 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRay Priors through Reprojection: Improving Neural Radiance Fields for Novel View Extrapolation
May 12, 2022
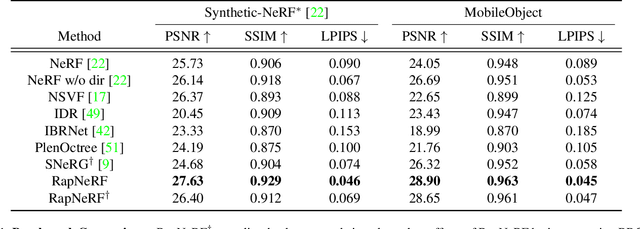
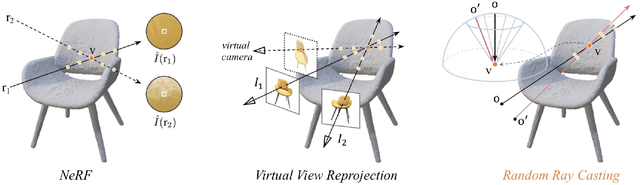
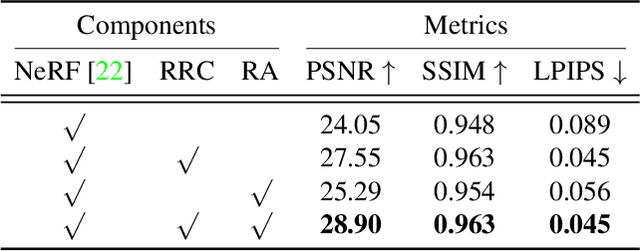
Neural Radiance Fields (NeRF) have emerged as a potent paradigm for representing scenes and synthesizing photo-realistic images. A main limitation of conventional NeRFs is that they often fail to produce high-quality renderings under novel viewpoints that are significantly different from the training viewpoints. In this paper, instead of exploiting few-shot image synthesis, we study the novel view extrapolation setting that (1) the training images can well describe an object, and (2) there is a notable discrepancy between the training and test viewpoints' distributions. We present RapNeRF (RAy Priors) as a solution. Our insight is that the inherent appearances of a 3D surface's arbitrary visible projections should be consistent. We thus propose a random ray casting policy that allows training unseen views using seen views. Furthermore, we show that a ray atlas pre-computed from the observed rays' viewing directions could further enhance the rendering quality for extrapolated views. A main limitation is that RapNeRF would remove the strong view-dependent effects because it leverages the multi-view consistency property.
Modeling Indirect Illumination for Inverse Rendering
Apr 14, 2022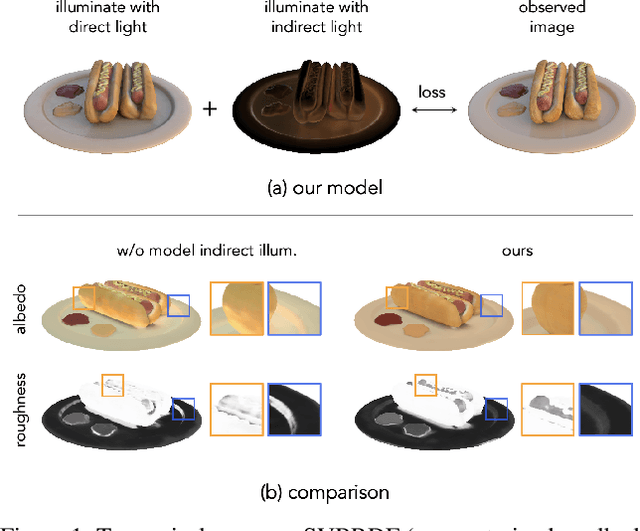
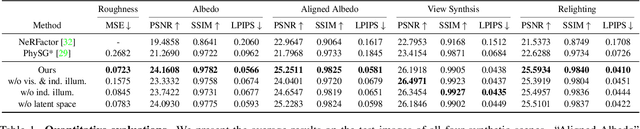
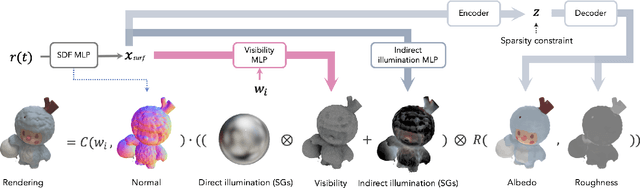
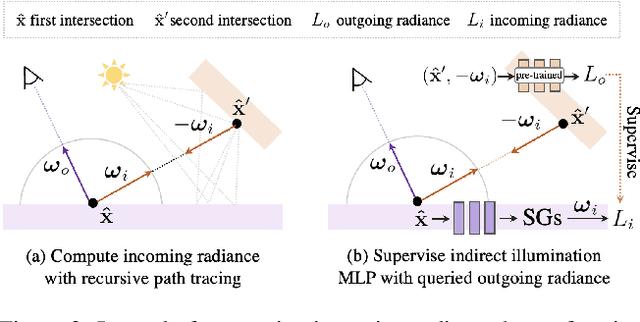
