 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Augmentation: Leveraging Inter-Instance Relation in Self-Supervised Representation Learning
Oct 25, 2025This paper introduces a novel approach that integrates graph theory into self-supervised representation learning. Traditional methods focus on intra-instance variations generated by applying augmentations. However, they often overlook important inter-instance relationships. While our method retains the intra-instance property, it further captures inter-instance relationships by constructing k-nearest neighbor (KNN) graphs for both teacher and student streams during pretraining. In these graphs, nodes represent samples along with their latent representations. Edges encode the similarity between instances. Following pretraining, a representation refinement phase is performed. In this phase, Graph Neural Networks (GNNs) propagate messages not only among immediate neighbors but also across multiple hops, thereby enabling broader contextual integration. Experimental results on CIFAR-10, ImageNet-100, and ImageNet-1K demonstrate accuracy improvements of 7.3%, 3.2%, and 1.0%, respectively, over state-of-the-art methods. These results highlight the effectiveness of the proposed graph based mechanism. The code is publicly available at https://github.com/alijavidani/SSL-GraphNNCLR.
* Accepted in IEEE Signal Processing Letters, 2025
LG-Self: Local-Global Self-Supervised Visual Representation Learning
Nov 07, 2023Self-supervised representation learning methods mainly focus on image-level instance discrimination. This study explores the potential benefits of incorporating patch-level discrimination into existing methods to enhance the quality of learned representations by simultaneously looking at local and global visual features. Towards this idea, we present a straightforward yet effective patch-matching algorithm that can find the corresponding patches across the augmented views of an image. The augmented views are subsequently fed into a self-supervised learning framework employing Vision Transformer (ViT) as its backbone. The result is the generation of both image-level and patch-level representations. Leveraging the proposed patch-matching algorithm, the model minimizes the representation distance between not only the CLS tokens but also the corresponding patches. As a result, the model gains a more comprehensive understanding of both the entirety of the image as well as its finer details. We pretrain the proposed method on small, medium, and large-scale datasets. It is shown that our approach could outperform state-of-the-art image-level representation learning methods on both image classification and downstream tasks. Keywords: Self-Supervised Learning; Visual Representations; Local-Global Representation Learning; Patch-Wise Representation Learning; Vision Transformer (ViT)
A Unified Method for First and Third Person Action Recognition
Apr 08, 2018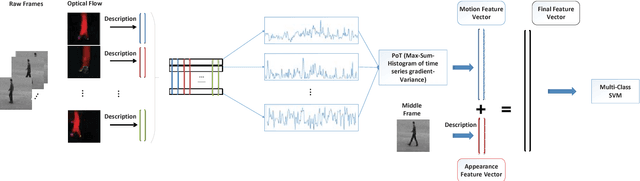
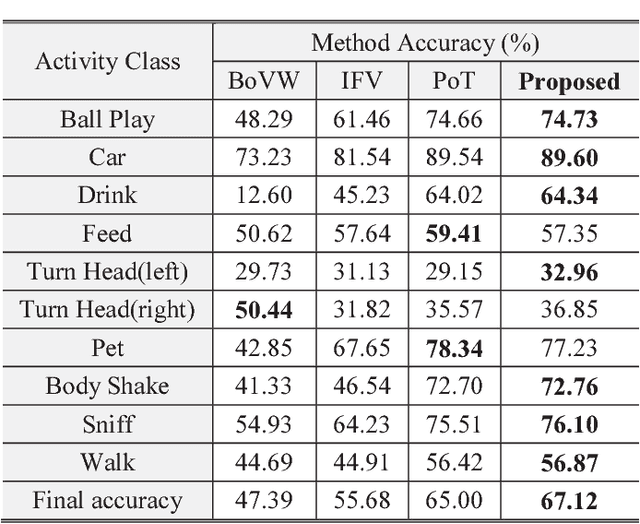

In this paper, a new video classification methodology is proposed which can be applied in both first and third person videos. The main idea behind the proposed strategy is to capture complementary information of appearance and motion efficiently by performing two independent streams on the videos. The first stream is aimed to capture long-term motions from shorter ones by keeping track of how elements in optical flow images have changed over time. Optical flow images are described by pre-trained networks that have been trained on large scale image datasets. A set of multi-channel time series are obtained by aligning descriptions beside each other. For extracting motion features from these time series, PoT representation method plus a novel pooling operator is followed due to several advantages. The second stream is accomplished to extract appearance features which are vital in the case of video classification. The proposed method has been evaluated on both first and third-person datasets and results present that the proposed methodology reaches the state of the art successfully.
