 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Denoising to Decision Making: A Survey on Diffusion Model-Enabled Deep Reinforcement Learning for Wireless Networks
May 25, 2026Deep reinforcement learning (DRL) has long been a promising solution for sequential resource management in wireless networks. However, conventional DRL methods are fundamentally limited by their reliance on unimodal policy distributions, inefficient exploration in high-dimensional action spaces, and poor adaptability to dynamic and heterogeneous environments. Meanwhile, diffusion models (DMs) as one of the most powerful families of generative AI have demonstrted remarkable capabilities in modeling complex, multi-modal data distributions across diverse domains. The integration of DMs and DRL has opened a new and rapidly growing research direction, in which DM-enabled policies substantially enhance decision quality by capturing the complex, discontinuous, and multimodal action structures inherent in wireless resource management. In this paper, we present a comprehensive survey of DM-enabled DRL algorithms and their applications for various issues in wireless networks. Particularly, we first provide the theoretical background of DM and present different DM-enabled DRL algorithms. We then systematically review applications of DM-enabled DRL for across computation offloading in mobile edge computing, UAV-assisted, vehicular, and AIGC-driven systems, as well as wireless resource allocation, physical-layer security, and robotics and UAV planning. We conclude the paper by higlight future research directions.
Unsupervised Anomaly Detection in Multi-Agent Trajectory Prediction via Transformer-Based Models
Jan 28, 2026Identifying safety-critical scenarios is essential for autonomous driving, but the rarity of such events makes supervised labeling impractical. Traditional rule-based metrics like Time-to-Collision are too simplistic to capture complex interaction risks, and existing methods lack a systematic way to verify whether statistical anomalies truly reflect physical danger. To address this gap, we propose an unsupervised anomaly detection framework based on a multi-agent Transformer that models normal driving and measures deviations through prediction residuals. A dual evaluation scheme has been proposed to assess both detection stability and physical alignment: Stability is measured using standard ranking metrics in which Kendall Rank Correlation Coefficient captures rank agreement and Jaccard index captures the consistency of the top-K selected items; Physical alignment is assessed through correlations with established Surrogate Safety Measures (SSM). Experiments on the NGSIM dataset demonstrate our framework's effectiveness: We show that the maximum residual aggregator achieves the highest physical alignment while maintaining stability. Furthermore, our framework identifies 388 unique anomalies missed by Time-to-Collision and statistical baselines, capturing subtle multi-agent risks like reactive braking under lateral drift. The detected anomalies are further clustered into four interpretable risk types, offering actionable insights for simulation and testing.
Supervised and Unsupervised Neural Network Solver for First Order Hyperbolic Nonlinear PDEs
Jan 10, 2026We present a neural network-based method for learning scalar hyperbolic conservation laws. Our method replaces the traditional numerical flux in finite volume schemes with a trainable neural network while preserving the conservative structure of the scheme. The model can be trained both in a supervised setting with efficiently generated synthetic data or in an unsupervised manner, leveraging the weak formulation of the partial differential equation. We provide theoretical results that our model can perform arbitrarily well, and provide associated upper bounds on neural network size. Extensive experiments demonstrate that our method often outperforms efficient schemes such as Godunov's scheme, WENO, and Discontinuous Galerkin for comparable computational budgets. Finally, we demonstrate the effectiveness of our method on a traffic prediction task, leveraging field experimental highway data from the Berkeley DeepDrive drone dataset.
(U)NFV: Supervised and Unsupervised Neural Finite Volume Methods for Solving Hyperbolic PDEs
May 29, 2025We introduce (U)NFV, a modular neural network architecture that generalizes classical finite volume (FV) methods for solving hyperbolic conservation laws. Hyperbolic partial differential equations (PDEs) are challenging to solve, particularly conservation laws whose physically relevant solutions contain shocks and discontinuities. FV methods are widely used for their mathematical properties: convergence to entropy solutions, flow conservation, or total variation diminishing, but often lack accuracy and flexibility in complex settings. Neural Finite Volume addresses these limitations by learning update rules over extended spatial and temporal stencils while preserving conservation structure. It supports both supervised training on solution data (NFV) and unsupervised training via weak-form residual loss (UNFV). Applied to first-order conservation laws, (U)NFV achieves up to 10x lower error than Godunov's method, outperforms ENO/WENO, and rivals discontinuous Galerkin solvers with far less complexity. On traffic modeling problems, both from PDEs and from experimental highway data, (U)NFV captures nonlinear wave dynamics with significantly higher fidelity and scalability than traditional FV approaches.
DeepSeek-Prover-V2: Advancing Formal Mathematical Reasoning via Reinforcement Learning for Subgoal Decomposition
Apr 30, 2025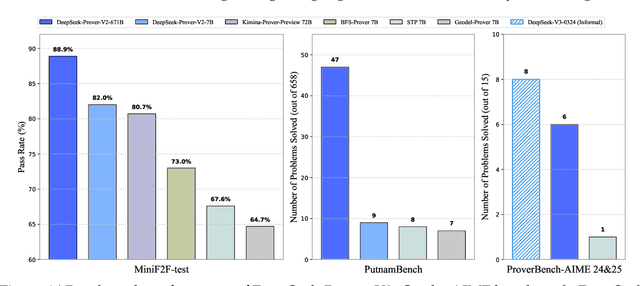
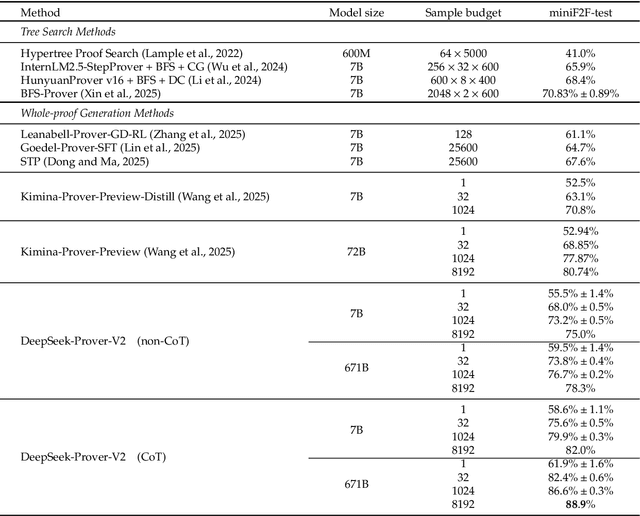