Recent advances in implicit neural representations and differentiable rendering make it possible to simultaneously recover the geometry and materials of an object from multi-view RGB images captured under unknown static illumination. Despite the promising results achieved, indirect illumination is rarely modeled in previous methods, as it requires expensive recursive path tracing which makes the inverse rendering computationally intractable. In this paper, we propose a novel approach to efficiently recovering spatially-varying indirect illumination. The key insight is that indirect illumination can be conveniently derived from the neural radiance field learned from input images instead of being estimated jointly with direct illumination and materials. By properly modeling the indirect illumination and visibility of direct illumination, interreflection- and shadow-free albedo can be recovered. The experiments on both synthetic and real data demonstrate the superior performance of our approach compared to previous work and its capability to synthesize realistic renderings under novel viewpoints and illumination. Our code and data are available at https://zju3dv.github.io/invrender/.
Neural Body: Implicit Neural Representations with Structured Latent Codes for Novel View Synthesis of Dynamic Humans
Dec 31, 2020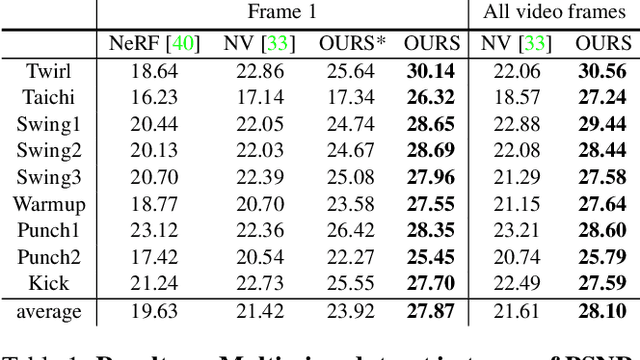
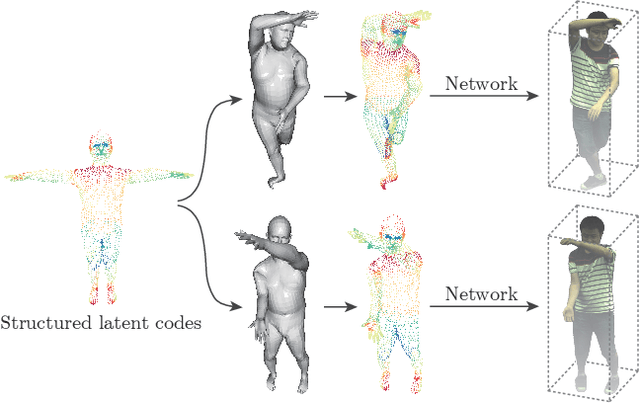
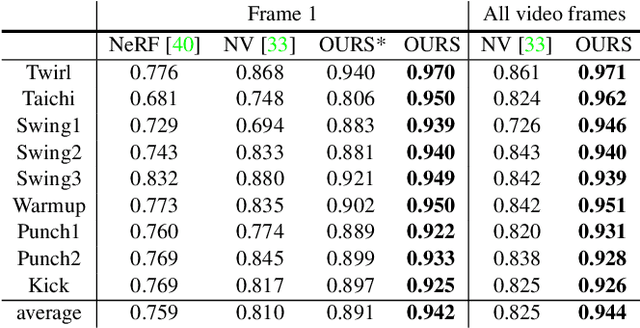
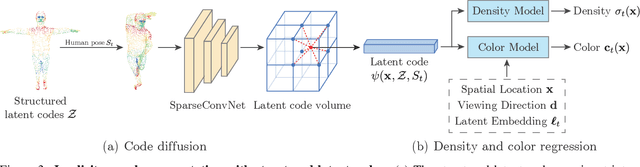
This paper addresses the challenge of novel view synthesis for a human performer from a very sparse set of camera views. Some recent works have shown that learning implicit neural representations of 3D scenes achieves remarkable view synthesis quality given dense input views. However, the representation learning will be ill-posed if the views are highly sparse. To solve this ill-posed problem, our key idea is to integrate observations over video frames. To this end, we propose Neural Body, a new human body representation which assumes that the learned neural representations at different frames share the same set of latent codes anchored to a deformable