 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA method for incremental discovery of financial event types based on anomaly detection
Paper and Code
Feb 16, 2023

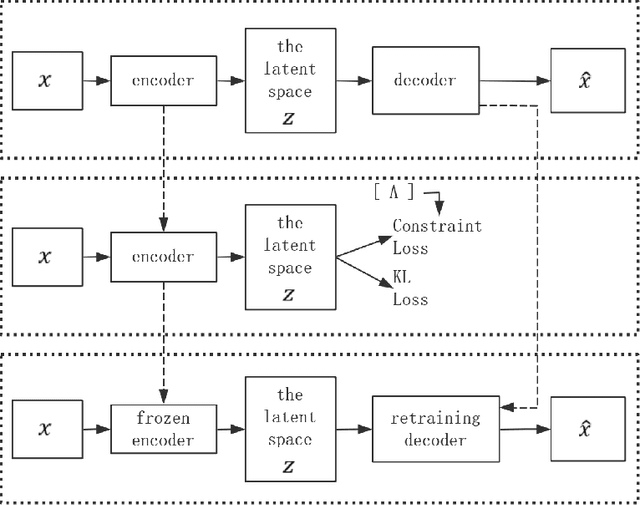

Event datasets in the financial domain are often constructed based on actual application scenarios, and their event types are weakly reusable due to scenario constraints; at the same time, the massive and diverse new financial big data cannot be limited to the event types defined for specific scenarios. This limitation of a small number of event types does not meet our research needs for more complex tasks such as the prediction of major financial events and the analysis of the ripple effects of financial events. In this paper, a three-stage approach is proposed to accomplish incremental discovery of event types. For an existing annotated financial event dataset, the three-stage approach consists of: for a set of financial event data with a mixture of original and unknown event types, a semi-supervised deep clustering model with anomaly detection is first applied to classify the data into normal and abnormal events, where abnormal events are events that do not belong to known types; then normal events are tagged with appropriate event types and abnormal events are reasonably clustered. Finally, a cluster keyword extraction method is used to recommend the type names of events for the new event clusters, thus incrementally discovering new event types. The proposed method is effective in the incremental discovery of new event types on real data sets.