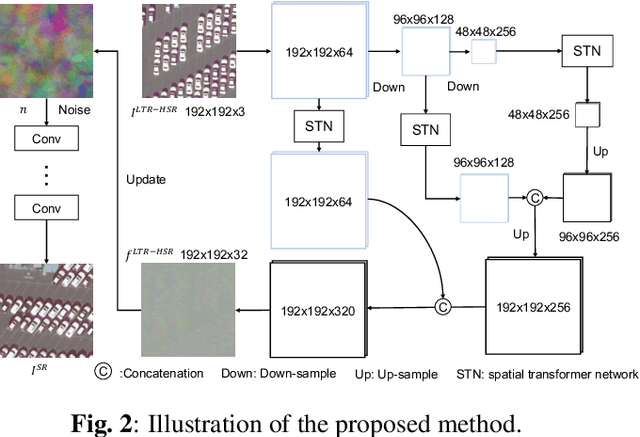
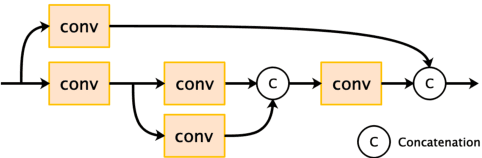
Recently, satellites with high temporal resolution have fostered wide attention in various practical applications. Due to limitations of bandwidth and hardware cost, however, the spatial resolution of such satellites is considerably low, largely limiting their potentials in scenarios that require spatially explicit information. To improve image resolution, numerous approaches based on training low-high resolution pairs have been proposed to address the super-resolution (SR) task. Despite their success, however, low/high spatial resolution pairs are usually difficult to obtain in satellites with a high temporal resolution, making such approaches in SR impractical to use. In this paper, we proposed a new unsupervised learning framework, called "MIP", which achieves SR tasks without low/high resolution image pairs. First, random noise maps are fed into a designed generative adversarial network (GAN) for reconstruction. Then, the proposed method converts the reference image to latent space as the migration image prior. Finally, we update the input noise via an implicit method, and further transfer the texture and structured information from the reference image. Extensive experimental results on the Draper dataset show that MIP achieves significant improvements over state-of-the-art methods both quantitatively and qualitatively. The proposed MIP is open-sourced at http://github.com/jiaming-wang/MIP.