 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFineCIR: Explicit Parsing of Fine-Grained Modification Semantics for Composed Image Retrieval
Mar 27, 2025
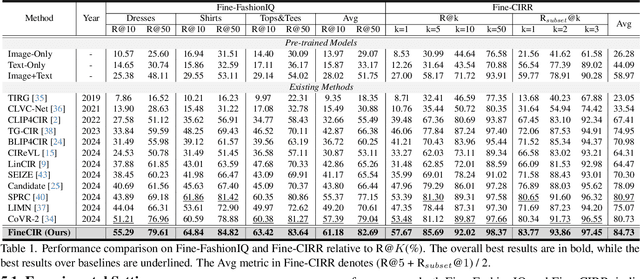
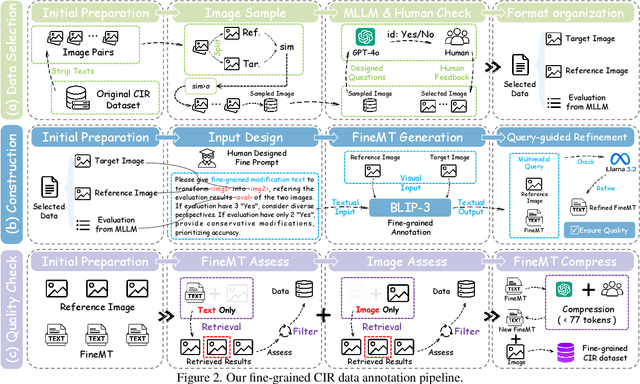
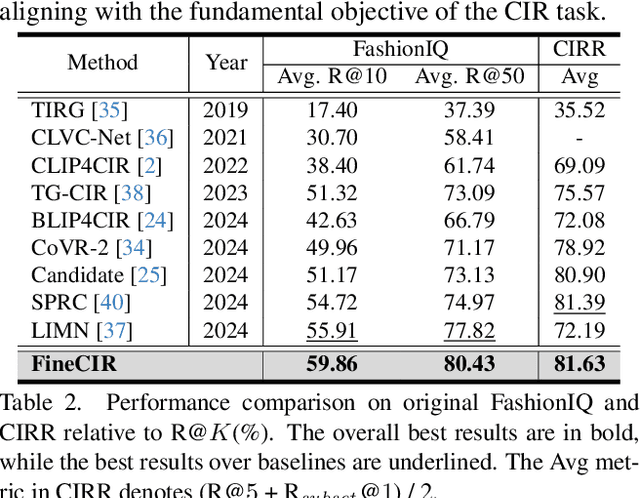
Composed Image Retrieval (CIR) facilitates image retrieval through a multimodal query consisting of a reference image and modification text. The reference image defines the retrieval context, while the modification text specifies desired alterations. However, existing CIR datasets predominantly employ coarse-grained modification text (CoarseMT), which inadequately captures fine-grained retrieval intents. This limitation introduces two key challenges: (1) ignoring detailed differences leads to imprecise positive samples, and (2) greater ambiguity arises when retrieving visually similar images. These issues degrade retrieval accuracy, necessitating manual result filtering or repeated queries. To address these limitations, we develop a robust fine-grained CIR data annotation pipeline that minimizes imprecise positive samples and enhances CIR systems' ability to discern modification intents accurately. Using this pipeline, we refine the FashionIQ and CIRR datasets to create two fine-grained CIR datasets: Fine-FashionIQ and Fine-CIRR. Furthermore, we introduce FineCIR, the first CIR framework explicitly designed to parse the modification text. FineCIR effectively captures fine-grained modification semantics and aligns them with ambiguous visual entities, enhancing retrieval precision. Extensive experiments demonstrate that FineCIR consistently outperforms state-of-the-art CIR baselines on both fine-grained and traditional CIR benchmark datasets. Our FineCIR code and fine-grained CIR datasets are available at https://github.com/SDU-L/FineCIR.git.
A method for incremental discovery of financial event types based on anomaly detection
Feb 16, 2023


Event datasets in the financial domain are often constructed based on actual application scenarios, and their event types are weakly reusable due to scenario constraints; at the same time, the massive and diverse new financial big data cannot be limited to the event types defined for specific scenarios. This limitation of a small number of event types does not meet our research needs for more complex tasks such as the prediction of major financial events and the analysis of the ripple effects of financial events. In this paper, a three-stage approach is proposed to accomplish incremental discovery of event types. For an existing annotated financial event dataset, the three-stage approach consists of: for a set of financial event data with a mixture of original and unknown event types, a semi-supervised deep clustering model with anomaly detection is first applied to classify the data into normal and abnormal events, where abnormal events are events that do not belong to known types; then normal events are tagged with appropriate event types and abnormal events are reasonably clustered. Finally, a cluster keyword extraction method is used to recommend the type names of events for the new event clusters, thus incrementally discovering new event types. The proposed method is effective in the incremental discovery of new event types on real data sets.