 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAquila: A Hierarchically Aligned Visual-Language Model for Enhanced Remote Sensing Image Comprehension
Nov 09, 2024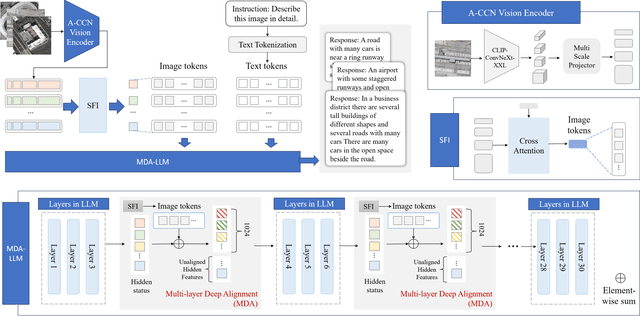

Recently, large vision language models (VLMs) have made significant strides in visual language capabilities through visual instruction tuning, showing great promise in the field of remote sensing image interpretation. However, existing remote sensing vision language models (RSVLMs) often fall short in capturing the complex characteristics of remote sensing scenes, as they typically rely on low resolution, single scale visual features and simplistic methods to map visual features to language features. In this paper, we present Aquila, an advanced visual language foundation model designed to enable richer visual feature representation and more precise visual-language feature alignment for remote sensing images. Our approach introduces a learnable Hierarchical Spatial Feature Integration (SFI) module that supports high resolution image inputs and aggregates multi scale visual features, allowing for the detailed representation of complex visual information. Additionally, the SFI module is repeatedly integrated into the layers of the large language model (LLM) to achieve deep visual language feature alignment, without compromising the model's performance in natural language processing tasks. These innovations, capturing detailed visual effects through higher resolution and multi scale input, and enhancing feature alignment significantly improve the model's ability to learn from image text data. We validate the effectiveness of Aquila through extensive quantitative experiments and qualitative analyses, demonstrating its superior performance.
Pattern Integration and Enhancement Vision Transformer for Self-Supervised Learning in Remote Sensing
Nov 09, 2024



Recent self-supervised learning (SSL) methods have demonstrated impressive results in learning visual representations from unlabeled remote sensing images. However, most remote sensing images predominantly consist of scenographic scenes containing multiple ground objects without explicit foreground targets, which limits the performance of existing SSL methods that focus on foreground targets. This raises the question: Is there a method that can automatically aggregate similar objects within scenographic remote sensing images, thereby enabling models to differentiate knowledge embedded in various geospatial patterns for improved feature representation? In this work, we present the Pattern Integration and Enhancement Vision Transformer (PIEViT), a novel self-supervised learning framework designed specifically for remote sensing imagery. PIEViT utilizes a teacher-student architecture to address both image-level and patch-level tasks. It employs the Geospatial Pattern Cohesion (GPC) module to explore the natural clustering of patches, enhancing the differentiation of individual features. The Feature Integration Projection (FIP) module further refines masked token reconstruction using geospatially clustered patches. We validated PIEViT across multiple downstream tasks, including object detection, semantic segmentation, and change detection. Experiments demonstrated that PIEViT enhances the representation of internal patch features, providing significant improvements over existing self-supervised baselines. It achieves excellent results in object detection, land cover classification, and change detection, underscoring its robustness, generalization, and transferability for remote sensing image interpretation tasks.
A Review of Point Cloud Semantic Segmentation
Sep 03, 2019
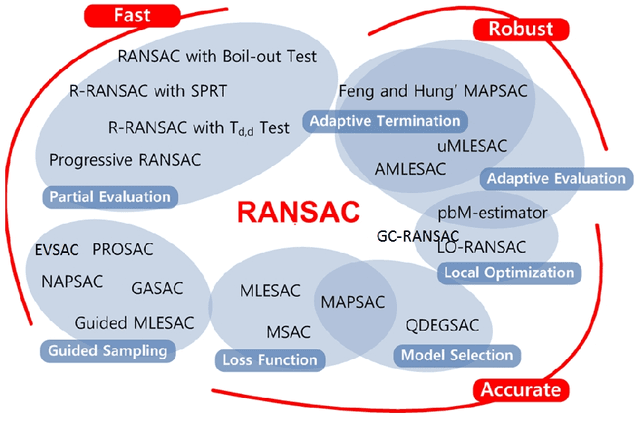
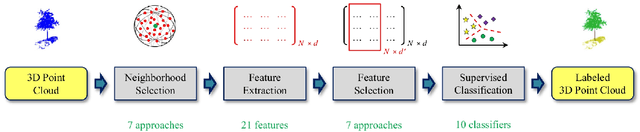
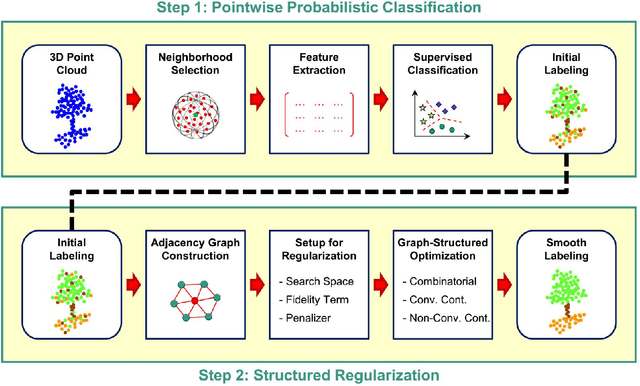
3D Point Cloud Semantic Segmentation (PCSS) is attracting increasing interest, due to its applicability in remote sensing, computer vision and robotics, and due to the new possibilities offered by deep learning techniques. In order to provide a needed up-to-date review of recent developments in PCSS, this article summarizes existing studies on this topic. Firstly, we outline the acquisition and evolution of the 3D point cloud from the perspective of remote sensing and computer vision, as well as the published benchmarks for PCSS studies. Then, traditional and advanced techniques used for Point Cloud Segmentation (PCS) and PCSS are reviewed and compared. Finally, important issues and open questions in PCSS studies are discussed.