 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Principles to Applications: A Comprehensive Survey of Discrete Tokenizers in Generation, Comprehension, Recommendation, and Information Retrieval
Paper and Code
Feb 18, 2025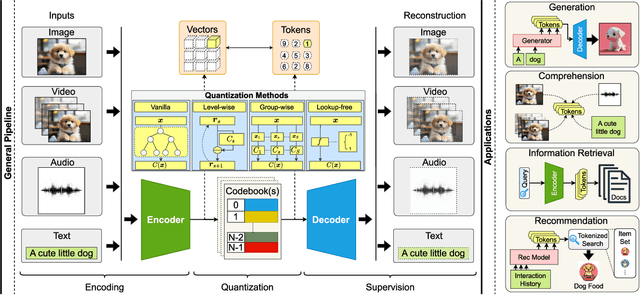
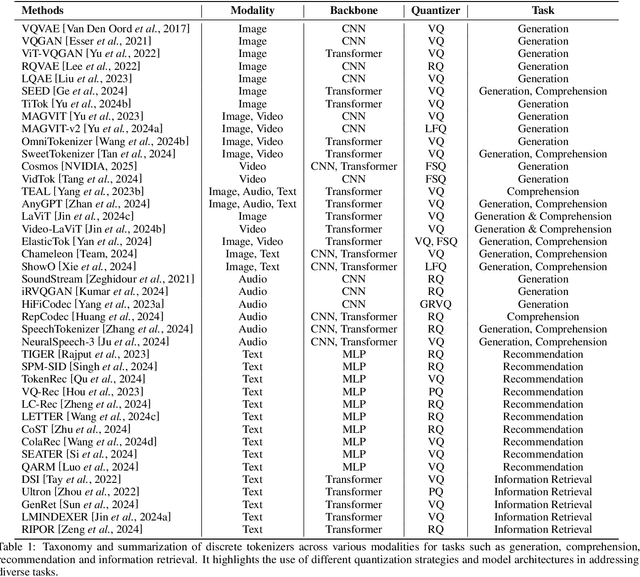
Discrete tokenizers have emerged as indispensable components in modern machine learning systems, particularly within the context of autoregressive modeling and large language models (LLMs). These tokenizers serve as the critical interface that transforms raw, unstructured data from diverse modalities into discrete tokens, enabling LLMs to operate effectively across a wide range of tasks. Despite their central role in generation, comprehension, and recommendation systems, a comprehensive survey dedicated to discrete tokenizers remains conspicuously absent in the literature. This paper addresses this gap by providing a systematic review of the design principles, applications, and challenges of discrete tokenizers. We begin by dissecting the sub-modules of tokenizers and systematically demonstrate their internal mechanisms to provide a comprehensive understanding of their functionality and design. Building on this foundation, we synthesize state-of-the-art methods, categorizing them into multimodal generation and comprehension tasks, and semantic tokens for personalized recommendations. Furthermore, we critically analyze the limitations of existing tokenizers and outline promising directions for future research. By presenting a unified framework for understanding discrete tokenizers, this survey aims to guide researchers and practitioners in addressing open challenges and advancing the field, ultimately contributing to the development of more robust and versatile AI systems.