 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHuman Identification at a Distance: Challenges, Methods and Results on the Competition HID 2025
Feb 07, 2026Human identification at a distance (HID) is challenging because traditional biometric modalities such as face and fingerprints are often difficult to acquire in real-world scenarios. Gait recognition provides a practical alternative, as it can be captured reliably at a distance. To promote progress in gait recognition and provide a fair evaluation platform, the International Competition on Human Identification at a Distance (HID) has been organized annually since 2020. Since 2023, the competition has adopted the challenging SUSTech-Competition dataset, which features substantial variations in clothing, carried objects, and view angles. No dedicated training data are provided, requiring participants to train their models using external datasets. Each year, the competition applies a different random seed to generate distinct evaluation splits, which reduces the risk of overfitting and supports a fair assessment of cross-domain generalization. While HID 2023 and HID 2024 already used this dataset, HID 2025 explicitly examined whether algorithmic advances could surpass the accuracy limits observed previously. Despite the heightened difficulty, participants achieved further improvements, and the best-performing method reached 94.2% accuracy, setting a new benchmark on this dataset. We also analyze key technical trends and outline potential directions for future research in gait recognition.
Is Visual Realism Enough? Evaluating Gait Biometric Fidelity in Generative AI Human Animation
Dec 22, 2025

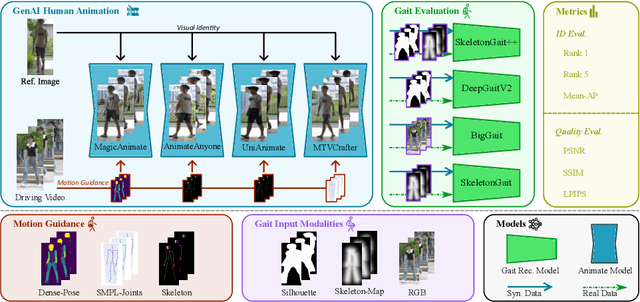
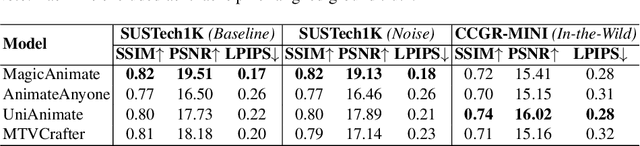
Generative AI (GenAI) models have revolutionized animation, enabling the synthesis of humans and motion patterns with remarkable visual fidelity. However, generating truly realistic human animation remains a formidable challenge, where even minor inconsistencies can make a subject appear unnatural. This limitation is particularly critical when AI-generated videos are evaluated for behavioral biometrics, where subtle motion cues that define identity are easily lost or distorted. The present study investigates whether state-of-the-art GenAI human animation models can preserve the subtle spatio-temporal details needed for person identification through gait biometrics. Specifically, we evaluate four different GenAI models across two primary evaluation tasks to assess their ability to i) restore gait patterns from reference videos under varying conditions of complexity, and ii) transfer these gait patterns to different visual identities. Our results show that while visual quality is mostly high, biometric fidelity remains low in tasks focusing on identification, suggesting that current GenAI models struggle to disentangle identity from motion. Furthermore, through an identity transfer task, we expose a fundamental flaw in appearance-based gait recognition: when texture is disentangled from motion, identification collapses, proving current GenAI models rely on visual attributes rather than temporal dynamics.
