 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGlobal-Local Detail Guided Transformer for Sea Ice Recognition in Optical Remote Sensing Images
May 21, 2024



The recognition of sea ice is of great significance for reflecting climate change and ensuring the safety of ship navigation. Recently, many deep learning based methods have been proposed and applied to segment and recognize sea ice regions. However, the diverse scales of sea ice areas, the zigzag and fine edge contours, and the difficulty in distinguishing different types of sea ice pose challenges to existing sea ice recognition models. In this paper, a Global-Local Detail Guided Transformer (GDGT) method is proposed for sea ice recognition in optical remote sensing images. In GDGT, a global-local feature fusiont mechanism is designed to fuse global structural correlation features and local spatial detail features. Furthermore, a detail-guided decoder is developed to retain more high-resolution detail information during feature reconstruction for improving the performance of sea ice recognition. Experiments on the produced sea ice dataset demonstrated the effectiveness and advancement of GDGT.
* 5 pages, 5 figures
Multimodal Collaboration Networks for Geospatial Vehicle Detection in Dense, Occluded, and Large-Scale Events
May 14, 2024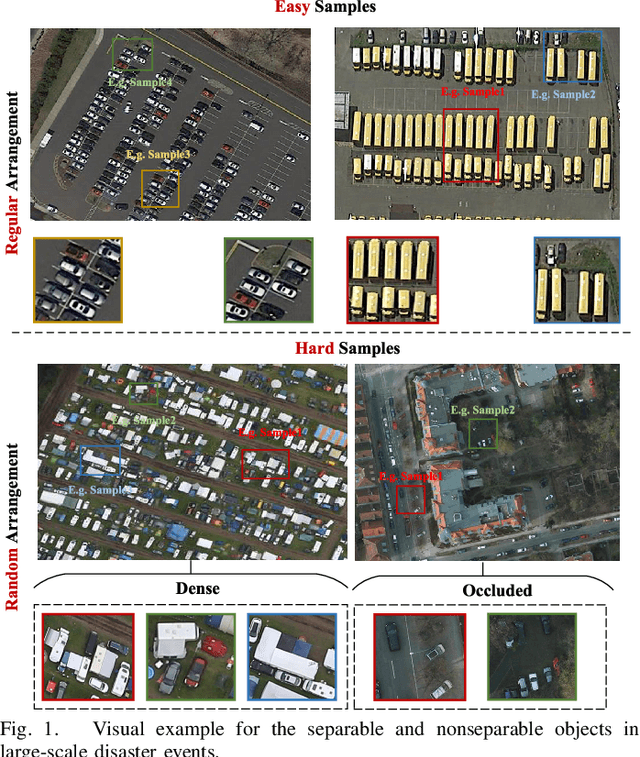

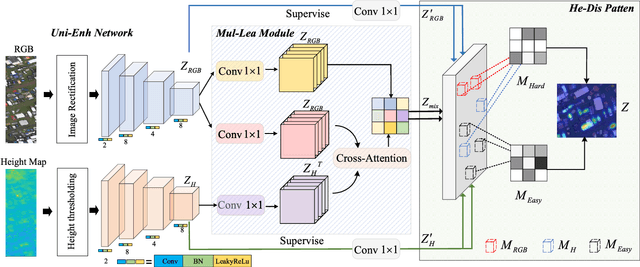
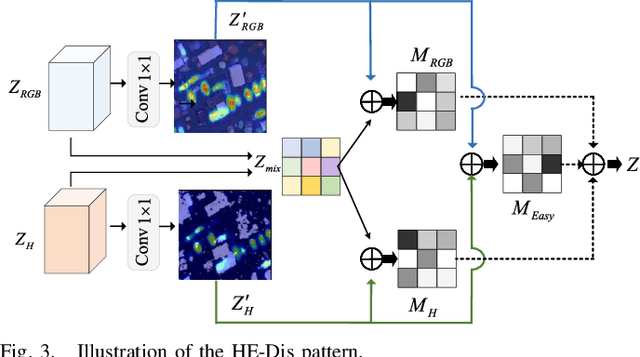
In large-scale disaster events, the planning of optimal rescue routes depends on the object detection ability at the disaster scene, with one of the main challenges being the presence of dense and occluded objects. Existing methods, which are typically based on the RGB modality, struggle to distinguish targets with similar colors and textures in crowded environments and are unable to identify obscured objects. To this end, we first construct two multimodal dense and occlusion vehicle detection datasets for large-scale events, utilizing RGB and height map modalities. Based on these datasets, we propose a multimodal collaboration network for dense and occluded vehicle detection, MuDet for short. MuDet hierarchically enhances the completeness of discriminable information within and across modalities