 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAquila: A Hierarchically Aligned Visual-Language Model for Enhanced Remote Sensing Image Comprehension
Paper and Code
Nov 09, 2024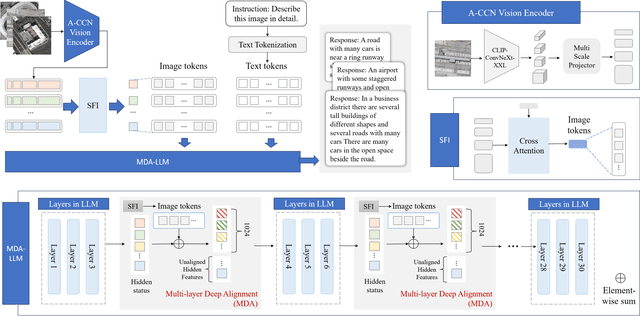
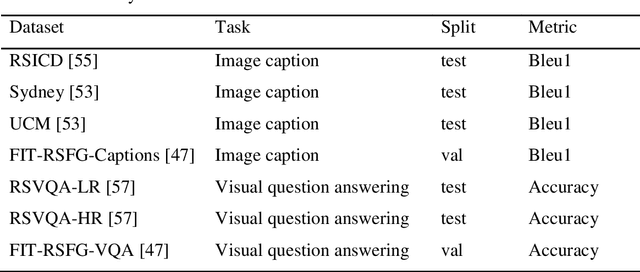
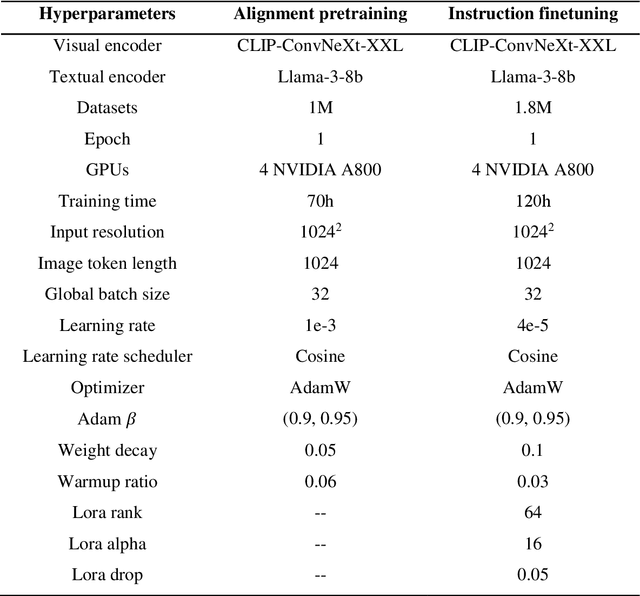

Recently, large vision language models (VLMs) have made significant strides in visual language capabilities through visual instruction tuning, showing great promise in the field of remote sensing image interpretation. However, existing remote sensing vision language models (RSVLMs) often fall short in capturing the complex characteristics of remote sensing scenes, as they typically rely on low resolution, single scale visual features and simplistic methods to map visual features to language features. In this paper, we present Aquila, an advanced visual language foundation model designed to enable richer visual feature representation and more precise visual-language feature alignment for remote sensing images. Our approach introduces a learnable Hierarchical Spatial Feature Integration (SFI) module that supports high resolution image inputs and aggregates multi scale visual features, allowing for the detailed representation of complex visual information. Additionally, the SFI module is repeatedly integrated into the layers of the large language model (LLM) to achieve deep visual language feature alignment, without compromising the model's performance in natural language processing tasks. These innovations, capturing detailed visual effects through higher resolution and multi scale input, and enhancing feature alignment significantly improve the model's ability to learn from image text data. We validate the effectiveness of Aquila through extensive quantitative experiments and qualitative analyses, demonstrating its superior performance.