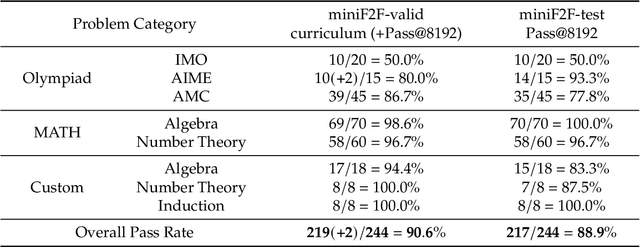
We introduce DeepSeek-Prover-V2, an open-source large language model designed for formal theorem proving in Lean 4, with initialization data collected through a recursive theorem proving pipeline powered by DeepSeek-V3. The cold-start training procedure begins by prompting DeepSeek-V3 to decompose complex problems into a series of subgoals. The proofs of resolved subgoals are synthesized into a chain-of-thought process, combined with DeepSeek-V3's step-by-step reasoning, to create an initial cold start for reinforcement learning. This process enables us to integrate both informal and formal mathematical reasoning into a unified model. The resulting model, DeepSeek-Prover-V2-671B, achieves state-of-the-art performance in neural theorem proving, reaching 88.9% pass ratio on the MiniF2F-test and solving 49 out of 658 problems from PutnamBench. In addition to standard benchmarks, we introduce ProverBench, a collection of 325 formalized problems, to enrich our evaluation, including 15 selected problems from the recent AIME competitions (years 24-25). Further evaluation on these 15 AIME problems shows that the model successfully solves 6 of them. In comparison, DeepSeek-V3 solves 8 of these problems using majority voting, highlighting that the gap between formal and informal mathematical reasoning in large language models is substantially narrowing.
DeepSeek-V3 Technical Report
Dec 27, 2024



