 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultimodal Collaboration Networks for Geospatial Vehicle Detection in Dense, Occluded, and Large-Scale Events
May 14, 2024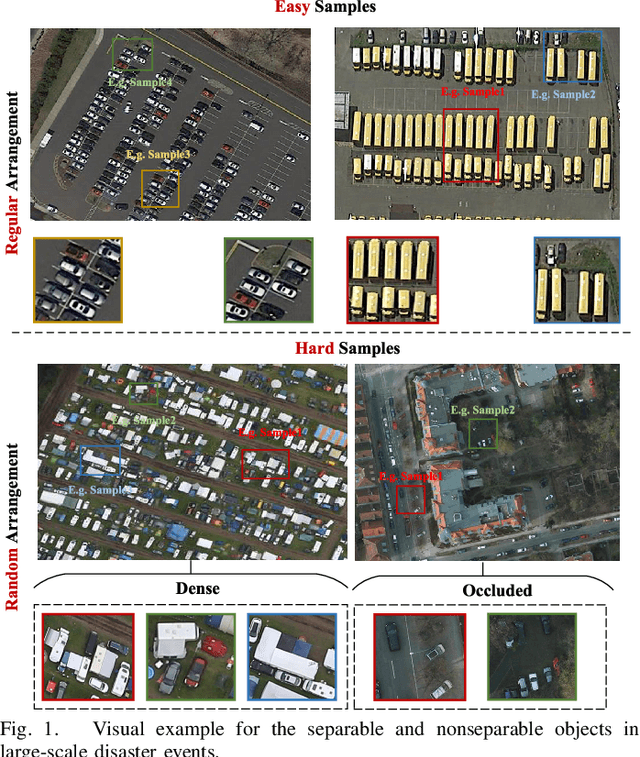

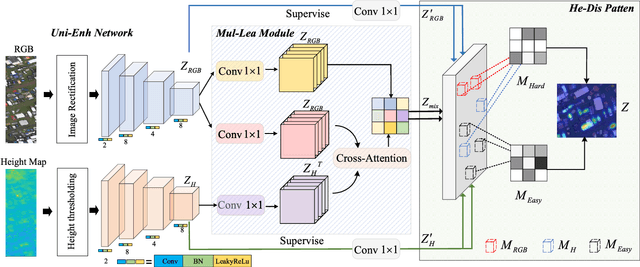
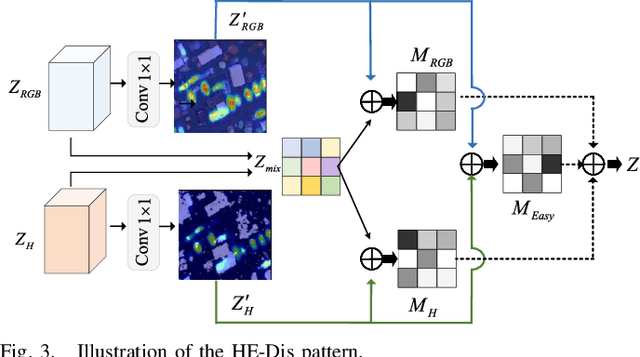
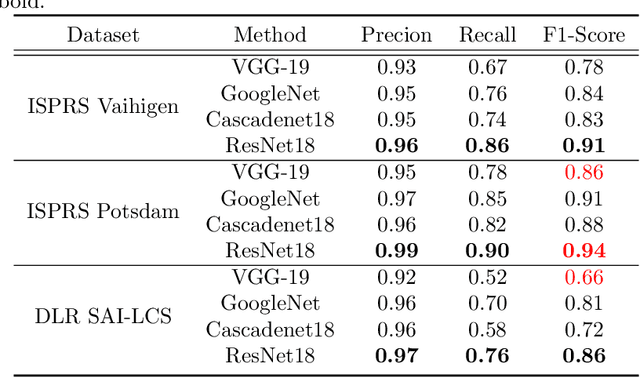
In large-scale disaster events, the planning of optimal rescue routes depends on the object detection ability at the disaster scene, with one of the main challenges being the presence of dense and occluded objects. Existing methods, which are typically based on the RGB modality, struggle to distinguish targets with similar colors and textures in crowded environments and are unable to identify obscured objects. To this end, we first construct two multimodal dense and occlusion vehicle detection datasets for large-scale events, utilizing RGB and height map modalities. Based on these datasets, we propose a multimodal collaboration network for dense and occluded vehicle detection, MuDet for short. MuDet hierarchically enhances the completeness of discriminable information within and across modalities and differentiates between simple and complex samples. MuDet includes three main modules: Unimodal Feature Hierarchical Enhancement (Uni-Enh), Multimodal Cross Learning (Mul-Lea), and Hard-easy Discriminative (He-Dis) Pattern. Uni-Enh and Mul-Lea enhance the features within each modality and facilitate the cross-integration of features from two heterogeneous modalities. He-Dis effectively separates densely occluded vehicle targets with significant intra-class differences and minimal inter-class differences by defining and thresholding confidence values, thereby suppressing the complex background. Experimental results on two re-labeled multimodal benchmark datasets, the 4K-SAI-LCS dataset, and the ISPRS Potsdam dataset, demonstrate the robustness and generalization of the MuDet. The codes of this work are available openly at \url{https://github.com/Shank2358/MuDet}.
