 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVision-guided and Mask-enhanced Adaptive Denoising for Prompt-based Image Editing
Oct 14, 2024



Text-to-image diffusion models have demonstrated remarkable progress in synthesizing high-quality images from text prompts, which boosts researches on prompt-based image editing that edits a source image according to a target prompt. Despite their advances, existing methods still encounter three key issues: 1) limited capacity of the text prompt in guiding target image generation, 2) insufficient mining of word-to-patch and patch-to-patch relationships for grounding editing areas, and 3) unified editing strength for all regions during each denoising step. To address these issues, we present a Vision-guided and Mask-enhanced Adaptive Editing (ViMAEdit) method with three key novel designs. First, we propose to leverage image embeddings as explicit guidance to enhance the conventional textual prompt-based denoising process, where a CLIP-based target image embedding estimation strategy is introduced. Second, we devise a self-attention-guided iterative editing area grounding strategy, which iteratively exploits patch-to-patch relationships conveyed by self-attention maps to refine those word-to-patch relationships contained in cross-attention maps. Last, we present a spatially adaptive variance-guided sampling, which highlights sampling variances for critical image regions to promote the editing capability. Experimental results demonstrate the superior editing capacity of ViMAEdit over all existing methods.
Do Vision-Language Transformers Exhibit Visual Commonsense? An Empirical Study of VCR
May 27, 2024



Visual Commonsense Reasoning (VCR) calls for explanatory reasoning behind question answering over visual scenes. To achieve this goal, a model is required to provide an acceptable rationale as the reason for the predicted answers. Progress on the benchmark dataset stems largely from the recent advancement of Vision-Language Transformers (VL Transformers). These models are first pre-trained on some generic large-scale vision-text datasets, and then the learned representations are transferred to the downstream VCR task. Despite their attractive performance, this paper posits that the VL Transformers do not exhibit visual commonsense, which is the key to VCR. In particular, our empirical results pinpoint several shortcomings of existing VL Transformers: small gains from pre-training, unexpected language bias, limited model architecture for the two inseparable sub-tasks, and neglect of the important object-tag correlation. With these findings, we tentatively suggest some future directions from the aspect of dataset, evaluation metric, and training tricks. We believe this work could make researchers revisit the intuition and goals of VCR, and thus help tackle the remaining challenges in visual reasoning.
Learning to Agree on Vision Attention for Visual Commonsense Reasoning
Feb 19, 2023Visual Commonsense Reasoning (VCR) remains a significant yet challenging research problem in the realm of visual reasoning. A VCR model generally aims at answering a textual question regarding an image, followed by the rationale prediction for the preceding answering process. Though these two processes are sequential and intertwined, existing methods always consider them as two independent matching-based instances. They, therefore, ignore the pivotal relationship between the two processes, leading to sub-optimal model performance. This paper presents a novel visual attention alignment method to efficaciously handle these two processes in a unified framework. To achieve this, we first design a re-attention module for aggregating the vision attention map produced in each process. Thereafter, the resultant two sets of attention maps are carefully aligned to guide the two processes to make decisions based on the same image regions. We apply this method to both conventional attention and the recent Transformer models and carry out extensive experiments on the VCR benchmark dataset. The results demonstrate that with the attention alignment module, our method achieves a considerable improvement over the baseline methods, evidently revealing the feasibility of the coupling of the two processes as well as the effectiveness of the proposed method.
Joint Answering and Explanation for Visual Commonsense Reasoning
Feb 25, 2022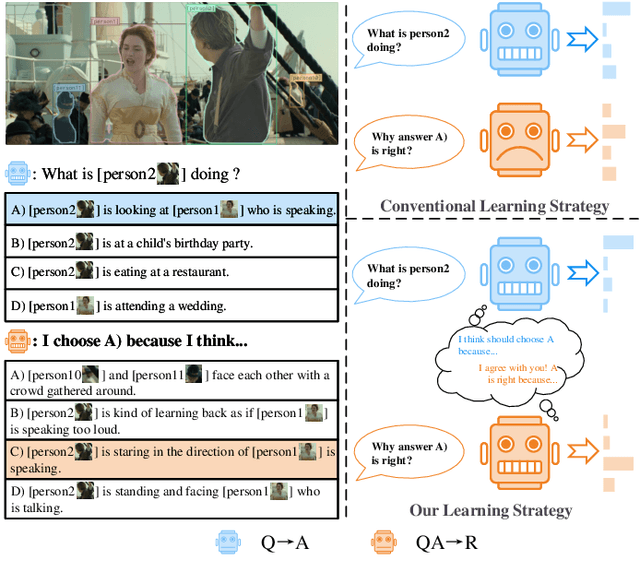


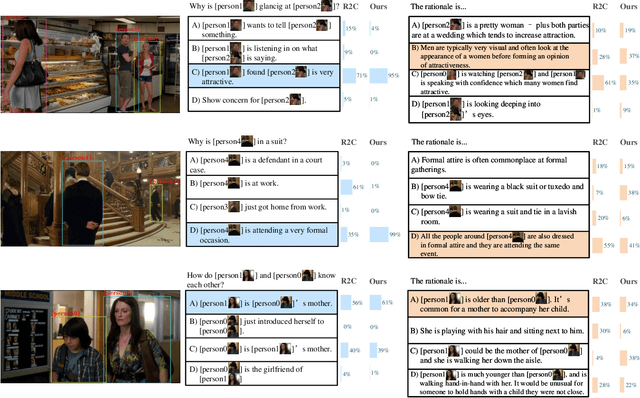
Visual Commonsense Reasoning (VCR), deemed as one challenging extension of the Visual Question Answering (VQA), endeavors to pursue a more high-level visual comprehension. It is composed of two indispensable processes: question answering over a given image and rationale inference for answer explanation. Over the years, a variety of methods tackling VCR have advanced the performance on the benchmark dataset. Despite significant as these methods are, they often treat the two processes in a separate manner and hence decompose the VCR into two irrelevant VQA instances. As a result, the pivotal connection between question answering and rationale inference is interrupted, rendering existing efforts less faithful on visual reasoning. To empirically study this issue, we perform some in-depth explorations in terms of both language shortcuts and generalization capability to verify the pitfalls of this treatment. Based on our findings, in this paper, we present a plug-and-play knowledge distillation enhanced framework to couple the question answering and rationale inference processes. The key contribution is the introduction of a novel branch, which serves as the bridge to conduct processes connecting. Given that our framework is model-agnostic, we apply it to the existing popular baselines and validate its effectiveness on the benchmark dataset. As detailed in the experimental results, when equipped with our framework, these baselines achieve consistent and significant performance improvements, demonstrating the viability of processes coupling, as well as the superiority of the proposed framework.