On Denoising Walking Videos for Gait Recognition
May 24, 2025To capture individual gait patterns, excluding identity-irrelevant cues in walking videos, such as clothing texture and color, remains a persistent challenge for vision-based gait recognition. Traditional silhouette- and pose-based methods, though theoretically effective at removing such distractions, often fall short of high accuracy due to their sparse and less informative inputs. Emerging end-to-end methods address this by directly denoising RGB videos using human priors. Building on this trend, we propose DenoisingGait, a novel gait denoising method. Inspired by the philosophy that "what I cannot create, I do not understand", we turn to generative diffusion models, uncovering how they partially filter out irrelevant factors for gait understanding. Additionally, we introduce a geometry-driven Feature Matching module, which, combined with background removal via human silhouettes, condenses the multi-channel diffusion features at each foreground pixel into a two-channel direction vector. Specifically, the proposed within- and cross-frame matching respectively capture the local vectorized structures of gait appearance and motion, producing a novel flow-like gait representation termed Gait Feature Field, which further reduces residual noise in diffusion features. Experiments on the CCPG, CASIA-B*, and SUSTech1K datasets demonstrate that DenoisingGait achieves a new SoTA performance in most cases for both within- and cross-domain evaluations. Code is available at https://github.com/ShiqiYu/OpenGait.
BiggerGait: Unlocking Gait Recognition with Layer-wise Representations from Large Vision Models
May 23, 2025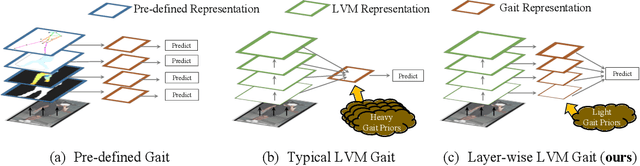
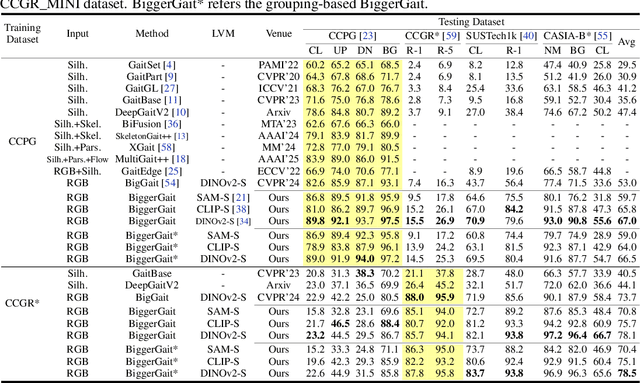
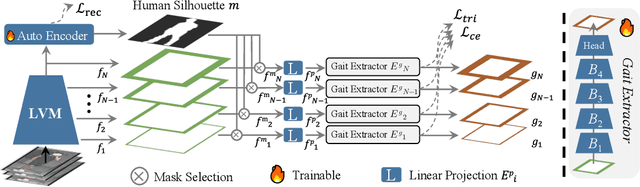
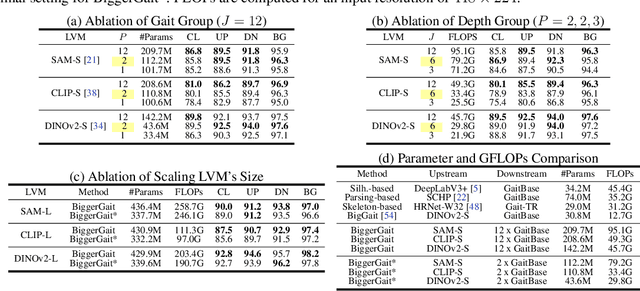
Large vision models (LVM) based gait recognition has achieved impressive performance. However, existing LVM-based approaches may overemphasize gait priors while neglecting the intrinsic value of LVM itself, particularly the rich, distinct representations across its multi-layers. To adequately unlock LVM's potential, this work investigates the impact of layer-wise representations on downstream recognition tasks. Our analysis reveals that LVM's intermediate layers offer complementary properties across tasks, integrating them yields an impressive improvement even without rich well-designed gait priors. Building on this insight, we propose a simple and universal baseline for LVM-based gait recognition, termed BiggerGait. Comprehensive evaluations on CCPG, CAISA-B*, SUSTech1K, and CCGR\_MINI validate the superiority of BiggerGait across both within- and cross-domain tasks, establishing it as a simple yet practical baseline for gait representation learning. All the models and code will be publicly available.