We present DeepSeek-V3, a strong Mixture-of-Experts (MoE) language model with 671B total parameters with 37B activated for each token. To achieve efficient inference and cost-effective training, DeepSeek-V3 adopts Multi-head Latent Attention (MLA) and DeepSeekMoE architectures, which were thoroughly validated in DeepSeek-V2. Furthermore, DeepSeek-V3 pioneers an auxiliary-loss-free strategy for load balancing and sets a multi-token prediction training objective for stronger performance. We pre-train DeepSeek-V3 on 14.8 trillion diverse and high-quality tokens, followed by Supervised Fine-Tuning and Reinforcement Learning stages to fully harness its capabilities. Comprehensive evaluations reveal that DeepSeek-V3 outperforms other open-source models and achieves performance comparable to leading closed-source models. Despite its excellent performance, DeepSeek-V3 requires only 2.788M H800 GPU hours for its full training. In addition, its training process is remarkably stable. Throughout the entire training process, we did not experience any irrecoverable loss spikes or perform any rollbacks. The model checkpoints are available at https://github.com/deepseek-ai/DeepSeek-V3.
Pareto Control Barrier Function for Inner Safe Set Maximization Under Input Constraints
Oct 05, 2024



This article introduces the Pareto Control Barrier Function (PCBF) algorithm to maximize the inner safe set of dynamical systems under input constraints. Traditional Control Barrier Functions (CBFs) ensure safety by maintaining system trajectories within a safe set but often fail to account for realistic input constraints. To address this problem, we leverage the Pareto multi-task learning framework to balance competing objectives of safety and safe set volume. The PCBF algorithm is applicable to high-dimensional systems and is computationally efficient. We validate its effectiveness through comparison with Hamilton-Jacobi reachability for an inverted pendulum and through simulations on a 12-dimensional quadrotor system. Results show that the PCBF consistently outperforms existing methods, yielding larger safe sets and ensuring safety under input constraints.
Fire-Flyer AI-HPC: A Cost-Effective Software-Hardware Co-Design for Deep Learning
Aug 26, 2024



The rapid progress in Deep Learning (DL) and Large Language Models (LLMs) has exponentially increased demands of computational power and bandwidth. This, combined with the high costs of faster computing chips and interconnects, has significantly inflated High Performance Computing (HPC) construction costs. To address these challenges, we introduce the Fire-Flyer AI-HPC architecture, a synergistic hardware-software co-design framework and its best practices. For DL training, we deployed the Fire-Flyer 2 with 10,000 PCIe A100 GPUs, achieved performance approximating the DGX-A100 while reducing costs by half and energy consumption by 40%. We specifically engineered HFReduce to accelerate allreduce communication and implemented numerous measures to keep our Computation-Storage Integrated Network congestion-free. Through our software stack, including HaiScale, 3FS, and HAI-Platform, we achieved substantial scalability by overlapping computation and communication. Our system-oriented experience from DL training provides valuable insights to drive future advancements in AI-HPC.
Let Community Rules Be Reflected in Online Content Moderation
Aug 21, 2024



Content moderation is a widely used strategy to prevent the dissemination of irregular information on social media platforms. Despite extensive research on developing automated models to support decision-making in content moderation, there remains a notable scarcity of studies that integrate the rules of online communities into content moderation. This study addresses this gap by proposing a community rule-based content moderation framework that directly integrates community rules into the moderation of user-generated content. Our experiment results with datasets collected from two domains demonstrate the superior performance of models based on the framework to baseline models across all evaluation metrics. In particular, incorporating community rules substantially enhances model performance in content moderation. The findings of this research have significant research and practical implications for improving the effectiveness and generalizability of content moderation models in online communities.
DeepSeek LLM: Scaling Open-Source Language Models with Longtermism
Jan 05, 2024



The rapid development of open-source large language models (LLMs) has been truly remarkable. However, the scaling law described in previous literature presents varying conclusions, which casts a dark cloud over scaling LLMs. We delve into the study of scaling laws and present our distinctive findings that facilitate scaling of large scale models in two commonly used open-source configurations, 7B and 67B. Guided by the scaling laws, we introduce DeepSeek LLM, a project dedicated to advancing open-source language models with a long-term perspective. To support the pre-training phase, we have developed a dataset that currently consists of 2 trillion tokens and is continuously expanding. We further conduct supervised fine-tuning (SFT) and Direct Preference Optimization (DPO) on DeepSeek LLM Base models, resulting in the creation of DeepSeek Chat models. Our evaluation results demonstrate that DeepSeek LLM 67B surpasses LLaMA-2 70B on various benchmarks, particularly in the domains of code, mathematics, and reasoning. Furthermore, open-ended evaluations reveal that DeepSeek LLM 67B Chat exhibits superior performance compared to GPT-3.5.