and differentiates between simple and complex samples. MuDet includes three main modules: Unimodal Feature Hierarchical Enhancement (Uni-Enh), Multimodal Cross Learning (Mul-Lea), and Hard-easy Discriminative (He-Dis) Pattern. Uni-Enh and Mul-Lea enhance the features within each modality and facilitate the cross-integration of features from two heterogeneous modalities. He-Dis effectively separates densely occluded vehicle targets with significant intra-class differences and minimal inter-class differences by defining and thresholding confidence values, thereby suppressing the complex background. Experimental results on two re-labeled multimodal benchmark datasets, the 4K-SAI-LCS dataset, and the ISPRS Potsdam dataset, demonstrate the robustness and generalization of the MuDet. The codes of this work are available openly at \url{https://github.com/Shank2358/MuDet}.
LO-Det: Lightweight Oriented Object Detection in Remote Sensing Images
Sep 16, 2022


A few lightweight convolutional neural network (CNN) models have been recently designed for remote sensing object detection (RSOD). However, most of them simply replace vanilla convolutions with stacked separable convolutions, which may not be efficient due to a lot of precision losses and may not be able to detect oriented bounding boxes (OBB). Also, the existing OBB detection methods are difficult to constrain the shape of objects predicted by CNNs accurately. In this paper, we propose an effective lightweight oriented object detector (LO-Det). Specifically, a channel separation-aggregation (CSA) structure is designed to simplify the complexity of stacked separable convolutions, and a dynamic receptive field (DRF) mechanism is developed to maintain high accuracy by customizing the convolution kernel and its perception range dynamically when reducing the network complexity. The CSA-DRF component optimizes efficiency while maintaining high accuracy. Then, a diagonal support constraint head (DSC-Head) component is designed to detect OBBs and constrain their shapes more accurately and stably. Extensive experiments on public datasets demonstrate that the proposed LO-Det can run very fast even on embedded devices with the competitive accuracy of detecting oriented objects.
