 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Response Generation with Dynamic Vocabularies
Paper and Code
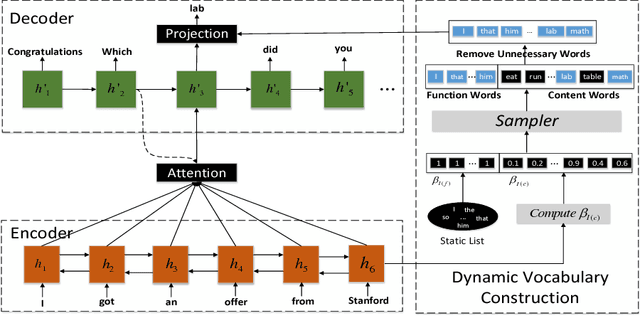

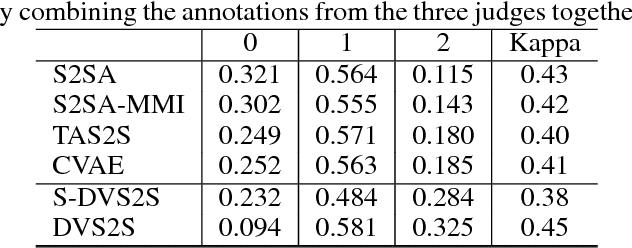
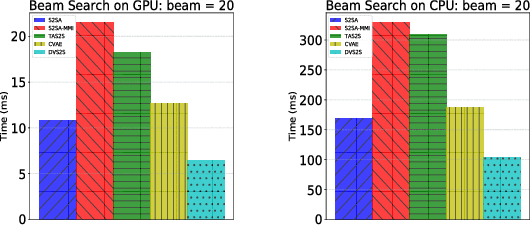
We study response generation for open domain conversation in chatbots. Existing methods assume that words in responses are generated from an identical vocabulary regardless of their inputs, which not only makes them vulnerable to generic patterns and irrelevant noise, but also causes a high cost in decoding. We propose a dynamic vocabulary sequence-to-sequence (DVS2S) model which allows each input to possess their own vocabulary in decoding. In training, vocabulary construction and response generation are jointly learned by maximizing a lower bound of the true objective with a Monte Carlo sampling method. In inference, the model dynamically allocates a small vocabulary for an input with the word prediction model, and conducts decoding only with the small vocabulary. Because of the dynamic vocabulary mechanism, DVS2S eludes many generic patterns and irrelevant words in generation, and enjoys efficient decoding at the same time. Experimental results on both automatic metrics and human annotations show that DVS2S can significantly outperform state-of-the-art methods in terms of response quality, but only requires 60% decoding time compared to the most efficient baseline.