 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSEED: Simple, Efficient, and Effective Data Management via Large Language Models
Oct 01, 2023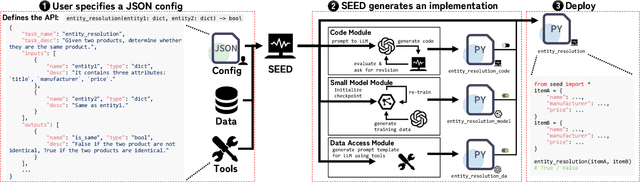
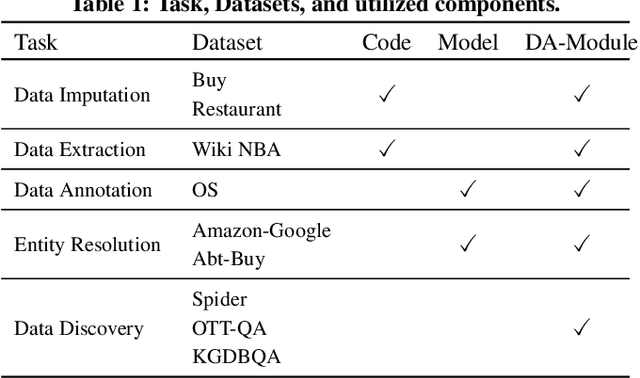
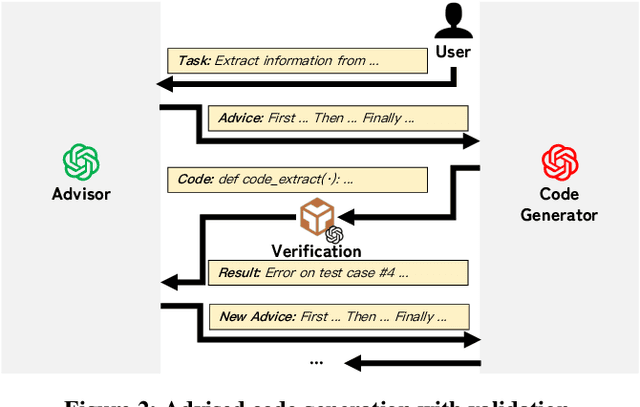
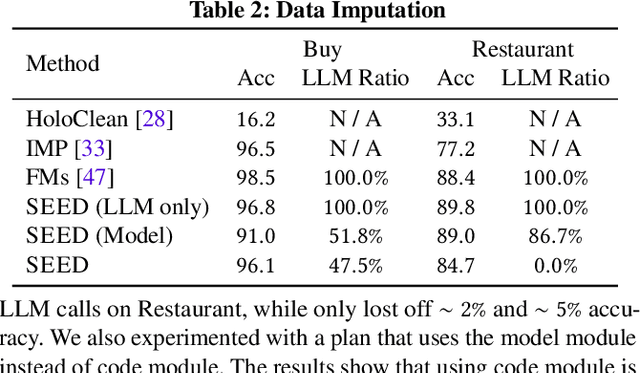
We introduce SEED, an LLM-centric system that allows users to easily create efficient, and effective data management applications. SEED comprises three main components: code generation, model generation, and augmented LLM query to address the challenges that LLM services are computationally and economically expensive and do not always work well on all cases for a given data management task. SEED addresses the expense challenge by localizing LLM computation as much as possible. This includes replacing most of LLM calls with local code, local models, and augmenting LLM queries with batching and data access tools, etc. To ensure effectiveness, SEED features a bunch of optimization techniques to enhance the localized solution and the LLM queries, including automatic code validation, code ensemble, model representatives selection, selective tool usages, etc. Moreover, with SEED users are able to easily construct a data management solution customized to their applications. It allows the users to configure each component and compose an execution pipeline in natural language. SEED then automatically compiles it into an executable program. We showcase the efficiency and effectiveness of SEED using diverse data management tasks such as data imputation, NL2SQL translation, etc., achieving state-of-the-art few-shot performance while significantly reducing the number of required LLM calls.