 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContext-Sensitive Temporal Feature Learning for Gait Recognition
Paper and Code

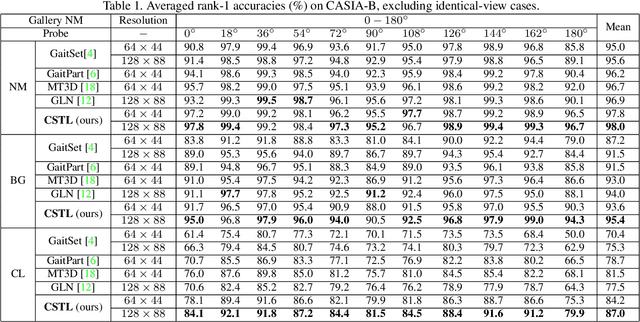

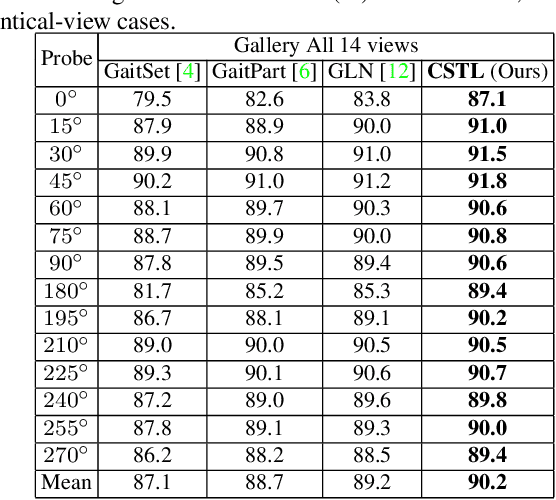
Although gait recognition has drawn increasing research attention recently, it remains challenging to learn discriminative temporal representation, since the silhouette differences are quite subtle in spatial domain. Inspired by the observation that human can distinguish gaits of different subjects by adaptively focusing on temporal clips with different time scales, we propose a context-sensitive temporal feature learning (CSTL) network for gait recognition. CSTL produces temporal features in three scales, and adaptively aggregates them according to the contextual information from local and global perspectives. Specifically, CSTL contains an adaptive temporal aggregation module that subsequently performs local relation modeling and global relation modeling to fuse the multi-scale features. Besides, in order to remedy the spatial feature corruption caused by temporal operations, CSTL incorporates a salient spatial feature learning (SSFL) module to select groups of discriminative spatial features. Particularly, we utilize transformers to implement the global relation modeling and the SSFL module. To the best of our knowledge, this is the first work that adopts transformer in gait recognition. Extensive experiments conducted on three datasets demonstrate the state-of-the-art performance. Concretely, we achieve rank-1 accuracies of 98.7%, 96.2% and 88.7% under normal-walking, bag-carrying and coat-wearing conditions on CASIA-B, 97.5% on OU-MVLP and 50.6% on GREW.