 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompositional Image Retrieval via Instruction-Aware Contrastive Learning
Dec 07, 2024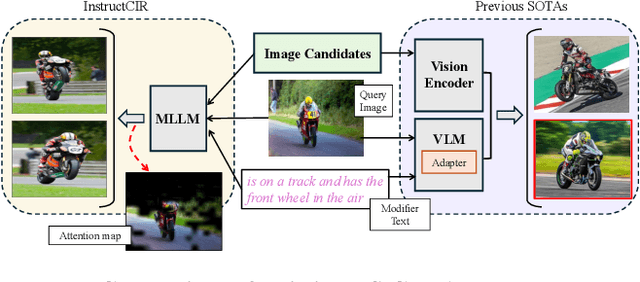
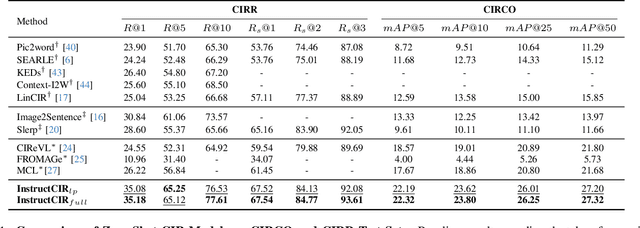

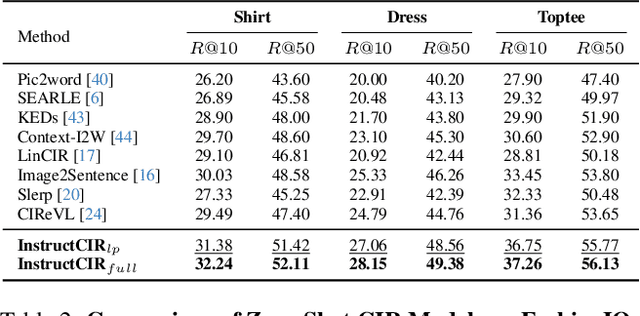
Composed Image Retrieval (CIR) involves retrieving a target image based on a composed query of an image paired with text that specifies modifications or changes to the visual reference. CIR is inherently an instruction-following task, as the model needs to interpret and apply modifications to the image. In practice, due to the scarcity of annotated data in downstream tasks, Zero-Shot CIR (ZS-CIR) is desirable. While existing ZS-CIR models based on CLIP have shown promising results, their capability in interpreting and following modification instructions remains limited. Some research attempts to address this by incorporating Large Language Models (LLMs). However, these approaches still face challenges in effectively integrating multimodal information and instruction understanding. To tackle above challenges, we propose a novel embedding method utilizing an instruction-tuned Multimodal LLM (MLLM) to generate composed representation, which significantly enhance the instruction following capability for a comprehensive integration between images and instructions. Nevertheless, directly applying MLLMs introduces a new challenge since MLLMs are primarily designed for text generation rather than embedding extraction as required in CIR. To address this, we introduce a two-stage training strategy to efficiently learn a joint multimodal embedding space and further refining the ability to follow modification instructions by tuning the model in a triplet dataset similar to the CIR format. Extensive experiments on four public datasets: FashionIQ, CIRR, GeneCIS, and CIRCO demonstrates the superior performance of our model, outperforming state-of-the-art baselines by a significant margin. Codes are available at the GitHub repository.
Exploring Robustness of Unsupervised Domain Adaptation in Semantic Segmentation
May 23, 2021


Recent studies imply that deep neural networks are vulnerable to adversarial examples -- inputs with a slight but intentional perturbation are incorrectly classified by the network. Such vulnerability makes it risky for some security-related applications (e.g., semantic segmentation in autonomous cars) and triggers tremendous concerns on the model reliability. For the first time, we comprehensively evaluate the robustness of existing UDA methods and propose a robust UDA approach. It is rooted in two observations: (i) the robustness of UDA methods in semantic segmentation remains unexplored, which pose a security concern in this field; and (ii) although commonly used self-supervision (e.g., rotation and jigsaw) benefits image tasks such as classification and recognition, they fail to provide the critical supervision signals that could learn discriminative representation for segmentation tasks. These observations motivate us to propose adversarial self-supervision UDA (or ASSUDA) that maximizes the agreement between clean images and their adversarial examples by a contrastive loss in the output space. Extensive empirical studies on commonly used benchmarks demonstrate that ASSUDA is resistant to adversarial attacks.
