 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHuman Identification at a Distance: Challenges, Methods and Results on the Competition HID 2025
Feb 07, 2026Human identification at a distance (HID) is challenging because traditional biometric modalities such as face and fingerprints are often difficult to acquire in real-world scenarios. Gait recognition provides a practical alternative, as it can be captured reliably at a distance. To promote progress in gait recognition and provide a fair evaluation platform, the International Competition on Human Identification at a Distance (HID) has been organized annually since 2020. Since 2023, the competition has adopted the challenging SUSTech-Competition dataset, which features substantial variations in clothing, carried objects, and view angles. No dedicated training data are provided, requiring participants to train their models using external datasets. Each year, the competition applies a different random seed to generate distinct evaluation splits, which reduces the risk of overfitting and supports a fair assessment of cross-domain generalization. While HID 2023 and HID 2024 already used this dataset, HID 2025 explicitly examined whether algorithmic advances could surpass the accuracy limits observed previously. Despite the heightened difficulty, participants achieved further improvements, and the best-performing method reached 94.2% accuracy, setting a new benchmark on this dataset. We also analyze key technical trends and outline potential directions for future research in gait recognition.
Gait Recognition via Collaborating Discriminative and Generative Diffusion Models
Nov 09, 2025Gait recognition offers a non-intrusive biometric solution by identifying individuals through their walking patterns. Although discriminative models have achieved notable success in this domain, the full potential of generative models remains largely underexplored. In this paper, we introduce \textbf{CoD$^2$}, a novel framework that combines the data distribution modeling capabilities of diffusion models with the semantic representation learning strengths of discriminative models to extract robust gait features. We propose a Multi-level Conditional Control strategy that incorporates both high-level identity-aware semantic conditions and low-level visual details. Specifically, the high-level condition, extracted by the discriminative extractor, guides the generation of identity-consistent gait sequences, whereas low-level visual details, such as appearance and motion, are preserved to enhance consistency. Furthermore, the generated sequences facilitate the discriminative extractor's learning, enabling it to capture more comprehensive high-level semantic features. Extensive experiments on four datasets (SUSTech1K, CCPG, GREW, and Gait3D) demonstrate that CoD$^2$ achieves state-of-the-art performance and can be seamlessly integrated with existing discriminative methods, yielding consistent improvements.
STP4D: Spatio-Temporal-Prompt Consistent Modeling for Text-to-4D Gaussian Splatting
Apr 25, 2025Text-to-4D generation is rapidly developing and widely applied in various scenarios. However, existing methods often fail to incorporate adequate spatio-temporal modeling and prompt alignment within a unified framework, resulting in temporal inconsistencies, geometric distortions, or low-quality 4D content that deviates from the provided texts. Therefore, we propose STP4D, a novel approach that aims to integrate comprehensive spatio-temporal-prompt consistency modeling for high-quality text-to-4D generation. Specifically, STP4D employs three carefully designed modules: Time-varying Prompt Embedding, Geometric Information Enhancement, and Temporal Extension Deformation, which collaborate to accomplish this goal. Furthermore, STP4D is among the first methods to exploit the Diffusion model to generate 4D Gaussians, combining the fine-grained modeling capabilities and the real-time rendering process of 4DGS with the rapid inference speed of the Diffusion model. Extensive experiments demonstrate that STP4D excels in generating high-fidelity 4D content with exceptional efficiency (approximately 4.6s per asset), surpassing existing methods in both quality and speed.