Exploring More from Multiple Gait Modalities for Human Identification
Dec 16, 2024



The gait, as a kind of soft biometric characteristic, can reflect the distinct walking patterns of individuals at a distance, exhibiting a promising technique for unrestrained human identification. With largely excluding gait-unrelated cues hidden in RGB videos, the silhouette and skeleton, though visually compact, have acted as two of the most prevailing gait modalities for a long time. Recently, several attempts have been made to introduce more informative data forms like human parsing and optical flow images to capture gait characteristics, along with multi-branch architectures. However, due to the inconsistency within model designs and experiment settings, we argue that a comprehensive and fair comparative study among these popular gait modalities, involving the representational capacity and fusion strategy exploration, is still lacking. From the perspectives of fine vs. coarse-grained shape and whole vs. pixel-wise motion modeling, this work presents an in-depth investigation of three popular gait representations, i.e., silhouette, human parsing, and optical flow, with various fusion evaluations, and experimentally exposes their similarities and differences. Based on the obtained insights, we further develop a C$^2$Fusion strategy, consequently building our new framework MultiGait++. C$^2$Fusion preserves commonalities while highlighting differences to enrich the learning of gait features. To verify our findings and conclusions, extensive experiments on Gait3D, GREW, CCPG, and SUSTech1K are conducted. The code is available at https://github.com/ShiqiYu/OpenGait.
Gait Patterns as Biomarkers: A Video-Based Approach for Classifying Scoliosis
Jul 09, 2024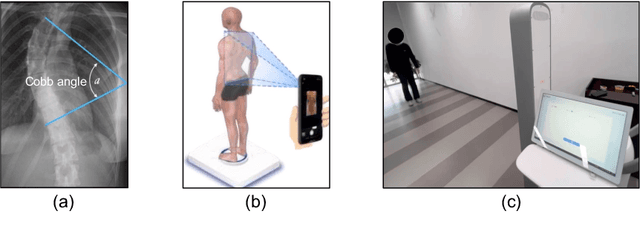
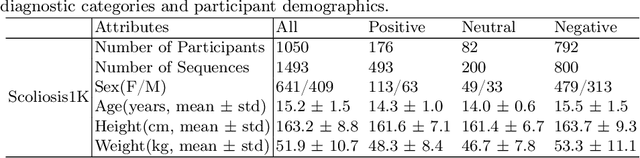

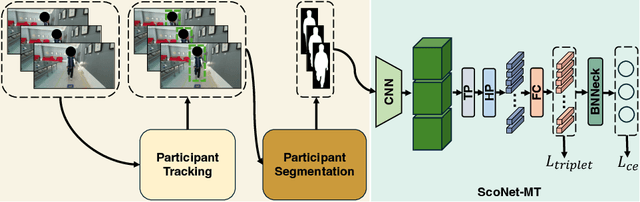
Scoliosis poses significant diagnostic challenges, particularly in adolescents, where early detection is crucial for effective treatment. Traditional diagnostic and follow-up methods, which rely on physical examinations and radiography, face limitations due to the need for clinical expertise and the risk of radiation exposure, thus restricting their use for widespread early screening. In response, we introduce a novel, video-based, non-invasive method for scoliosis classification using gait analysis, which circumvents these limitations. This study presents Scoliosis1K, the first large-scale dataset tailored for video-based scoliosis classification, encompassing over one thousand adolescents. Leveraging this dataset, we developed ScoNet, an initial model that encountered challenges in dealing with the complexities of real-world data. This led to the creation of ScoNet-MT, an enhanced model incorporating multi-task learning, which exhibits promising diagnostic accuracy for application purposes. Our findings demonstrate that gait can be a non-invasive biomarker for scoliosis, revolutionizing screening practices with deep learning and setting a precedent for non-invasive diagnostic methodologies. The dataset and code are publicly available at https://zhouzi180.github.io/Scoliosis1K/.