* 15 pages
Multi-Grained Angle Representation for Remote Sensing Object Detection
Sep 07, 2022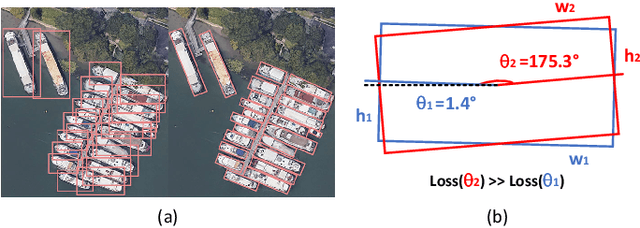
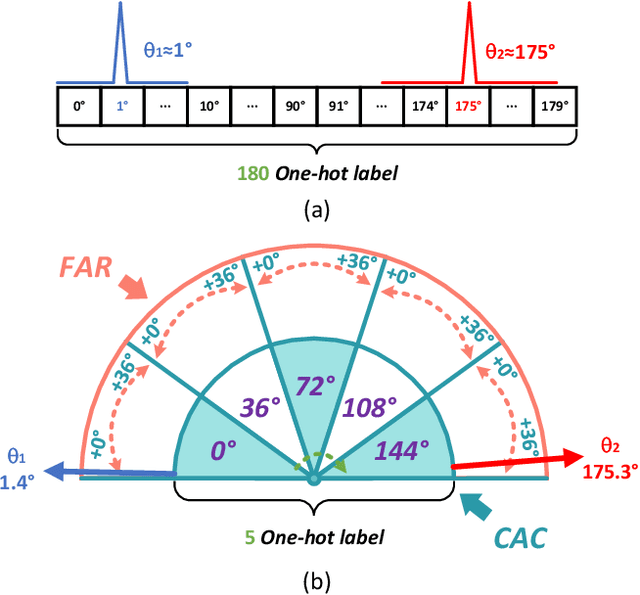
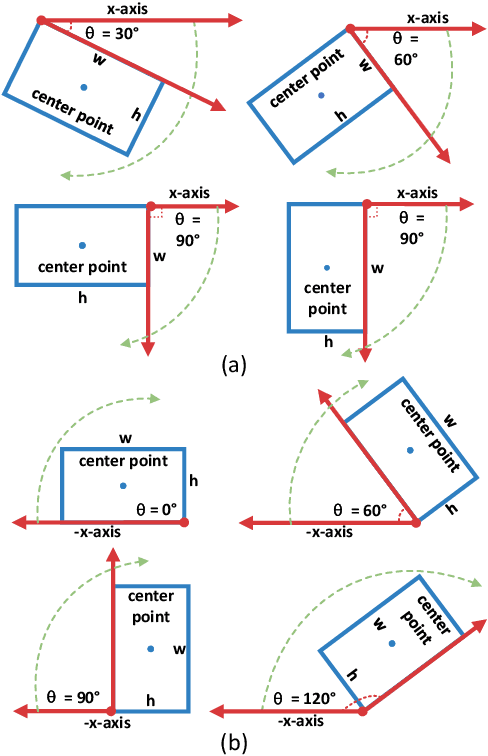
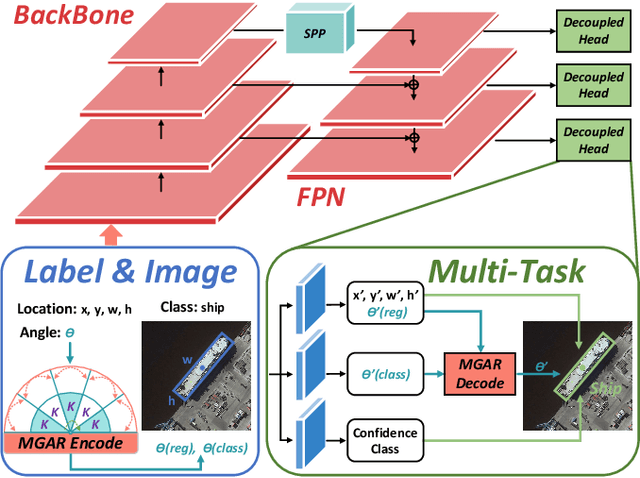
Arbitrary-oriented object detection (AOOD) plays a significant role for image understanding in remote sensing scenarios. The existing AOOD methods face the challenges of ambiguity and high costs in angle representation. To this end, a multi-grained angle representation (MGAR) method, consisting of coarse-grained angle classification (CAC) and fine-grained angle regression (FAR), is proposed. Specifically, the designed CAC avoids the ambiguity of angle prediction by discrete angular encoding (DAE) and reduces complexity by coarsening the granularity of DAE. Based on CAC, FAR is developed to refine the angle prediction with much lower costs than narrowing the granularity of DAE. Furthermore, an Intersection over Union (IoU) aware FAR-Loss (IFL) is designed to improve accuracy of angle prediction using an adaptive re-weighting mechanism guided by IoU. Extensive experiments are performed on several public remote sensing datasets, which demonstrate the effectiveness of the proposed MGAR. Moreover, experiments on embedded devices demonstrate that the proposed MGAR is also friendly for lightweight deployments.