Dense-View GEIs Set: View Space Covering for Gait Recognition based on Dense-View GAN
Sep 26, 2020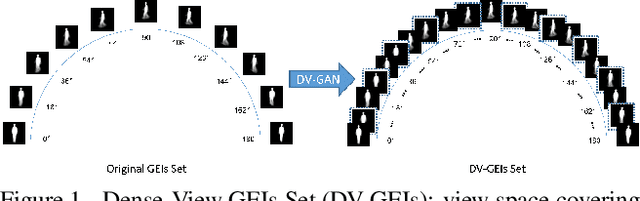
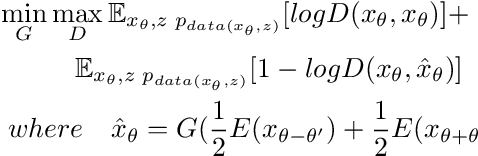


Gait recognition has proven to be effective for long-distance human recognition. But view variance of gait features would change human appearance greatly and reduce its performance. Most existing gait datasets usually collect data with a dozen different angles, or even more few. Limited view angles would prevent learning better view invariant feature. It can further improve robustness of gait recognition if we collect data with various angles at 1 degree interval. But it is time consuming and labor consuming to collect this kind of dataset. In this paper, we, therefore, introduce a Dense-View GEIs Set (DV-GEIs) to deal with the challenge of limited view angles. This set can cover the whole view space, view angle from 0 degree to 180 degree with 1 degree interval. In addition, Dense-View GAN (DV-GAN) is proposed to synthesize this dense view set. DV-GAN consists of Generator, Discriminator and Monitor, where Monitor is designed to preserve human identification and view information. The proposed method is evaluated on the CASIA-B and OU-ISIR dataset. The experimental results show that DV-GEIs synthesized by DV-GAN is an effective way to learn better view invariant feature. We believe the idea of dense view generated samples will further improve the development of gait recognition.
Label-Driven Reconstruction for Domain Adaptation in Semantic Segmentation
Mar 10, 2020
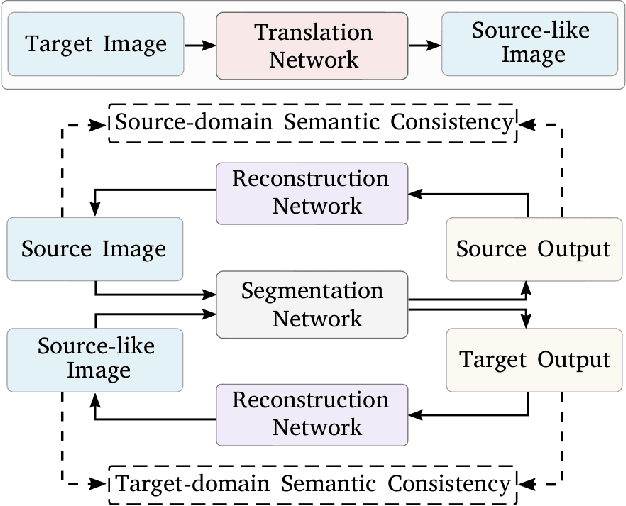
Unsupervised domain adaptation enables to alleviate the need for pixel-wise annotation in the semantic segmentation. One of the most common strategies is to translate images from the source domain to the target domain and then align their marginal distributions in the feature space using adversarial learning. However, source-to-target translation enlarges the bias in translated images, owing to the dominant data size of the source domain. Furthermore, consistency of the joint distribution in source and target domains cannot be guaranteed through global feature alignment. Here, we present an innovative framework, designed to mitigate the image translation bias and align cross-domain features with the same category. This is achieved by 1) performing the target-to-source translation and 2) reconstructing both source and target images from their predicted labels. Extensive experiments on adapting from synthetic to real urban scene understanding demonstrate that our framework competes favorably against existing state-of-the-art methods.