OpenGait: A Comprehensive Benchmark Study for Gait Recognition towards Better Practicality
May 15, 2024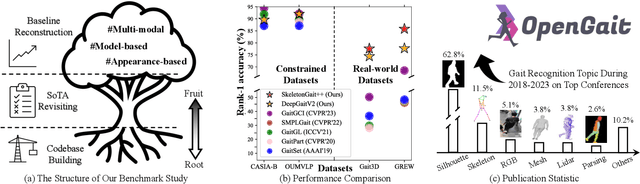
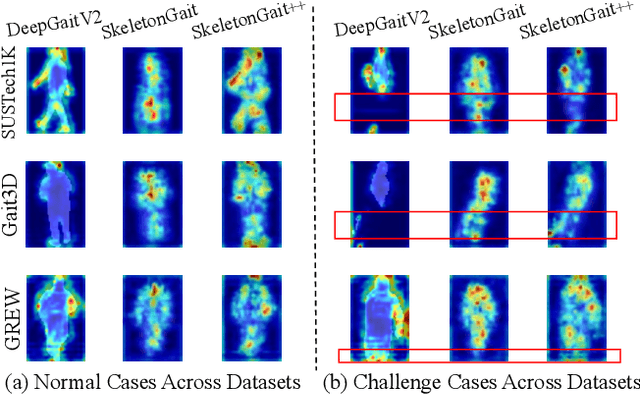
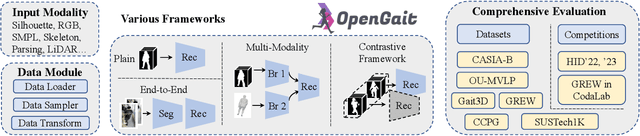
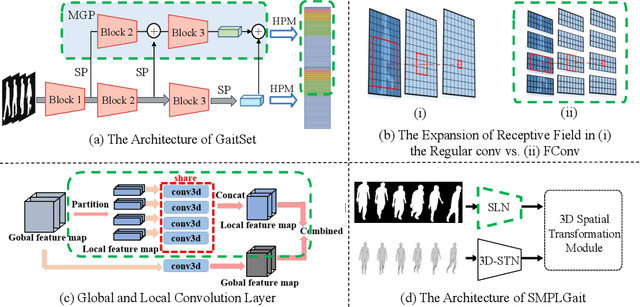
Gait recognition, a rapidly advancing vision technology for person identification from a distance, has made significant strides in indoor settings. However, evidence suggests that existing methods often yield unsatisfactory results when applied to newly released real-world gait datasets. Furthermore, conclusions drawn from indoor gait datasets may not easily generalize to outdoor ones. Therefore, the primary goal of this work is to present a comprehensive benchmark study aimed at improving practicality rather than solely focusing on enhancing performance. To this end, we first develop OpenGait, a flexible and efficient gait recognition platform. Using OpenGait as a foundation, we conduct in-depth ablation experiments to revisit recent developments in gait recognition. Surprisingly, we detect some imperfect parts of certain prior methods thereby resulting in several critical yet undiscovered insights. Inspired by these findings, we develop three structurally simple yet empirically powerful and practically robust baseline models, i.e., DeepGaitV2, SkeletonGait, and SkeletonGait++, respectively representing the appearance-based, model-based, and multi-modal methodology for gait pattern description. Beyond achieving SoTA performances, more importantly, our careful exploration sheds new light on the modeling experience of deep gait models, the representational capacity of typical gait modalities, and so on. We hope this work can inspire further research and application of gait recognition towards better practicality. The code is available at https://github.com/ShiqiYu/OpenGait.