Task-wise Sampling Convolutions for Arbitrary-Oriented Object Detection in Aerial Images
Sep 06, 2022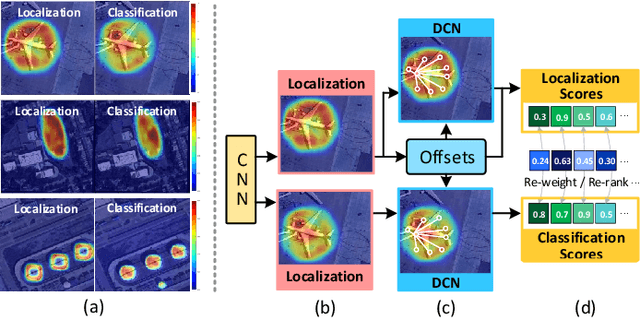

Arbitrary-oriented object detection (AOOD) has been widely applied to locate and classify objects with diverse orientations in remote sensing images. However, the inconsistent features for the localization and classification tasks in AOOD models may lead to ambiguity and low-quality object predictions, which constrains the detection performance. In this paper, an AOOD method called task-wise sampling convolutions (TS-Conv) is proposed. TS-Conv adaptively samples task-wise features from respective sensitive regions and maps these features together in alignment to guide a dynamic label assignment for better predictions. Specifically, sampling positions of the localization convolution in TS-Conv is supervised by the oriented bounding box (OBB) prediction associated with spatial coordinates. While sampling positions and convolutional kernel of the classification convolution are designed to be adaptively adjusted according to different orientations for improving the orientation robustness of features. Furthermore, a dynamic task-aware label assignment (DTLA) strategy is developed to select optimal candidate positions and assign labels dynamicly according to ranked task-aware scores obtained from TS-Conv. Extensive experiments on several public datasets covering multiple scenes, multimodal images, and multiple categories of objects demonstrate the effectiveness, scalability and superior performance of the proposed TS-Conv.
MPANet: Multi-Patch Attention For Infrared Small Target object Detection
Jun 05, 2022
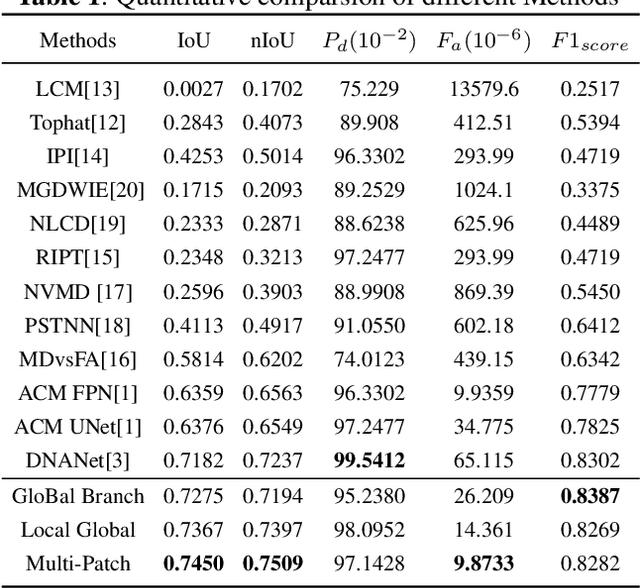


Infrared small target detection (ISTD) has attracted widespread attention and been applied in various fields. Due to the small size of infrared targets and the noise interference from complex backgrounds, the performance of ISTD using convolutional neural networks (CNNs) is restricted. Moreover, the constriant that long-distance dependent features can not be encoded by the vanilla CNNs also impairs the robustness of capturing targets' shapes and locations in complex scenarios. To this end, a multi-patch attention network (MPANet) based on the axial-attention encoder and the multi-scale patch branch (MSPB) structure is proposed. Specially, an axial-attention-improved encoder architecture is designed to highlight the effective features of small targets and suppress background noises. Furthermore, the developed MSPB structure fuses the coarse-grained and fine-grained features from different semantic scales. Extensive experiments on the SIRST dataset show the superiority performance and effectiveness of the proposed MPANet compared to the state-of-the-art methods.
