 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActiShade: Activating Overshadowed Knowledge to Guide Multi-Hop Reasoning in Large Language Models
Jan 12, 2026In multi-hop reasoning, multi-round retrieval-augmented generation (RAG) methods typically rely on LLM-generated content as the retrieval query. However, these approaches are inherently vulnerable to knowledge overshadowing - a phenomenon where critical information is overshadowed during generation. As a result, the LLM-generated content may be incomplete or inaccurate, leading to irrelevant retrieval and causing error accumulation during the iteration process. To address this challenge, we propose ActiShade, which detects and activates overshadowed knowledge to guide large language models (LLMs) in multi-hop reasoning. Specifically, ActiShade iteratively detects the overshadowed keyphrase in the given query, retrieves documents relevant to both the query and the overshadowed keyphrase, and generates a new query based on the retrieved documents to guide the next-round iteration. By supplementing the overshadowed knowledge during the formulation of next-round queries while minimizing the introduction of irrelevant noise, ActiShade reduces the error accumulation caused by knowledge overshadowing. Extensive experiments show that ActiShade outperforms existing methods across multiple datasets and LLMs.
SCoder: Iterative Self-Distillation for Bootstrapping Small-Scale Data Synthesizers to Empower Code LLMs
Sep 09, 2025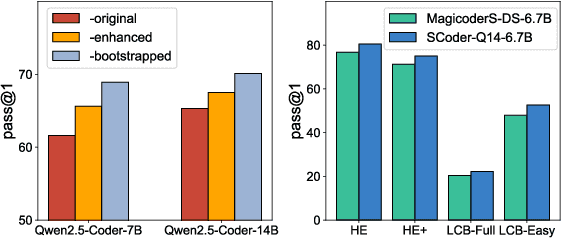
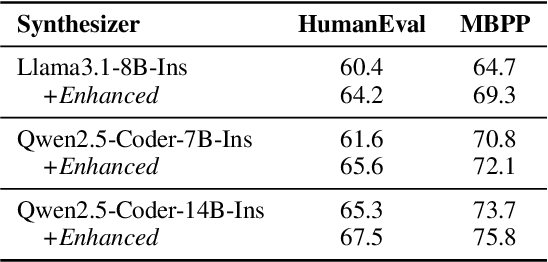
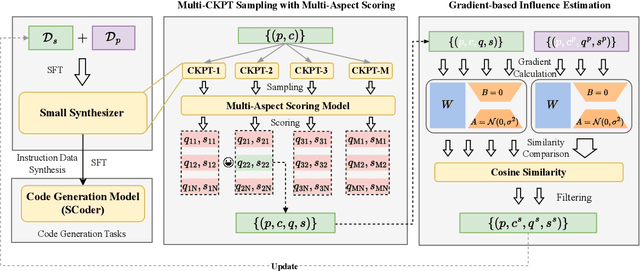
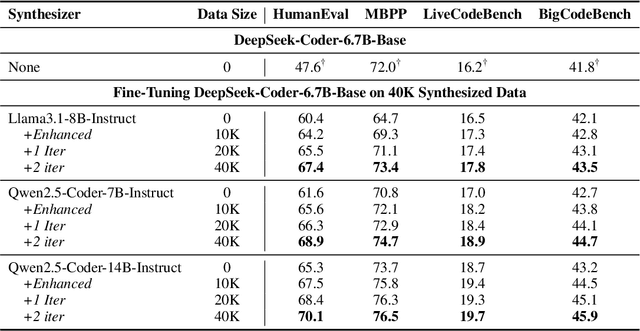
Existing code large language models (LLMs) often rely on large-scale instruction data distilled from proprietary LLMs for fine-tuning, which typically incurs high costs. In this paper, we explore the potential of small-scale open-source LLMs (e.g., 7B) as synthesizers for high-quality code instruction data construction. We first observe that the data synthesis capability of small-scale LLMs can be enhanced by training on a few superior data synthesis samples from proprietary LLMs. Building on this, we propose a novel iterative self-distillation approach to bootstrap small-scale LLMs, transforming them into powerful synthesizers that reduce reliance on proprietary LLMs and minimize costs. Concretely, in each iteration, to obtain diverse and high-quality self-distilled data, we design multi-checkpoint sampling and multi-aspect scoring strategies for initial data selection. Furthermore, to identify the most influential samples, we introduce a gradient-based influence estimation method for final data filtering. Based on the code instruction datasets from the small-scale synthesizers, we develop SCoder, a family of code generation models fine-tuned from DeepSeek-Coder. SCoder models achieve state-of-the-art code generation capabilities, demonstrating the effectiveness of our method.