Vehicle Detection of Multi-source Remote Sensing Data Using Active Fine-tuning Network
Jul 16, 2020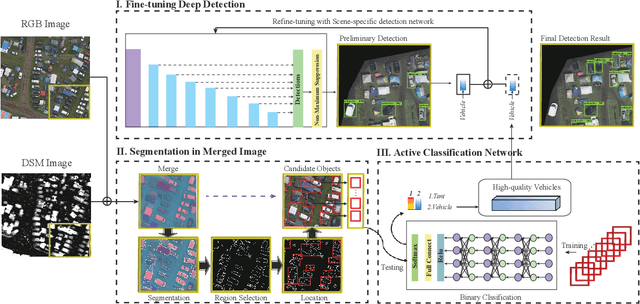
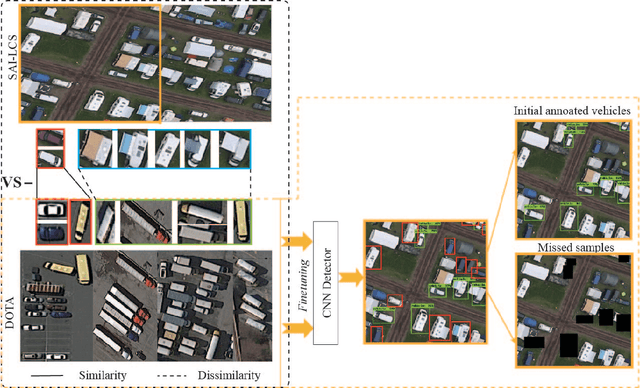
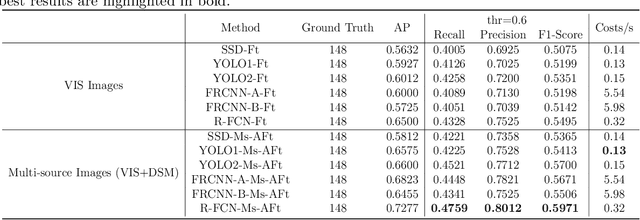
Vehicle detection in remote sensing images has attracted increasing interest in recent years. However, its detection ability is limited due to lack of well-annotated samples, especially in densely crowded scenes. Furthermore, since a list of remotely sensed data sources is available, efficient exploitation of useful information from multi-source data for better vehicle detection is challenging. To solve the above issues, a multi-source active fine-tuning vehicle detection (Ms-AFt) framework is proposed, which integrates transfer learning, segmentation, and active classification into a unified framework for auto-labeling and detection. The proposed Ms-AFt employs a fine-tuning network to firstly generate a vehicle training set from an unlabeled dataset. To cope with the diversity of vehicle categories, a multi-source based segmentation branch is then designed to construct additional candidate object sets. The separation of high quality vehicles is realized by a designed attentive classifications network. Finally, all three branches are combined to achieve vehicle detection. Extensive experimental results conducted on two open ISPRS benchmark datasets, namely the Vaihingen village and Potsdam city datasets, demonstrate the superiority and effectiveness of the proposed Ms-AFt for vehicle detection. In addition, the generalization ability of Ms-AFt in dense remote sensing scenes is further verified on stereo aerial imagery of a large camping site.
