 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMLLM4PUE: Toward Universal Embeddings in Computational Pathology through Multimodal LLMs
Feb 11, 2025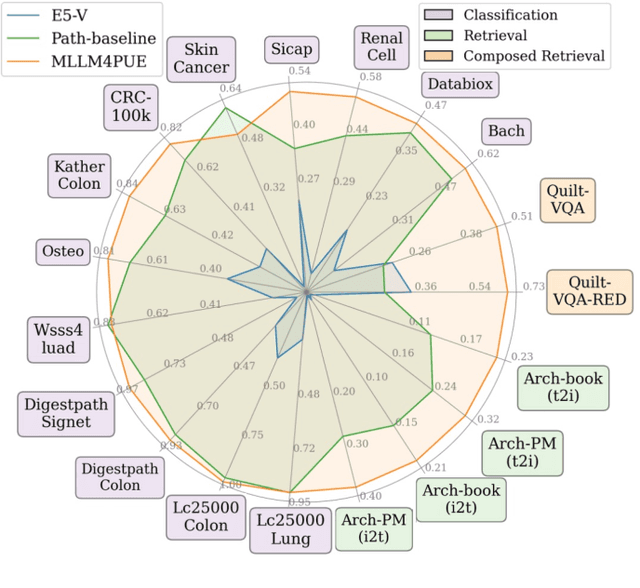
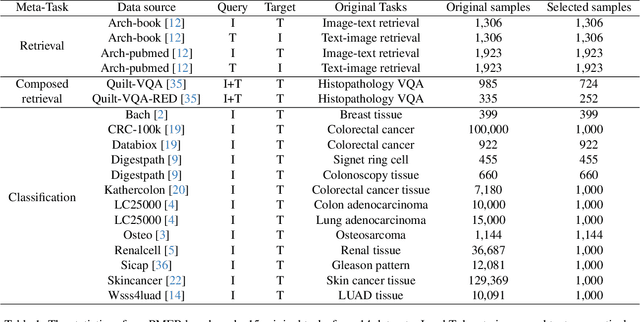
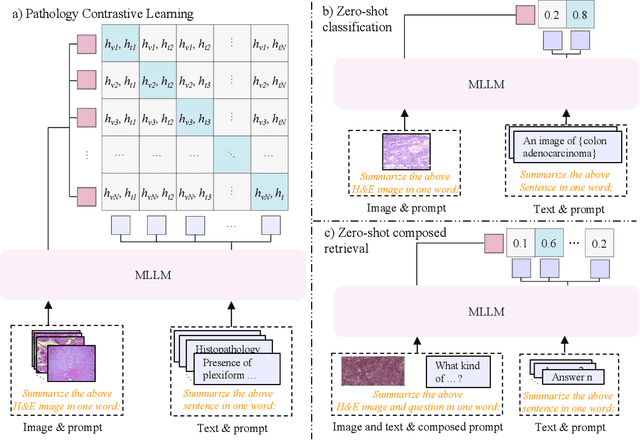
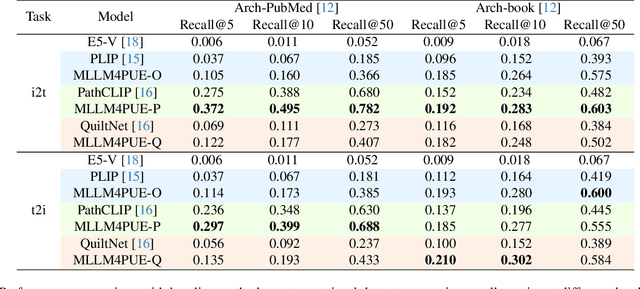
Pathology plays a critical role in diagnosing a wide range of diseases, yet existing approaches often rely heavily on task-specific models trained on extensive, well-labeled datasets. These methods face sustainability challenges due to the diversity of pathologies and the labor-intensive nature of data collection. To address these limitations, we highlight the need for universal multimodal embeddings that can support multiple downstream tasks. Previous approaches often involve fine-tuning CLIP-based models, which handle images and text separately, limiting their ability to capture complex multimodal relationships. Additionally, these models are evaluated across diverse datasets without a unified benchmark for assessing multimodal embeddings in pathology. To address these challenges, we propose MLLM4PUE, a novel framework that leverages Multimodal Large Language Models (MLLMs) to generate Pathology Universal Embeddings. The MLLM4PUE framework not only facilitates robust integration of images and text but also enhances understanding and fusion capabilities across various tasks. We further introduce the Pathology Multimodal Embedding Benchmark (PMEB), a comprehensive benchmark designed to assess the quality of pathology multimodal embeddings. PMEB comprises 15 original tasks drawn from 14 datasets, organized into three meta-tasks: retrieval, classification, and composed retrieval. Experimental results demonstrate the superiority of MLLM4PUE, illustrating MLLM-based models can effectively support a wide range of downstream tasks and unify the research direction for foundation models in pathology.