RefineCoder: Iterative Improving of Large Language Models via Adaptive Critique Refinement for Code Generation
Feb 13, 2025Code generation has attracted increasing attention with the rise of Large Language Models (LLMs). Many studies have developed powerful code LLMs by synthesizing code-related instruction data and applying supervised fine-tuning. However, these methods are limited by teacher model distillation and ignore the potential of iterative refinement by self-generated code. In this paper, we propose Adaptive Critique Refinement (ACR), which enables the model to refine itself by self-generated code and external critique, rather than directly imitating the code responses of the teacher model. Concretely, ACR includes a composite scoring system with LLM-as-a-Judge to evaluate the quality of code responses and a selective critique strategy with LLM-as-a-Critic to critique self-generated low-quality code responses. We develop the RefineCoder series by iteratively applying ACR, achieving continuous performance improvement on multiple code generation benchmarks. Compared to the baselines of the same size, our proposed RefineCoder series can achieve comparable or even superior performance using less data.
Laser: Parameter-Efficient LLM Bi-Tuning for Sequential Recommendation with Collaborative Information
Sep 03, 2024



Sequential recommender systems are essential for discerning user preferences from historical interactions and facilitating targeted recommendations. Recent innovations employing Large Language Models (LLMs) have advanced the field by encoding item semantics, yet they often necessitate substantial parameter tuning and are resource-demanding. Moreover, these works fails to consider the diverse characteristics of different types of users and thus diminishes the recommendation accuracy. In this paper, we propose a parameter-efficient Large Language Model Bi-Tuning framework for sequential recommendation with collaborative information (Laser). Specifically, Bi-Tuning works by inserting trainable virtual tokens at both the prefix and suffix of the input sequence and freezing the LLM parameters, thus optimizing the LLM for the sequential recommendation. In our Laser, the prefix is utilized to incorporate user-item collaborative information and adapt the LLM to the recommendation task, while the suffix converts the output embeddings of the LLM from the language space to the recommendation space for the follow-up item recommendation. Furthermore, to capture the characteristics of different types of users when integrating the collaborative information via the prefix, we introduce M-Former, a lightweight MoE-based querying transformer that uses a set of query experts to integrate diverse user-specific collaborative information encoded by frozen ID-based sequential recommender systems, significantly improving the accuracy of recommendations. Extensive experiments on real-world datasets demonstrate that Laser can parameter-efficiently adapt LLMs to effective recommender systems, significantly outperforming state-of-the-art methods.
SeaKR: Self-aware Knowledge Retrieval for Adaptive Retrieval Augmented Generation
Jun 27, 2024



This paper introduces Self-aware Knowledge Retrieval (SeaKR), a novel adaptive RAG model that extracts self-aware uncertainty of LLMs from their internal states. SeaKR activates retrieval when the LLMs present high self-aware uncertainty for generation. To effectively integrate retrieved knowledge snippets, SeaKR re-ranks them based on LLM's self-aware uncertainty to preserve the snippet that reduces their uncertainty to the utmost. To facilitate solving complex tasks that require multiple retrievals, SeaKR utilizes their self-aware uncertainty to choose among different reasoning strategies. Our experiments on both complex and simple Question Answering datasets show that SeaKR outperforms existing adaptive RAG methods. We release our code at https://github.com/THU-KEG/SeaKR.
LLMvsSmall Model? Large Language Model Based Text Augmentation Enhanced Personality Detection Model
Mar 12, 2024Personality detection aims to detect one's personality traits underlying in social media posts. One challenge of this task is the scarcity of ground-truth personality traits which are collected from self-report questionnaires. Most existing methods learn post features directly by fine-tuning the pre-trained language models under the supervision of limited personality labels. This leads to inferior quality of post features and consequently affects the performance. In addition, they treat personality traits as one-hot classification labels, overlooking the semantic information within them. In this paper, we propose a large language model (LLM) based text augmentation enhanced personality detection model, which distills the LLM's knowledge to enhance the small model for personality detection, even when the LLM fails in this task. Specifically, we enable LLM to generate post analyses (augmentations) from the aspects of semantic, sentiment, and linguistic, which are critical for personality detection. By using contrastive learning to pull them together in the embedding space, the post encoder can better capture the psycho-linguistic information within the post representations, thus improving personality detection. Furthermore, we utilize the LLM to enrich the information of personality labels for enhancing the detection performance. Experimental results on the benchmark datasets demonstrate that our model outperforms the state-of-the-art methods on personality detection.
KB-Plugin: A Plug-and-play Framework for Large Language Models to Induce Programs over Low-resourced Knowledge Bases
Feb 02, 2024



Program induction (PI) has become a promising paradigm for using knowledge bases (KBs) to help large language models (LLMs) answer complex knowledge-intensive questions. Nonetheless, PI typically relies on a large number of parallel question-program pairs to make the LLM aware of the schema of the given KB, and is thus challenging for many low-resourced KBs that lack annotated data. To this end, we propose KB-Plugin, a plug-and-play framework that enables LLMs to induce programs over any low-resourced KB. Firstly, KB-Plugin adopts self-supervised learning to encode the detailed schema information of a given KB into a pluggable module, namely schema plugin. Secondly, KB-Plugin utilizes abundant annotated data from a rich-resourced KB to train another pluggable module, namely PI plugin, which can help the LLM extract question-relevant schema information from the schema plugin of any KB and utilize this information to induce programs over this KB. Experiments on five heterogeneous KBQA datasets show that KB-Plugin achieves better or comparable performance with 25$\times$ smaller backbone LLM compared to SoTA PI methods for low-resourced KBs, and even approaches the performance of supervised methods. Our code and data are available at https://github.com/THU-KEG/KB-Plugin.