* 4 pages 3 figures
A General Gaussian Heatmap Labeling for Arbitrary-Oriented Object Detection
Sep 27, 2021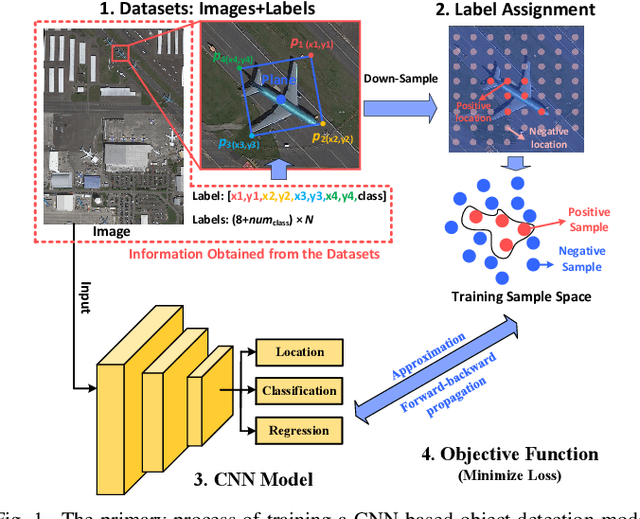



Recently, many arbitrary-oriented object detection (AOOD) methods have been proposed and attracted widespread attention in many fields. However, most of them are based on anchor-boxes or standard Gaussian heatmaps. Such label assignment strategy may not only fail to reflect the shape and direction characteristics of arbitrary-oriented objects, but also have high parameter-tuning efforts. In this paper, a novel AOOD method called General Gaussian Heatmap Labeling (GGHL) is proposed. Specifically, an anchor-free object-adaptation label assignment (OLA) strategy is presented to define the positive candidates based on two-dimensional (2-D) oriented Gaussian heatmaps, which reflect the shape and direction features of arbitrary-oriented objects. Based on OLA, an oriented-bounding-box (OBB) representation component (ORC) is developed to indicate OBBs and adjust the Gaussian center prior weights to fit the characteristics of different objects adaptively through neural network learning. Moreover, a joint-optimization loss (JOL) with area normalization and dynamic confidence weighting is designed to refine the misalign optimal results of different subtasks. Extensive experiments on public datasets demonstrate that the proposed GGHL improves the AOOD performance with low parameter-tuning and time costs. Furthermore, it is generally applicable to most AOOD methods to improve their performance including lightweight models on embedded platforms.