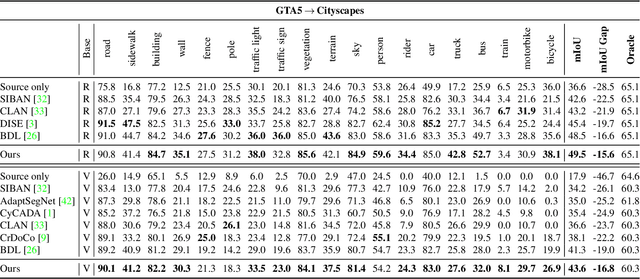
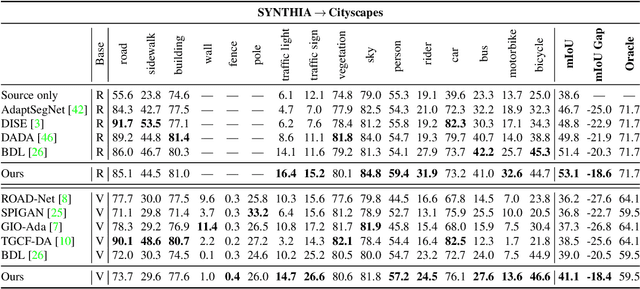
Context-Aware Domain Adaptation in Semantic Segmentation
Mar 09, 2020
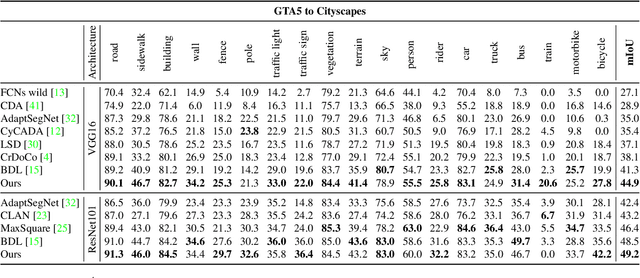
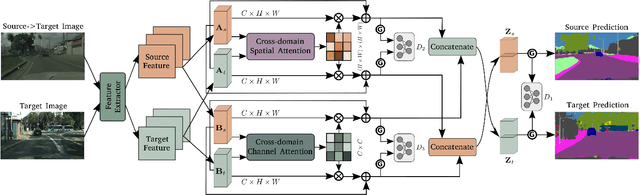
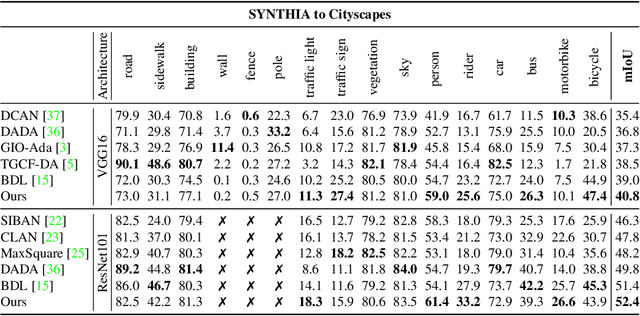
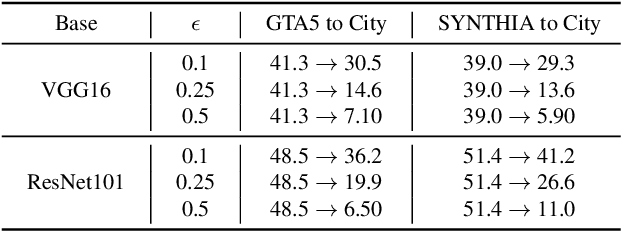
In this paper, we consider the problem of unsupervised domain adaptation in the semantic segmentation. There are two primary issues in this field, i.e., what and how to transfer domain knowledge across two domains. Existing methods mainly focus on adapting domain-invariant features (what to transfer) through adversarial learning (how to transfer). Context dependency is essential for semantic segmentation, however, its transferability is still not well understood. Furthermore, how to transfer contextual information across two domains remains unexplored. Motivated by this, we propose a cross-attention mechanism based on self-attention to capture context dependencies between two domains and adapt transferable context. To achieve this goal, we design two cross-domain attention modules to adapt context dependencies from both spatial and channel views. Specifically, the spatial attention module captures local feature dependencies between each position in the source and target image. The channel attention module models semantic dependencies between each pair of cross-domain channel maps. To adapt context dependencies, we further selectively aggregate the context information from two domains. The superiority of our method over existing state-of-the-art methods is empirically proved on "GTA5 to Cityscapes" and "SYNTHIA to Cityscapes".