Causality-inspired Discriminative Feature Learning in Triple Domains for Gait Recognition
Jul 17, 2024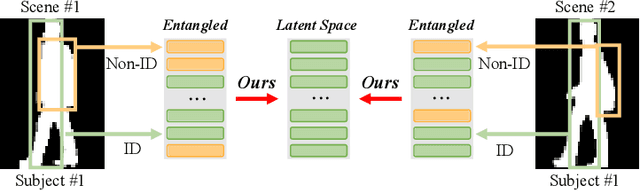
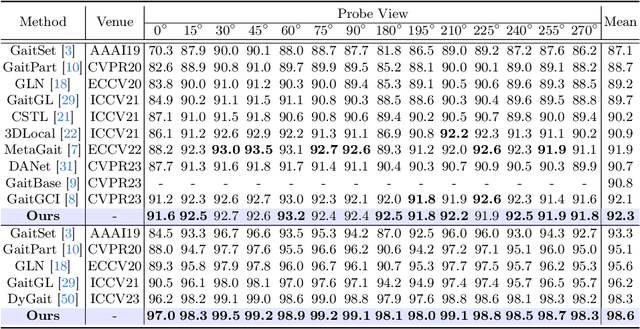
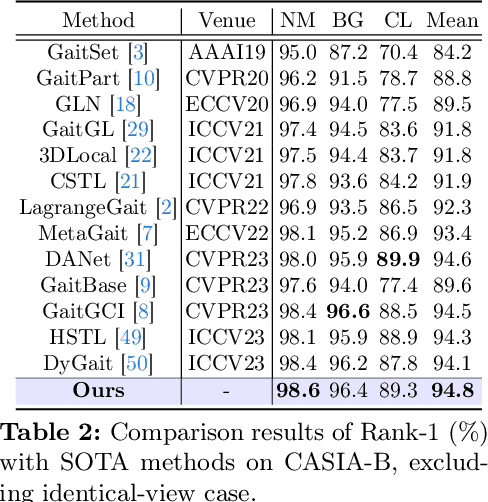
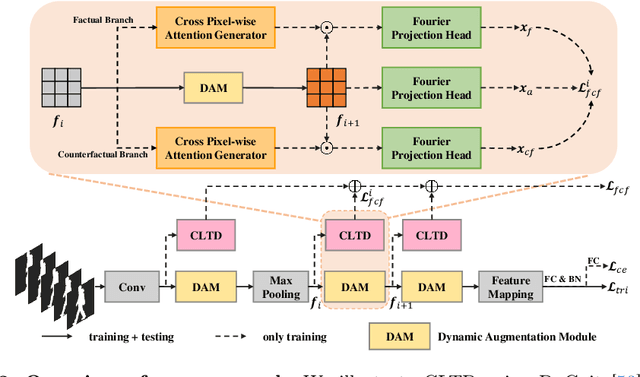
Gait recognition is a biometric technology that distinguishes individuals by their walking patterns. However, previous methods face challenges when accurately extracting identity features because they often become entangled with non-identity clues. To address this challenge, we propose CLTD, a causality-inspired discriminative feature learning module designed to effectively eliminate the influence of confounders in triple domains, \ie, spatial, temporal, and spectral. Specifically, we utilize the Cross Pixel-wise Attention Generator (CPAG) to generate attention distributions for factual and counterfactual features in spatial and temporal domains. Then, we introduce the Fourier Projection Head (FPH) to project spatial features into the spectral space, which preserves essential information while reducing computational costs. Additionally, we employ an optimization method with contrastive learning to enforce semantic consistency constraints across sequences from the same subject. Our approach has demonstrated significant performance improvements on challenging datasets, proving its effectiveness. Moreover, it can be seamlessly integrated into existing gait recognition methods.
LiCAF: LiDAR-Camera Asymmetric Fusion for Gait Recognition
Jun 18, 2024



Gait recognition is a biometric technology that identifies individuals by using walking patterns. Due to the significant achievements of multimodal fusion in gait recognition, we consider employing LiDAR-camera fusion to obtain robust gait representations. However, existing methods often overlook intrinsic characteristics of modalities, and lack fine-grained fusion and temporal modeling. In this paper, we introduce a novel modality-sensitive network LiCAF for LiDAR-camera fusion, which employs an asymmetric modeling strategy. Specifically, we propose Asymmetric Cross-modal Channel Attention (ACCA) and Interlaced Cross-modal Temporal Modeling (ICTM) for cross-modal valuable channel information selection and powerful temporal modeling. Our method achieves state-of-the-art performance (93.9% in Rank-1 and 98.8% in Rank-5) on the SUSTech1K dataset, demonstrating its effectiveness.
GaitGS: Temporal Feature Learning in Granularity and Span Dimension for Gait Recognition
Jun 01, 2023
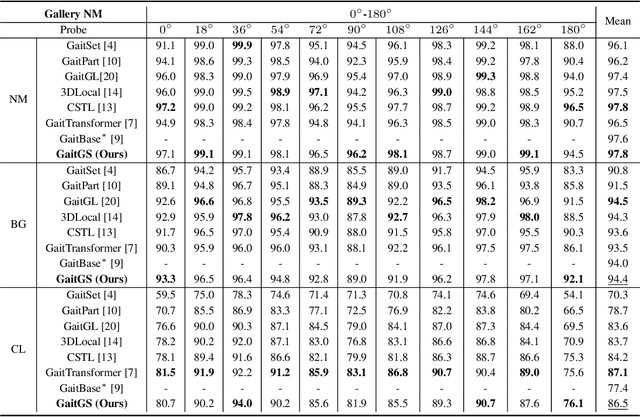
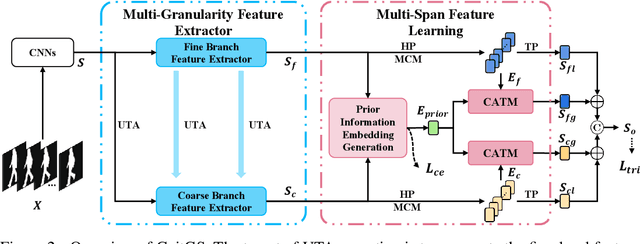
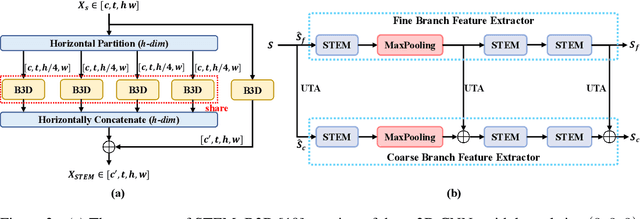
Gait recognition is an emerging biological recognition technology that identifies and verifies individuals based on their walking patterns. However, many current methods are limited in their use of temporal information. In order to fully harness the potential of gait recognition, it is crucial to consider temporal features at various granularities and spans. Hence, in this paper, we propose a novel framework named GaitGS, which aggregates temporal features in the granularity dimension and span dimension simultaneously. Specifically, Multi-Granularity Feature Extractor (MGFE) is proposed to focus on capturing the micro-motion and macro-motion information at the frame level and unit level respectively. Moreover, we present Multi-Span Feature Learning (MSFL) module to generate global and local temporal representations. On three popular gait datasets, extensive experiments demonstrate the state-of-the-art performance of our method. Our method achieves the Rank-1 accuracies of 92.9% (+0.5%), 52.0% (+1.4%), and 97.5% (+0.8%) on CASIA-B, GREW, and OU-MVLP respectively. The source code will be released soon.