Cross-Modality Gait Recognition: Bridging LiDAR and Camera Modalities for Human Identification
Apr 04, 2024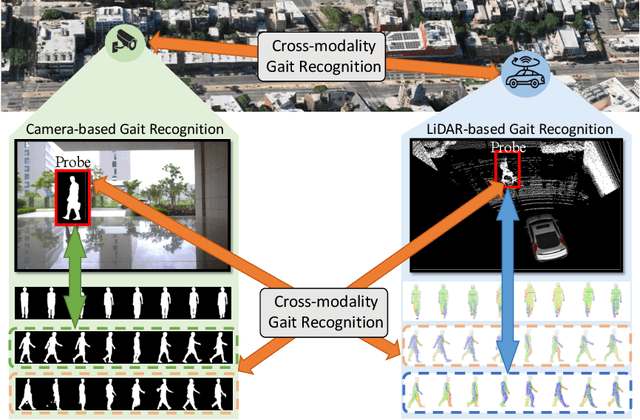



Current gait recognition research mainly focuses on identifying pedestrians captured by the same type of sensor, neglecting the fact that individuals may be captured by different sensors in order to adapt to various environments. A more practical approach should involve cross-modality matching across different sensors. Hence, this paper focuses on investigating the problem of cross-modality gait recognition, with the objective of accurately identifying pedestrians across diverse vision sensors. We present CrossGait inspired by the feature alignment strategy, capable of cross retrieving diverse data modalities. Specifically, we investigate the cross-modality recognition task by initially extracting features within each modality and subsequently aligning these features across modalities. To further enhance the cross-modality performance, we propose a Prototypical Modality-shared Attention Module that learns modality-shared features from two modality-specific features. Additionally, we design a Cross-modality Feature Adapter that transforms the learned modality-specific features into a unified feature space. Extensive experiments conducted on the SUSTech1K dataset demonstrate the effectiveness of CrossGait: (1) it exhibits promising cross-modality ability in retrieving pedestrians across various modalities from different sensors in diverse scenes, and (2) CrossGait not only learns modality-shared features for cross-modality gait recognition but also maintains modality-specific features for single-modality recognition.
BigGait: Learning Gait Representation You Want by Large Vision Models
Feb 29, 2024



Gait recognition stands as one of the most pivotal remote identification technologies and progressively expands across research and industrial communities. However, existing gait recognition methods heavily rely on task-specific upstream driven by supervised learning to provide explicit gait representations, which inevitably introduce expensive annotation costs and potentially cause cumulative errors. Escaping from this trend, this work explores effective gait representations based on the all-purpose knowledge produced by task-agnostic Large Vision Models (LVMs) and proposes a simple yet efficient gait framework, termed BigGait. Specifically, the Gait Representation Extractor (GRE) in BigGait effectively transforms all-purpose knowledge into implicit gait features in an unsupervised manner, drawing from design principles of established gait representation construction approaches. Experimental results on CCPG, CAISA-B* and SUSTech1K indicate that BigGait significantly outperforms the previous methods in both self-domain and cross-domain tasks in most cases, and provides a more practical paradigm for learning the next-generation gait representation. Eventually, we delve into prospective challenges and promising directions in LVMs-based gait recognition, aiming to inspire future work in this emerging topic. The source code will be available at https://github.com/ShiqiYu/OpenGait.
Cross-Covariate Gait Recognition: A Benchmark
Jan 05, 2024Gait datasets are essential for gait research. However, this paper observes that present benchmarks, whether conventional constrained or emerging real-world datasets, fall short regarding covariate diversity. To bridge this gap, we undertake an arduous 20-month effort to collect a cross-covariate gait recognition (CCGR) dataset. The CCGR dataset has 970 subjects and about 1.6 million sequences; almost every subject has 33 views and 53 different covariates. Compared to existing datasets, CCGR has both population and individual-level diversity. In addition, the views and covariates are well labeled, enabling the analysis of the effects of different factors. CCGR provides multiple types of gait data, including RGB, parsing, silhouette, and pose, offering researchers a comprehensive resource for exploration. In order to delve deeper into addressing cross-covariate gait recognition, we propose parsing-based gait recognition (ParsingGait) by utilizing the newly proposed parsing data. We have conducted extensive experiments. Our main results show: 1) Cross-covariate emerges as a pivotal challenge for practical applications of gait recognition. 2) ParsingGait demonstrates remarkable potential for further advancement. 3) Alarmingly, existing SOTA methods achieve less than 43% accuracy on the CCGR, highlighting the urgency of exploring cross-covariate gait recognition. Link: https://github.com/ShinanZou/CCGR.
* This paper has been accepted by AAAI2024