 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Temporal Action Localization via Self-paced Incremental Learning
Paper and Code
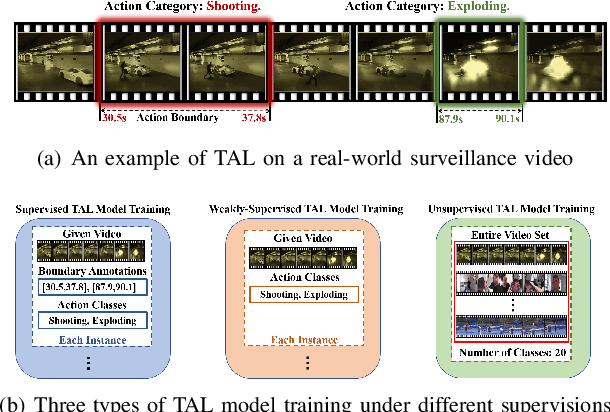
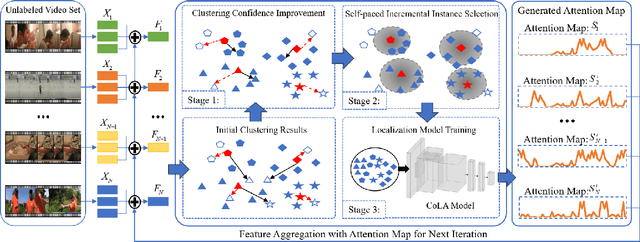
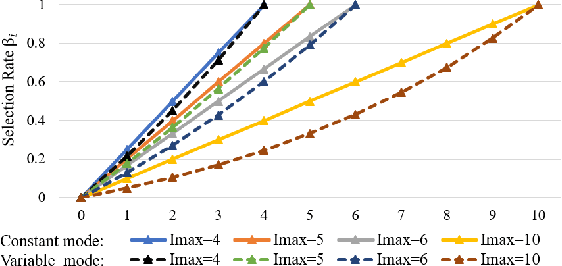
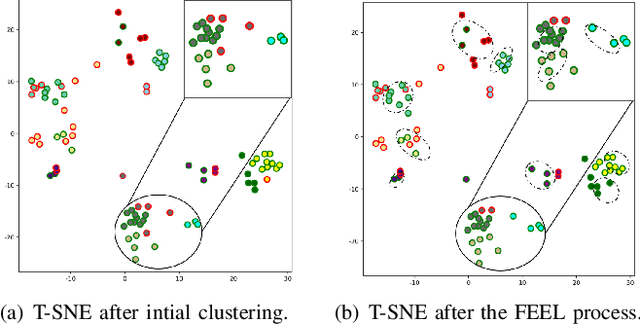
Recently, temporal action localization (TAL) has garnered significant interest in information retrieval community. However, existing supervised/weakly supervised methods are heavily dependent on extensive labeled temporal boundaries and action categories, which is labor-intensive and time-consuming. Although some unsupervised methods have utilized the ``iteratively clustering and localization'' paradigm for TAL, they still suffer from two pivotal impediments: 1) unsatisfactory video clustering confidence, and 2) unreliable video pseudolabels for model training. To address these limitations, we present a novel self-paced incremental learning model to enhance clustering and localization training simultaneously, thereby facilitating more effective unsupervised TAL. Concretely, we improve the clustering confidence through exploring the contextual feature-robust visual information. Thereafter, we design two (constant- and variable- speed) incremental instance learning strategies for easy-to-hard model training, thus ensuring the reliability of these video pseudolabels and further improving overall localization performance. Extensive experiments on two public datasets have substantiated the superiority of our model over several state-of-the-art competitors.