DC-SPP-YOLO: Dense Connection and Spatial Pyramid Pooling Based YOLO for Object Detection
Mar 20, 2019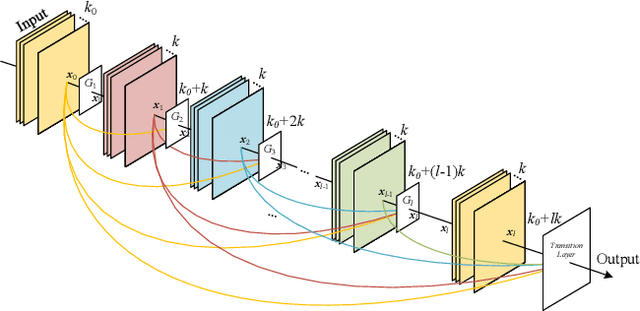
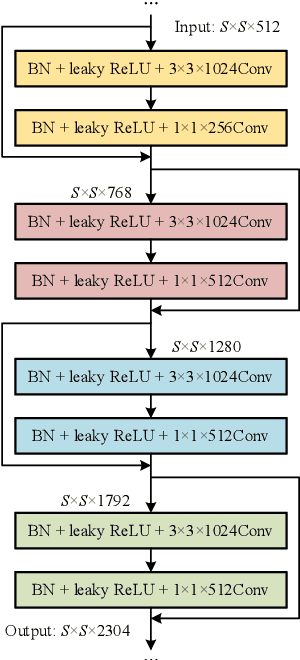
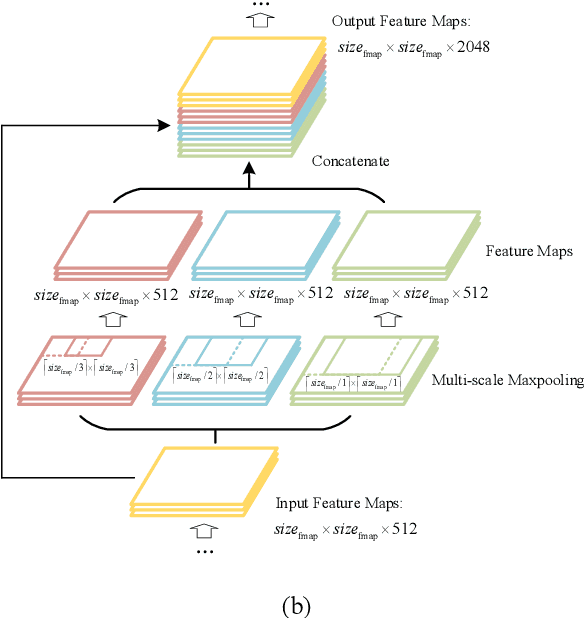
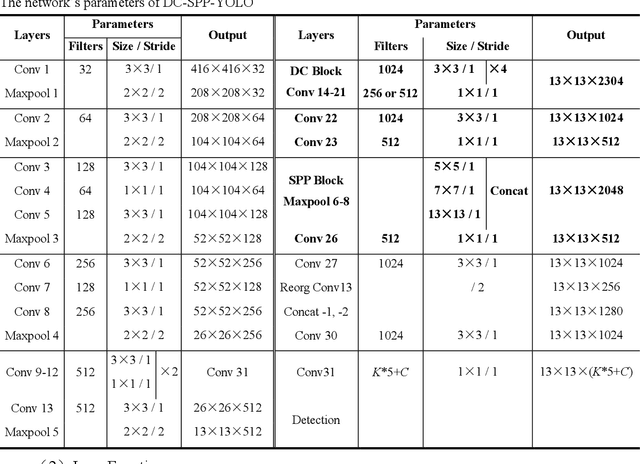
Although YOLOv2 approach is extremely fast on object detection; its backbone network has the low ability on feature extraction and fails to make full use of multi-scale local region features, which restricts the improvement of object detection accuracy. Therefore, this paper proposed a DC-SPP-YOLO (Dense Connection and Spatial Pyramid Pooling Based YOLO) approach for ameliorating the object detection accuracy of YOLOv2. Specifically, the dense connection of convolution layers is employed in the backbone network of YOLOv2 to strengthen the feature extraction and alleviate the vanishing-gradient problem. Moreover, an improved spatial pyramid pooling is introduced to pool and concatenate the multi-scale local region features, so that the network can learn the object features more comprehensively. The DC-SPP-YOLO model is established and trained based on a new loss function composed of mean square error and cross entropy, and the object detection is realized. Experiments demonstrate that the mAP (mean Average Precision) of DC-SPP-YOLO proposed on PASCAL VOC datasets and UA-DETRAC datasets is higher than that of YOLOv2; the object detection accuracy of DC-SPP-YOLO is superior to YOLOv2 by strengthening feature extraction and using the multi-scale local region features.