 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChange3D: Revisiting Change Detection and Captioning from A Video Modeling Perspective
Mar 24, 2025In this paper, we present Change3D, a framework that reconceptualizes the change detection and captioning tasks through video modeling. Recent methods have achieved remarkable success by regarding each pair of bi-temporal images as separate frames. They employ a shared-weight image encoder to extract spatial features and then use a change extractor to capture differences between the two images. However, image feature encoding, being a task-agnostic process, cannot attend to changed regions effectively. Furthermore, different change extractors designed for various change detection and captioning tasks make it difficult to have a unified framework. To tackle these challenges, Change3D regards the bi-temporal images as comprising two frames akin to a tiny video. By integrating learnable perception frames between the bi-temporal images, a video encoder enables the perception frames to interact with the images directly and perceive their differences. Therefore, we can get rid of the intricate change extractors, providing a unified framework for different change detection and captioning tasks. We verify Change3D on multiple tasks, encompassing change detection (including binary change detection, semantic change detection, and building damage assessment) and change captioning, across eight standard benchmarks. Without bells and whistles, this simple yet effective framework can achieve superior performance with an ultra-light video model comprising only ~6%-13% of the parameters and ~8%-34% of the FLOPs compared to state-of-the-art methods. We hope that Change3D could be an alternative to 2D-based models and facilitate future research.
ChangeViT: Unleashing Plain Vision Transformers for Change Detection
Jun 18, 2024
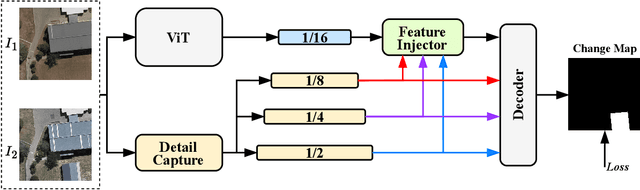


Change detection in remote sensing images is essential for tracking environmental changes on the Earth's surface. Despite the success of vision transformers (ViTs) as backbones in numerous computer vision applications, they remain underutilized in change detection, where convolutional neural networks (CNNs) continue to dominate due to their powerful feature extraction capabilities. In this paper, our study uncovers ViTs' unique advantage in discerning large-scale changes, a capability where CNNs fall short. Capitalizing on this insight, we introduce ChangeViT, a framework that adopts a plain ViT backbone to enhance the performance of large-scale changes. This framework is supplemented by a detail-capture module that generates detailed spatial features and a feature injector that efficiently integrates fine-grained spatial information into high-level semantic learning. The feature integration ensures that ChangeViT excels in both detecting large-scale changes and capturing fine-grained details, providing comprehensive change detection across diverse scales. Without bells and whistles, ChangeViT achieves state-of-the-art performance on three popular high-resolution datasets (i.e., LEVIR-CD, WHU-CD, and CLCD) and one low-resolution dataset (i.e., OSCD), which underscores the unleashed potential of plain ViTs for change detection. Furthermore, thorough quantitative and qualitative analyses validate the efficacy of the introduced modules, solidifying the effectiveness of our approach. The source code is available at https://github.com/zhuduowang/ChangeViT.
Context-Sensitive Temporal Feature Learning for Gait Recognition
Apr 08, 2022
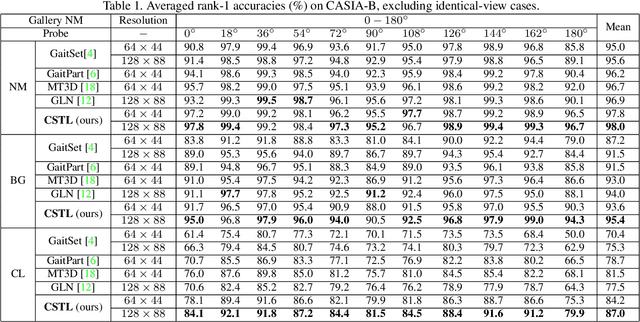

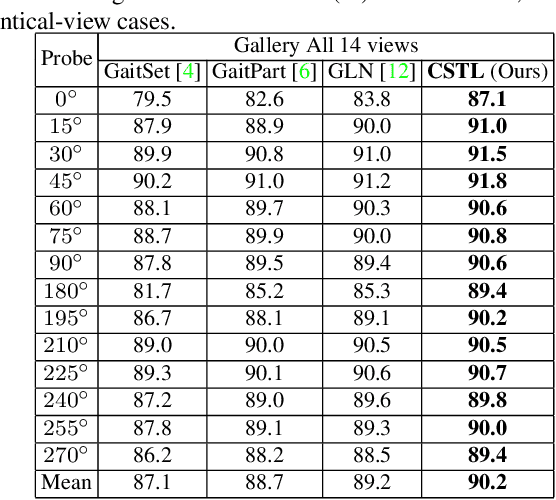
Although gait recognition has drawn increasing research attention recently, it remains challenging to learn discriminative temporal representation, since the silhouette differences are quite subtle in spatial domain. Inspired by the observation that human can distinguish gaits of different subjects by adaptively focusing on temporal clips with different time scales, we propose a context-sensitive temporal feature learning (CSTL) network for gait recognition. CSTL produces temporal features in three scales, and adaptively aggregates them according to the contextual information from local and global perspectives. Specifically, CSTL contains an adaptive temporal aggregation module that subsequently performs local relation modeling and global relation modeling to fuse the multi-scale features. Besides, in order to remedy the spatial feature corruption caused by temporal operations, CSTL incorporates a salient spatial feature learning (SSFL) module to select groups of discriminative spatial features. Particularly, we utilize transformers to implement the global relation modeling and the SSFL module. To the best of our knowledge, this is the first work that adopts transformer in gait recognition. Extensive experiments conducted on three datasets demonstrate the state-of-the-art performance. Concretely, we achieve rank-1 accuracies of 98.7%, 96.2% and 88.7% under normal-walking, bag-carrying and coat-wearing conditions on CASIA-B, 97.5% on OU-MVLP and 50.6% on GREW.