Enhancing Human Capabilities through Symbiotic Artificial Intelligence with Shared Sensory Experiences
May 26, 2023The merging of human intelligence and artificial intelligence has long been a subject of interest in both science fiction and academia. In this paper, we introduce a novel concept in Human-AI interaction called Symbiotic Artificial Intelligence with Shared Sensory Experiences (SAISSE), which aims to establish a mutually beneficial relationship between AI systems and human users through shared sensory experiences. By integrating multiple sensory input channels and processing human experiences, SAISSE fosters a strong human-AI bond, enabling AI systems to learn from and adapt to individual users, providing personalized support, assistance, and enhancement. Furthermore, we discuss the incorporation of memory storage units for long-term growth and development of both the AI system and its human user. As we address user privacy and ethical guidelines for responsible AI-human symbiosis, we also explore potential biases and inequalities in AI-human symbiosis and propose strategies to mitigate these challenges. Our research aims to provide a comprehensive understanding of the SAISSE concept and its potential to effectively support and enhance individual human users through symbiotic AI systems. This position article aims at discussing poteintial AI-human interaction related topics within the scientific community, rather than providing experimental or theoretical results.
ChatLLM Network: More brains, More intelligence
Apr 24, 2023
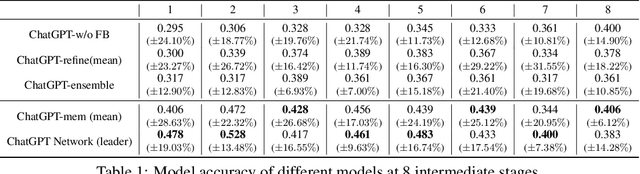
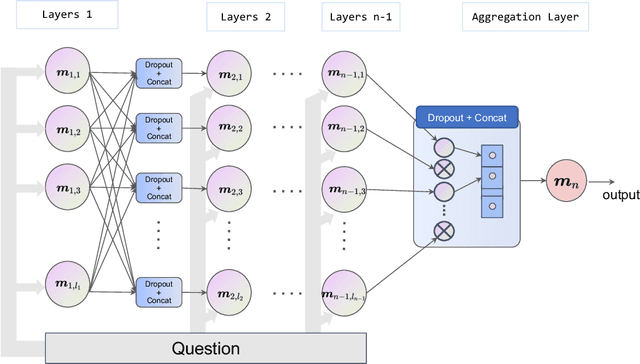
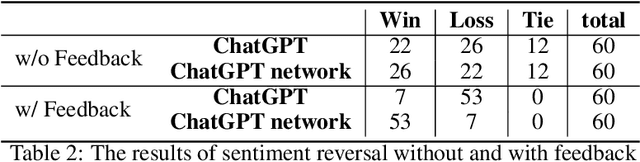
Dialogue-based language models mark a huge milestone in the field of artificial intelligence, by their impressive ability to interact with users, as well as a series of challenging tasks prompted by customized instructions. However, the prevalent large-scale dialogue-based language models like ChatGPT still have room for improvement, such as unstable responses to questions and the inability to think cooperatively like humans. Considering the ability of dialogue-based language models in conversation and their inherent randomness in thinking, we propose ChatLLM network that allows multiple dialogue-based language models to interact, provide feedback, and think together. We design the network of ChatLLMs based on ChatGPT. Specifically, individual instances of ChatGPT may possess distinct perspectives towards the same problem, and by consolidating these diverse viewpoints via a separate ChatGPT, the ChatLLM network system can conduct decision-making more objectively and comprehensively. In addition, a language-based feedback mechanism comparable to backpropagation is devised to update the ChatGPTs within the network. Experiments on two datasets demonstrate that our network attains significant improvements in problem-solving, leading to observable progress amongst each member.
MMNet: Multi-modal Fusion with Mutual Learning Network for Fake News Detection
Dec 12, 2022



The rapid development of social media provides a hotbed for the dissemination of fake news, which misleads readers and causes negative effects on society. News usually involves texts and images to be more vivid. Consequently, multi-modal fake news detection has received wide attention. Prior efforts primarily conduct multi-modal fusion by simple concatenation or co-attention mechanism, leading to sub-optimal performance. In this paper, we propose a novel mutual learning network based model MMNet, which enhances the multi-modal fusion for fake news detection via mutual learning between text- and vision-centered views towards the same classification objective. Specifically, we design two detection modules respectively based on text- and vision-centered multi-modal fusion features, and enable the mutual learning of the two modules to facilitate the multi-modal fusion, considering the latent consistency between the two modules towards the same training objective. Moreover, we also consider the influence of the image-text matching degree on news authenticity judgement by designing an image-text matching aware co-attention mechanism for multi-modal fusion. Extensive experiments are conducted on three benchmark datasets and the results demonstrate that our proposed MMNet achieves superior performance in fake news detection.