 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJoint Answering and Explanation for Visual Commonsense Reasoning
Paper and Code
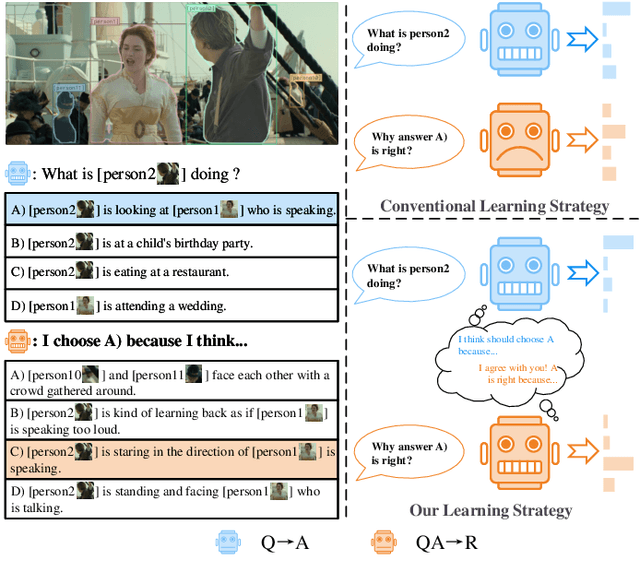


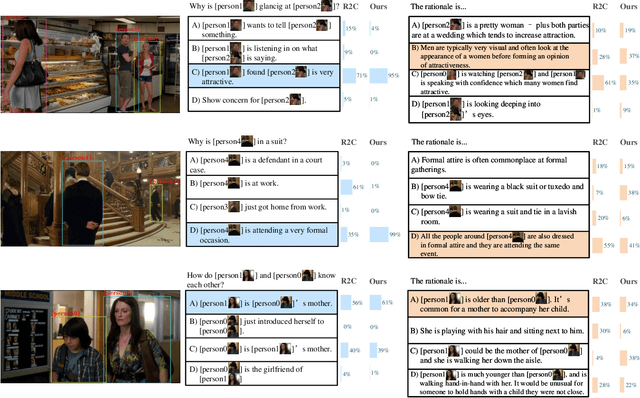
Visual Commonsense Reasoning (VCR), deemed as one challenging extension of the Visual Question Answering (VQA), endeavors to pursue a more high-level visual comprehension. It is composed of two indispensable processes: question answering over a given image and rationale inference for answer explanation. Over the years, a variety of methods tackling VCR have advanced the performance on the benchmark dataset. Despite significant as these methods are, they often treat the two processes in a separate manner and hence decompose the VCR into two irrelevant VQA instances. As a result, the pivotal connection between question answering and rationale inference is interrupted, rendering existing efforts less faithful on visual reasoning. To empirically study this issue, we perform some in-depth explorations in terms of both language shortcuts and generalization capability to verify the pitfalls of this treatment. Based on our findings, in this paper, we present a plug-and-play knowledge distillation enhanced framework to couple the question answering and rationale inference processes. The key contribution is the introduction of a novel branch, which serves as the bridge to conduct processes connecting. Given that our framework is model-agnostic, we apply it to the existing popular baselines and validate its effectiveness on the benchmark dataset. As detailed in the experimental results, when equipped with our framework, these baselines achieve consistent and significant performance improvements, demonstrating the viability of processes coupling, as well as the superiority of the proposed framework.