 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutoQ-VIS: Improving Unsupervised Video Instance Segmentation via Automatic Quality Assessment
Aug 27, 2025



Video Instance Segmentation (VIS) faces significant annotation challenges due to its dual requirements of pixel-level masks and temporal consistency labels. While recent unsupervised methods like VideoCutLER eliminate optical flow dependencies through synthetic data, they remain constrained by the synthetic-to-real domain gap. We present AutoQ-VIS, a novel unsupervised framework that bridges this gap through quality-guided self-training. Our approach establishes a closed-loop system between pseudo-label generation and automatic quality assessment, enabling progressive adaptation from synthetic to real videos. Experiments demonstrate state-of-the-art performance with 52.6 $\text{AP}_{50}$ on YouTubeVIS-2019 val set, surpassing the previous state-of-the-art VideoCutLER by 4.4$\%$, while requiring no human annotations. This demonstrates the viability of quality-aware self-training for unsupervised VIS. The source code of our method is available at https://github.com/wcbup/AutoQ-VIS.
Aquila: A Hierarchically Aligned Visual-Language Model for Enhanced Remote Sensing Image Comprehension
Nov 09, 2024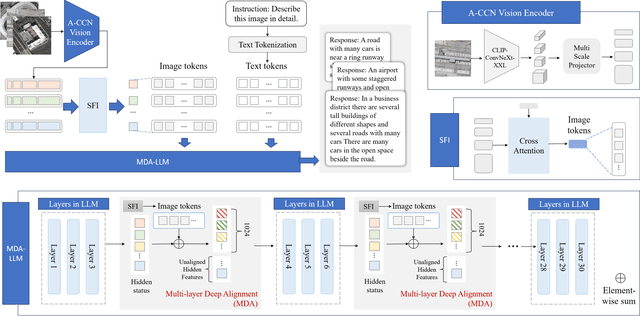

Recently, large vision language models (VLMs) have made significant strides in visual language capabilities through visual instruction tuning, showing great promise in the field of remote sensing image interpretation. However, existing remote sensing vision language models (RSVLMs) often fall short in capturing the complex characteristics of remote sensing scenes, as they typically rely on low resolution, single scale visual features and simplistic methods to map visual features to language features. In this paper, we present Aquila, an advanced visual language foundation model designed to enable richer visual feature representation and more precise visual-language feature alignment for remote sensing images. Our approach introduces a learnable Hierarchical Spatial Feature Integration (SFI) module that supports high resolution image inputs and aggregates multi scale visual features, allowing for the detailed representation of complex visual information. Additionally, the SFI module is repeatedly integrated into the layers of the large language model (LLM) to achieve deep visual language feature alignment, without compromising the model's performance in natural language processing tasks. These innovations, capturing detailed visual effects through higher resolution and multi scale input, and enhancing feature alignment significantly improve the model's ability to learn from image text data. We validate the effectiveness of Aquila through extensive quantitative experiments and qualitative analyses, demonstrating its superior performance.
Aquila-plus: Prompt-Driven Visual-Language Models for Pixel-Level Remote Sensing Image Understanding
Nov 09, 2024The recent development of vision language models (VLMs) has led to significant advances in visual-language integration through visual instruction tuning, and they have rapidly evolved in the field of remote sensing image understanding, demonstrating their powerful capabilities. However, existing RSVLMs mainly focus on image-level or frame-level understanding, making it difficult to achieve fine-grained pixel-level visual-language alignment. Additionally, the lack of mask-based instructional data limits their further development. In this paper, we propose a mask-text instruction tuning method called Aquila-plus, which extends the capabilities of RSVLMs to achieve pixel-level visual understanding by incorporating fine-grained mask regions into language instructions. To achieve this, we first meticulously constructed a mask region-text dataset containing 100K samples, and then designed a visual-language model by injecting pixel-level representations into a large language model (LLM). Specifically, Aquila-plus uses a convolutional CLIP as the visual encoder and employs a mask-aware visual extractor to extract precise visual mask features from high-resolution inputs. Experimental results demonstrate that Aquila-plus outperforms existing methods in various region understanding tasks, showcasing its novel capabilities in pixel-level instruction tuning.
Pattern Integration and Enhancement Vision Transformer for Self-Supervised Learning in Remote Sensing
Nov 09, 2024