mesh, so that the observations across frames can be naturally integrated. The deformable mesh also provides geometric guidance for the network to learn 3D representations more efficiently. Experiments on a newly collected multi-view dataset show that our approach outperforms prior works by a large margin in terms of the view synthesis quality. We also demonstrate the capability of our approach to reconstruct a moving person from a monocular video on the People-Snapshot dataset. The code and dataset will be available at https://zju3dv.github.io/neuralbody/.
Motion Capture from Internet Videos
Aug 19, 2020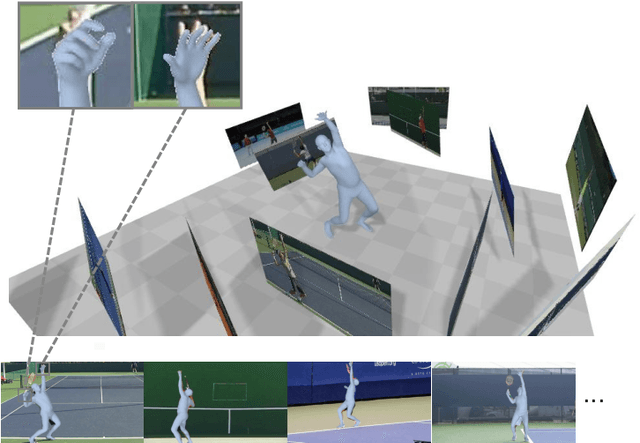
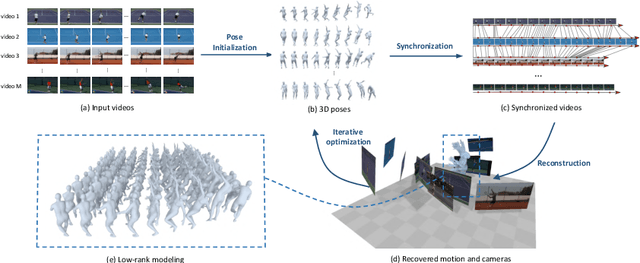

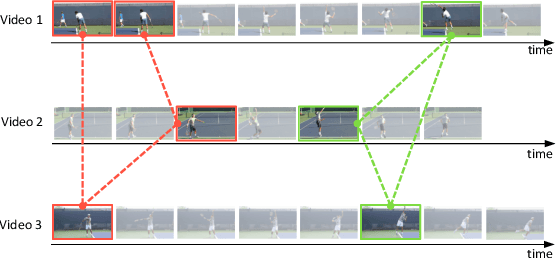
Recent advances in image-based human pose estimation make it possible to capture 3D human motion from a single RGB video. However, the inherent depth ambiguity and self-occlusion in a single view prohibit the recovery of as high-quality motion as multi-view reconstruction. While multi-view videos are not common, the videos of a celebrity performing a specific action are usually abundant on the Internet. Even if these videos were recorded at different time instances, they would encode the same motion characteristics of the person. Therefore, we propose to capture human motion by jointly analyzing these Internet videos instead of using single videos separately. However, this new task poses many new challenges that cannot be addressed by existing methods, as the videos are unsynchronized, the camera viewpoints are unknown, the background scenes are different, and the human motions are not exactly the same among videos. To address these challenges, we propose a novel optimization-based framework and experimentally demonstrate its ability to recover much more precise and detailed motion from multiple videos, compared against monocular motion capture methods.