 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGO-MLVTON: Garment Occlusion-Aware Multi-Layer Virtual Try-On with Diffusion Models
Jan 20, 2026Existing Image-based virtual try-on (VTON) methods primarily focus on single-layer or multi-garment VTON, neglecting multi-layer VTON (ML-VTON), which involves dressing multiple layers of garments onto the human body with realistic deformation and layering to generate visually plausible outcomes. The main challenge lies in accurately modeling occlusion relationships between inner and outer garments to reduce interference from redundant inner garment features. To address this, we propose GO-MLVTON, the first multi-layer VTON method, introducing the Garment Occlusion Learning module to learn occlusion relationships and the StableDiffusion-based Garment Morphing & Fitting module to deform and fit garments onto the human body, producing high-quality multi-layer try-on results. Additionally, we present the MLG dataset for this task and propose a new metric named Layered Appearance Coherence Difference (LACD) for evaluation. Extensive experiments demonstrate the state-of-the-art performance of GO-MLVTON. Project page: https://upyuyang.github.io/go-mlvton/.
STP4D: Spatio-Temporal-Prompt Consistent Modeling for Text-to-4D Gaussian Splatting
Apr 25, 2025Text-to-4D generation is rapidly developing and widely applied in various scenarios. However, existing methods often fail to incorporate adequate spatio-temporal modeling and prompt alignment within a unified framework, resulting in temporal inconsistencies, geometric distortions, or low-quality 4D content that deviates from the provided texts. Therefore, we propose STP4D, a novel approach that aims to integrate comprehensive spatio-temporal-prompt consistency modeling for high-quality text-to-4D generation. Specifically, STP4D employs three carefully designed modules: Time-varying Prompt Embedding, Geometric Information Enhancement, and Temporal Extension Deformation, which collaborate to accomplish this goal. Furthermore, STP4D is among the first methods to exploit the Diffusion model to generate 4D Gaussians, combining the fine-grained modeling capabilities and the real-time rendering process of 4DGS with the rapid inference speed of the Diffusion model. Extensive experiments demonstrate that STP4D excels in generating high-fidelity 4D content with exceptional efficiency (approximately 4.6s per asset), surpassing existing methods in both quality and speed.
LiCAF: LiDAR-Camera Asymmetric Fusion for Gait Recognition
Jun 18, 2024



Gait recognition is a biometric technology that identifies individuals by using walking patterns. Due to the significant achievements of multimodal fusion in gait recognition, we consider employing LiDAR-camera fusion to obtain robust gait representations. However, existing methods often overlook intrinsic characteristics of modalities, and lack fine-grained fusion and temporal modeling. In this paper, we introduce a novel modality-sensitive network LiCAF for LiDAR-camera fusion, which employs an asymmetric modeling strategy. Specifically, we propose Asymmetric Cross-modal Channel Attention (ACCA) and Interlaced Cross-modal Temporal Modeling (ICTM) for cross-modal valuable channel information selection and powerful temporal modeling. Our method achieves state-of-the-art performance (93.9% in Rank-1 and 98.8% in Rank-5) on the SUSTech1K dataset, demonstrating its effectiveness.
GaitGS: Temporal Feature Learning in Granularity and Span Dimension for Gait Recognition
Jun 01, 2023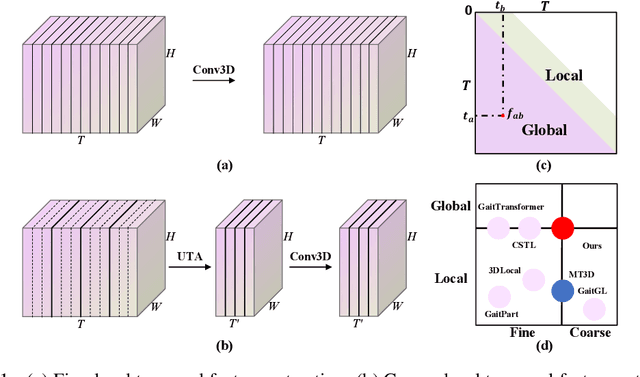
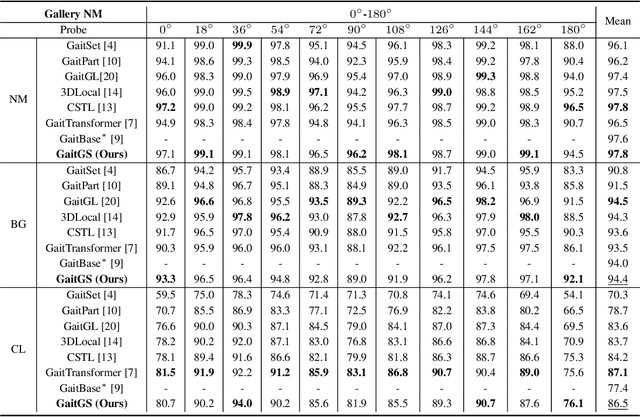
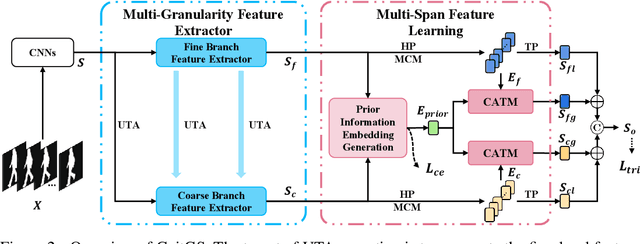
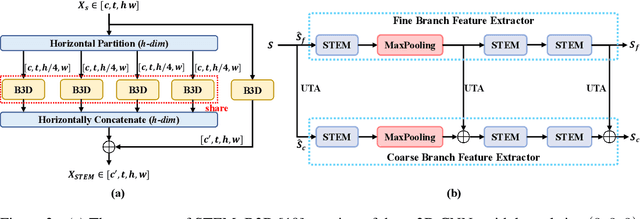
Gait recognition is an emerging biological recognition technology that identifies and verifies individuals based on their walking patterns. However, many current methods are limited in their use of temporal information. In order to fully harness the potential of gait recognition, it is crucial to consider temporal features at various granularities and spans. Hence, in this paper, we propose a novel framework named GaitGS, which aggregates temporal features in the granularity dimension and span dimension simultaneously. Specifically, Multi-Granularity Feature Extractor (MGFE) is proposed to focus on capturing the micro-motion and macro-motion information at the frame level and unit level respectively. Moreover, we present Multi-Span Feature Learning (MSFL) module to generate global and local temporal representations. On three popular gait datasets, extensive experiments demonstrate the state-of-the-art performance of our method. Our method achieves the Rank-1 accuracies of 92.9% (+0.5%), 52.0% (+1.4%), and 97.5% (+0.8%) on CASIA-B, GREW, and OU-MVLP respectively. The source code will be released soon.