A Review of Point Cloud Semantic Segmentation
Sep 03, 2019
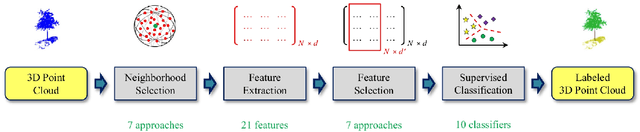
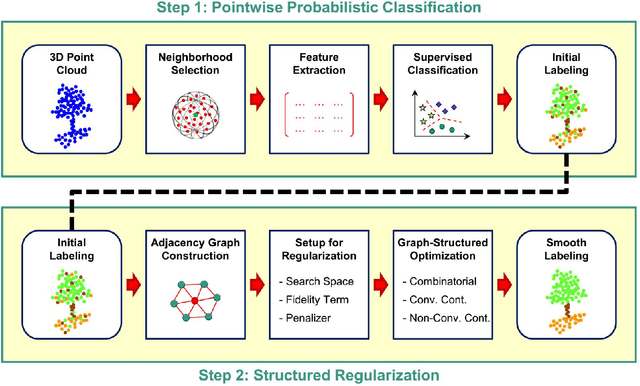
3D Point Cloud Semantic Segmentation (PCSS) is attracting increasing interest, due to its applicability in remote sensing, computer vision and robotics, and due to the new possibilities offered by deep learning techniques. In order to provide a needed up-to-date review of recent developments in PCSS, this article summarizes existing studies on this topic. Firstly, we outline the acquisition and evolution of the 3D point cloud from the perspective of remote sensing and computer vision, as well as the published benchmarks for PCSS studies. Then, traditional and advanced techniques used for Point Cloud Segmentation (PCS) and PCSS are reviewed and compared. Finally, important issues and open questions in PCSS studies are discussed.
ORSIm Detector: A Novel Object Detection Framework in Optical Remote Sensing Imagery Using Spatial-Frequency Channel Features
Jan 31, 2019
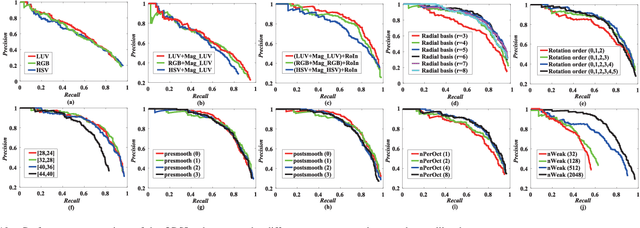
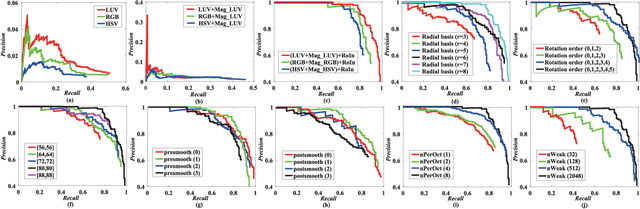
With the rapid development of spaceborne imaging techniques, object detection in optical remote sensing imagery has drawn much attention in recent decades. While many advanced works have been developed with powerful learning algorithms, the incomplete feature representation still cannot meet the demand for effectively and efficiently handling image deformations, particularly objective scaling and rotation. To this end, we propose a novel object detection framework, called optical remote sensing imagery detector (ORSIm detector), integrating diverse channel features extraction, feature learning, fast image pyramid matching, and boosting strategy. ORSIm detector adopts a novel spatial-frequency channel feature (SFCF) by jointly considering the rotation-invariant channel features constructed in frequency domain and the original spatial channel features (e.g., color channel, gradient magnitude). Subsequently, we refine SFCF using learning-based strategy in order to obtain the high-level or semantically meaningful features. In the test phase, we achieve a fast and coarsely-scaled channel computation by mathematically estimating a scaling factor in the image domain. Extensive experimental results conducted on the two different airborne datasets are performed to demonstrate the superiority and effectiveness in comparison with previous state-of-the-art methods.