Recent self-supervised learning (SSL) methods have demonstrated impressive results in learning visual representations from unlabeled remote sensing images. However, most remote sensing images predominantly consist of scenographic scenes containing multiple ground objects without explicit foreground targets, which limits the performance of existing SSL methods that focus on foreground targets. This raises the question: Is there a method that can automatically aggregate similar objects within scenographic remote sensing images, thereby enabling models to differentiate knowledge embedded in various geospatial patterns for improved feature representation? In this work, we present the Pattern Integration and Enhancement Vision Transformer (PIEViT), a novel self-supervised learning framework designed specifically for remote sensing imagery. PIEViT utilizes a teacher-student architecture to address both image-level and patch-level tasks. It employs the Geospatial Pattern Cohesion (GPC) module to explore the natural clustering of patches, enhancing the differentiation of individual features. The Feature Integration Projection (FIP) module further refines masked token reconstruction using geospatially clustered patches. We validated PIEViT across multiple downstream tasks, including object detection, semantic segmentation, and change detection. Experiments demonstrated that PIEViT enhances the representation of internal patch features, providing significant improvements over existing self-supervised baselines. It achieves excellent results in object detection, land cover classification, and change detection, underscoring its robustness, generalization, and transferability for remote sensing image interpretation tasks.
RCDT: Relational Remote Sensing Change Detection with Transformer
Dec 09, 2022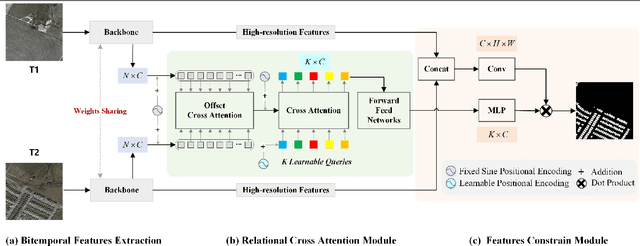
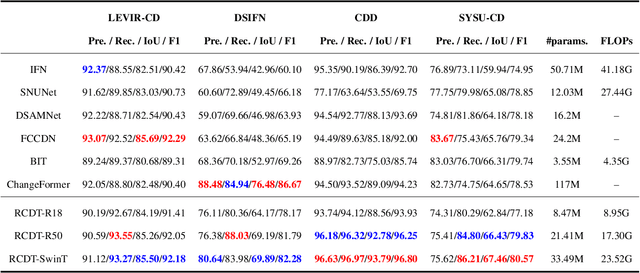
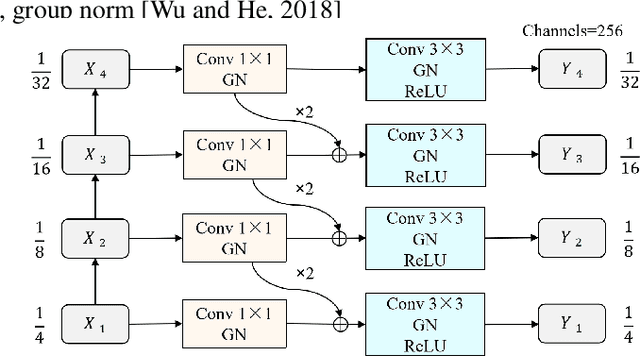
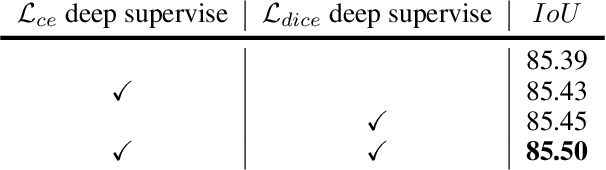
Deep learning based change detection methods have received wide attentoion, thanks to their strong capability in obtaining rich features from images. However, existing AI-based CD methods largely rely on three functionality-enhancing modules, i.e., semantic enhancement, attention mechanisms, and correspondence enhancement. The stacking of these modules leads to great model complexity. To unify these three modules into a simple pipeline, we introduce Relational Change Detection Transformer (RCDT), a novel and simple framework for remote sensing change detection tasks. The proposed RCDT consists of three major components, a weight-sharing Siamese Backbone to obtain bi-temporal features, a Relational Cross Attention Module (RCAM) that implements offset cross attention to obtain bi-temporal relation-aware features, and a Features Constrain Module (FCM) to achieve the final refined predictions with high-resolution constraints. Extensive experiments on four different publically available datasets suggest that our proposed RCDT exhibits superior change detection performance compared with other competing methods. The therotical, methodogical, and experimental knowledge of this study is expected to benefit future change detection efforts that involve the cross attention mechanism.