 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInstantHDR: Single-forward Gaussian Splatting for High Dynamic Range 3D Reconstruction
Mar 11, 2026High dynamic range (HDR) novel view synthesis (NVS) aims to reconstruct HDR scenes from multi-exposure low dynamic range (LDR) images. Existing HDR pipelines heavily rely on known camera poses, well-initialized dense point clouds, and time-consuming per-scene optimization. Current feed-forward alternatives overlook the HDR problem by assuming exposure-invariant appearance. To bridge this gap, we propose InstantHDR, a feed-forward network that reconstructs 3D HDR scenes from uncalibrated multi-exposure LDR collections in a single forward pass. Specifically, we design a geometry-guided appearance modeling for multi-exposure fusion, and a meta-network for generalizable scene-specific tone mapping. Due to the lack of HDR scene data, we build a pre-training dataset, called HDR-Pretrain, for generalizable feed-forward HDR models, featuring 168 Blender-rendered scenes, diverse lighting types, and multiple camera response functions. Comprehensive experiments show that our InstantHDR delivers comparable synthesis performance to the state-of-the-art optimization-based HDR methods while enjoying $\sim700\times$ and $\sim20\times$ reconstruction speed improvement with our single-forward and post-optimization settings. All code, models, and datasets will be released after the review process.
Person Recognition at Altitude and Range: Fusion of Face, Body Shape and Gait
May 07, 2025



We address the problem of whole-body person recognition in unconstrained environments. This problem arises in surveillance scenarios such as those in the IARPA Biometric Recognition and Identification at Altitude and Range (BRIAR) program, where biometric data is captured at long standoff distances, elevated viewing angles, and under adverse atmospheric conditions (e.g., turbulence and high wind velocity). To this end, we propose FarSight, a unified end-to-end system for person recognition that integrates complementary biometric cues across face, gait, and body shape modalities. FarSight incorporates novel algorithms across four core modules: multi-subject detection and tracking, recognition-aware video restoration, modality-specific biometric feature encoding, and quality-guided multi-modal fusion. These components are designed to work cohesively under degraded image conditions, large pose and scale variations, and cross-domain gaps. Extensive experiments on the BRIAR dataset, one of the most comprehensive benchmarks for long-range, multi-modal biometric recognition, demonstrate the effectiveness of FarSight. Compared to our preliminary system, this system achieves a 34.1% absolute gain in 1:1 verification accuracy (TAR@0.1% FAR), a 17.8% increase in closed-set identification (Rank-20), and a 34.3% reduction in open-set identification errors (FNIR@1% FPIR). Furthermore, FarSight was evaluated in the 2025 NIST RTE Face in Video Evaluation (FIVE), which conducts standardized face recognition testing on the BRIAR dataset. These results establish FarSight as a state-of-the-art solution for operational biometric recognition in challenging real-world conditions.
SapiensID: Foundation for Human Recognition
Apr 07, 2025Existing human recognition systems often rely on separate, specialized models for face and body analysis, limiting their effectiveness in real-world scenarios where pose, visibility, and context vary widely. This paper introduces SapiensID, a unified model that bridges this gap, achieving robust performance across diverse settings. SapiensID introduces (i) Retina Patch (RP), a dynamic patch generation scheme that adapts to subject scale and ensures consistent tokenization of regions of interest, (ii) a masked recognition model (MRM) that learns from variable token length, and (iii) Semantic Attention Head (SAH), an module that learns pose-invariant representations by pooling features around key body parts. To facilitate training, we introduce WebBody4M, a large-scale dataset capturing diverse poses and scale variations. Extensive experiments demonstrate that SapiensID achieves state-of-the-art results on various body ReID benchmarks, outperforming specialized models in both short-term and long-term scenarios while remaining competitive with dedicated face recognition systems. Furthermore, SapiensID establishes a strong baseline for the newly introduced challenge of Cross Pose-Scale ReID, demonstrating its ability to generalize to complex, real-world conditions.
BigGait: Learning Gait Representation You Want by Large Vision Models
Feb 29, 2024



Gait recognition stands as one of the most pivotal remote identification technologies and progressively expands across research and industrial communities. However, existing gait recognition methods heavily rely on task-specific upstream driven by supervised learning to provide explicit gait representations, which inevitably introduce expensive annotation costs and potentially cause cumulative errors. Escaping from this trend, this work explores effective gait representations based on the all-purpose knowledge produced by task-agnostic Large Vision Models (LVMs) and proposes a simple yet efficient gait framework, termed BigGait. Specifically, the Gait Representation Extractor (GRE) in BigGait effectively transforms all-purpose knowledge into implicit gait features in an unsupervised manner, drawing from design principles of established gait representation construction approaches. Experimental results on CCPG, CAISA-B* and SUSTech1K indicate that BigGait significantly outperforms the previous methods in both self-domain and cross-domain tasks in most cases, and provides a more practical paradigm for learning the next-generation gait representation. Eventually, we delve into prospective challenges and promising directions in LVMs-based gait recognition, aiming to inspire future work in this emerging topic. The source code will be available at https://github.com/ShiqiYu/OpenGait.
GaitEditer: Attribute Editing for Gait Representation Learning
Mar 09, 2023
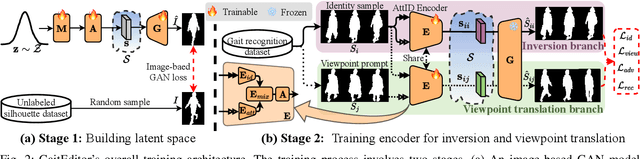

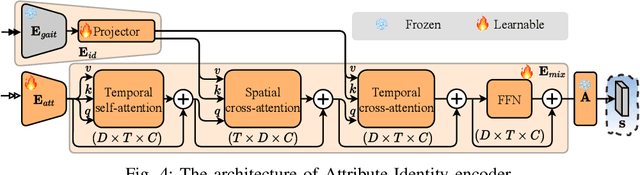
Gait pattern is a promising biometric for applications, as it can be captured from a distance without requiring individual cooperation. Nevertheless, existing gait datasets typically suffer from limited diversity, with indoor datasets requiring participants to walk along a fixed route in a restricted setting, and outdoor datasets containing only few walking sequences per subject. Prior generative methods have attempted to mitigate these limitations by building virtual gait datasets. They primarily focus on manipulating a single, specific gait attribute (e.g., viewpoint or carrying), and require the supervised data pairs for training, thus lacking the flexibility and diversity for practical usage. In contrast, our GaitEditer can act as an online module to edit a broad range of gait attributes, such as pants, viewpoint, and even age, in an unsupervised manner, which current gait generative methods struggle with. Additionally, GaitEidter also finely preserves both temporal continuity and identity characteristics in generated gait sequences. Experiments show that GaitEditer provides extensive knowledge for clothing-invariant and view-invariant gait representation learning under various challenging scenarios. The source code will be available.