 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePattern Integration and Enhancement Vision Transformer for Self-Supervised Learning in Remote Sensing
Nov 09, 2024



Recent self-supervised learning (SSL) methods have demonstrated impressive results in learning visual representations from unlabeled remote sensing images. However, most remote sensing images predominantly consist of scenographic scenes containing multiple ground objects without explicit foreground targets, which limits the performance of existing SSL methods that focus on foreground targets. This raises the question: Is there a method that can automatically aggregate similar objects within scenographic remote sensing images, thereby enabling models to differentiate knowledge embedded in various geospatial patterns for improved feature representation? In this work, we present the Pattern Integration and Enhancement Vision Transformer (PIEViT), a novel self-supervised learning framework designed specifically for remote sensing imagery. PIEViT utilizes a teacher-student architecture to address both image-level and patch-level tasks. It employs the Geospatial Pattern Cohesion (GPC) module to explore the natural clustering of patches, enhancing the differentiation of individual features. The Feature Integration Projection (FIP) module further refines masked token reconstruction using geospatially clustered patches. We validated PIEViT across multiple downstream tasks, including object detection, semantic segmentation, and change detection. Experiments demonstrated that PIEViT enhances the representation of internal patch features, providing significant improvements over existing self-supervised baselines. It achieves excellent results in object detection, land cover classification, and change detection, underscoring its robustness, generalization, and transferability for remote sensing image interpretation tasks.
Dynamic Loss Decay based Robust Oriented Object Detection on Remote Sensing Images with Noisy Labels
May 15, 2024
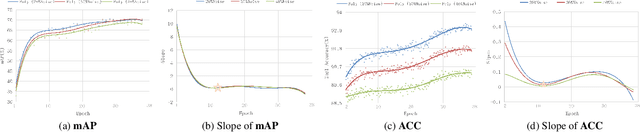

The ambiguous appearance, tiny scale, and fine-grained classes of objects in remote sensing imagery inevitably lead to the noisy annotations in category labels of detection dataset. However, the effects and treatments of the label noises are underexplored in modern oriented remote sensing object detectors. To address this issue, we propose a robust oriented remote sensing object detection method through dynamic loss decay (DLD) mechanism, inspired by the two phase ``early-learning'' and ``memorization'' learning dynamics of deep neural networks on clean and noisy samples. To be specific, we first observe the end point of early learning phase termed as EL, after which the models begin to memorize the false labels that significantly degrade the detection accuracy. Secondly, under the guidance of the training indicator, the losses of each sample are ranked in descending order, and we adaptively decay the losses of the top K largest ones (bad samples) in the following epochs. Because these large losses are of high confidence to be calculated with wrong labels. Experimental results show that the method achieves excellent noise resistance performance tested on multiple public datasets such as HRSC2016 and DOTA-v1.0/v2.0 with synthetic category label noise. Our solution also has won the 2st place in the "fine-grained object detection based on sub-meter remote sensing imagery" track with noisy labels of 2023 National Big Data and Computing Intelligence Challenge.