Learning Representative Temporal Features for Action Recognition
Mar 14, 2018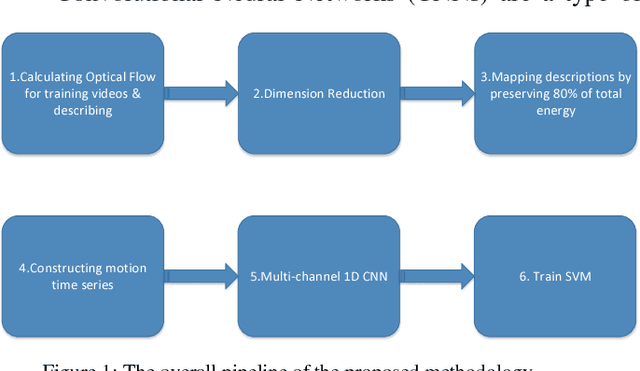
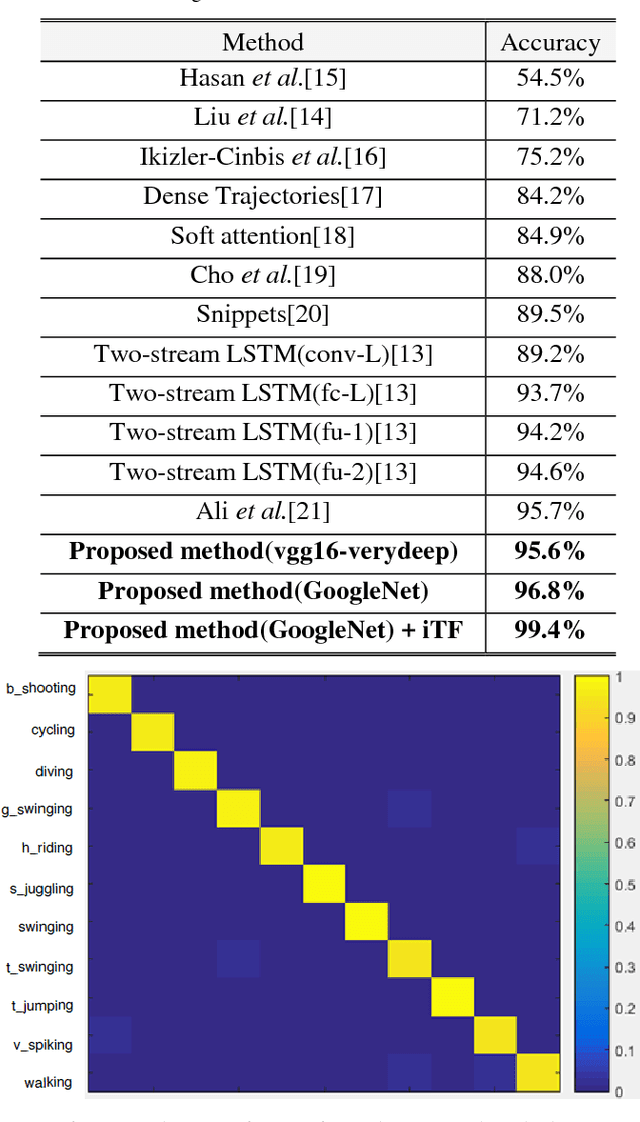
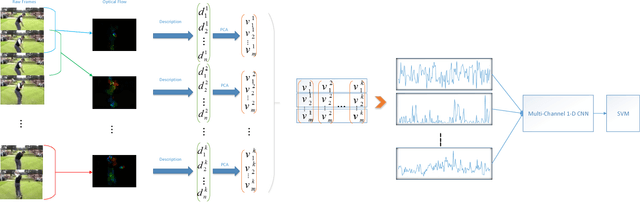

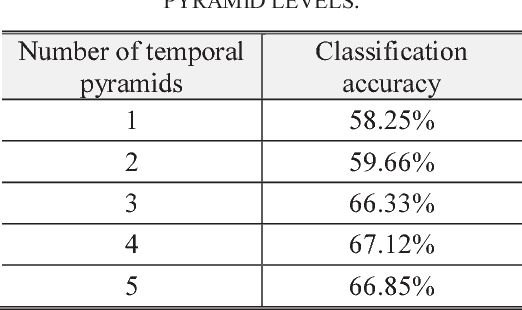
In this paper, a novel video classification methodology is presented that aims to recognize different categories of third-person videos efficiently. The idea is to keep track of motion in videos by following optical flow elements over time. To classify the resulted motion time series efficiently, the idea is letting the machine to learn temporal features along the time dimension. This is done by training a multi-channel one dimensional Convolutional Neural Network (1D-CNN). Since CNNs represent the input data hierarchically, high level features are obtained by further processing of features in lower level layers. As a result, in the case of time series, long-term temporal features are extracted from short-term ones. Besides, the superiority of the proposed method over most of the deep-learning based approaches is that we only try to learn representative temporal features along the time dimension. This reduces the number of learning parameters significantly which results in trainability of our method on even smaller datasets. It is illustrated that the proposed method could reach state-of-the-art results on two public datasets UCF11 and jHMDB with the aid of a more efficient feature vector representation.