 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNTIRE 2025 Challenge on Image Super-Resolution ($\times$4): Methods and Results
Apr 20, 2025This paper presents the NTIRE 2025 image super-resolution ($\times$4) challenge, one of the associated competitions of the 10th NTIRE Workshop at CVPR 2025. The challenge aims to recover high-resolution (HR) images from low-resolution (LR) counterparts generated through bicubic downsampling with a $\times$4 scaling factor. The objective is to develop effective network designs or solutions that achieve state-of-the-art SR performance. To reflect the dual objectives of image SR research, the challenge includes two sub-tracks: (1) a restoration track, emphasizes pixel-wise accuracy and ranks submissions based on PSNR; (2) a perceptual track, focuses on visual realism and ranks results by a perceptual score. A total of 286 participants registered for the competition, with 25 teams submitting valid entries. This report summarizes the challenge design, datasets, evaluation protocol, the main results, and methods of each team. The challenge serves as a benchmark to advance the state of the art and foster progress in image SR.
The Tenth NTIRE 2025 Efficient Super-Resolution Challenge Report
Apr 14, 2025This paper presents a comprehensive review of the NTIRE 2025 Challenge on Single-Image Efficient Super-Resolution (ESR). The challenge aimed to advance the development of deep models that optimize key computational metrics, i.e., runtime, parameters, and FLOPs, while achieving a PSNR of at least 26.90 dB on the $\operatorname{DIV2K\_LSDIR\_valid}$ dataset and 26.99 dB on the $\operatorname{DIV2K\_LSDIR\_test}$ dataset. A robust participation saw \textbf{244} registered entrants, with \textbf{43} teams submitting valid entries. This report meticulously analyzes these methods and results, emphasizing groundbreaking advancements in state-of-the-art single-image ESR techniques. The analysis highlights innovative approaches and establishes benchmarks for future research in the field.
Involution and BSConv Multi-Depth Distillation Network for Lightweight Image Super-Resolution
Mar 18, 2025Single Image Super-Resolution (SISR) aims to reconstruct high-resolution (HR) images from low-resolution (LR) inputs. Deep learning, especially Convolutional Neural Networks (CNNs), has advanced SISR. However, increasing network depth increases parameters, and memory usage, and slows training, which is problematic for resource-limited devices. To address this, lightweight models are developed to balance accuracy and efficiency. We propose the Involution & BSConv Multi-Depth Distillation Network (IBMDN), combining Involution & BSConv Multi-Depth Distillation Block (IBMDB) and the Contrast and High-Frequency Attention Block (CHFAB). IBMDB integrates Involution and BSConv to balance computational efficiency and feature extraction. CHFAB enhances high-frequency details for better visual quality. IBMDB is compatible with other SISR architectures and reduces complexity, improving evaluation metrics like PSNR and SSIM. In transformer-based models, IBMDB reduces memory usage while improving feature extraction. In GANs, it enhances perceptual quality, balancing pixel-level accuracy with perceptual details. Our experiments show that the method achieves high accuracy with minimal computational cost. The code is available at GitHub.
The Ninth NTIRE 2024 Efficient Super-Resolution Challenge Report
Apr 16, 2024



This paper provides a comprehensive review of the NTIRE 2024 challenge, focusing on efficient single-image super-resolution (ESR) solutions and their outcomes. The task of this challenge is to super-resolve an input image with a magnification factor of x4 based on pairs of low and corresponding high-resolution images. The primary objective is to develop networks that optimize various aspects such as runtime, parameters, and FLOPs, while still maintaining a peak signal-to-noise ratio (PSNR) of approximately 26.90 dB on the DIV2K_LSDIR_valid dataset and 26.99 dB on the DIV2K_LSDIR_test dataset. In addition, this challenge has 4 tracks including the main track (overall performance), sub-track 1 (runtime), sub-track 2 (FLOPs), and sub-track 3 (parameters). In the main track, all three metrics (ie runtime, FLOPs, and parameter count) were considered. The ranking of the main track is calculated based on a weighted sum-up of the scores of all other sub-tracks. In sub-track 1, the practical runtime performance of the submissions was evaluated, and the corresponding score was used to determine the ranking. In sub-track 2, the number of FLOPs was considered. The score calculated based on the corresponding FLOPs was used to determine the ranking. In sub-track 3, the number of parameters was considered. The score calculated based on the corresponding parameters was used to determine the ranking. RLFN is set as the baseline for efficiency measurement. The challenge had 262 registered participants, and 34 teams made valid submissions. They gauge the state-of-the-art in efficient single-image super-resolution. To facilitate the reproducibility of the challenge and enable other researchers to build upon these findings, the code and the pre-trained model of validated solutions are made publicly available at https://github.com/Amazingren/NTIRE2024_ESR/.
Compressed image quality assessment using stacking
Feb 01, 2024It is well-known that there is no universal metric for image quality evaluation. In this case, distortion-specific metrics can be more reliable. The artifact imposed by image compression can be considered as a combination of various distortions. Depending on the image context, this combination can be different. As a result, Generalization can be regarded as the major challenge in compressed image quality assessment. In this approach, stacking is employed to provide a reliable method. Both semantic and low-level information are employed in the presented IQA to predict the human visual system. Moreover, the results of the Full-Reference (FR) and No-Reference (NR) models are aggregated to improve the proposed Full-Reference method for compressed image quality evaluation. The accuracy of the quality benchmark of the clic2024 perceptual image challenge was achieved 79.6\%, which illustrates the effectiveness of the proposed fusion-based approach.
The effect of scene context on weakly supervised semantic segmentation
Feb 12, 2019
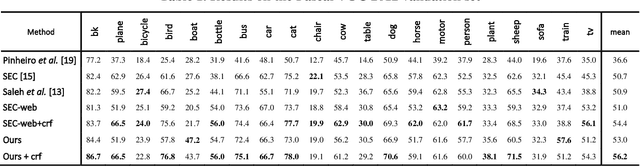
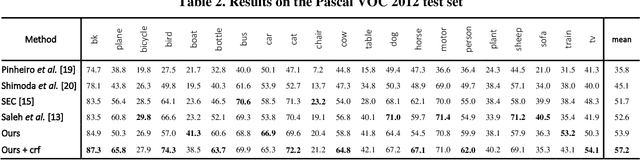

Image semantic segmentation is parsing image into several partitions in such a way that each region of which involves a semantic concept. In a weakly supervised manner, since only image-level labels are available, discriminating objects from the background is challenging, and in some cases, much more difficult. More specifically, some objects which are commonly seen in one specific scene (e.g. 'train' typically is seen on 'railroad track') are much more likely to be confused. In this paper, we propose a method to add the target-specific scenes in order to overcome the aforementioned problem. Actually, we propose a scene recommender which suggests to add some specific scene contexts to the target dataset in order to train the model more accurately. It is notable that this idea could be a complementary part of the baselines of many other methods. The experiments validate the effectiveness of the proposed method for the objects for which the scene context is added.
A Unified Method for First and Third Person Action Recognition
Apr 08, 2018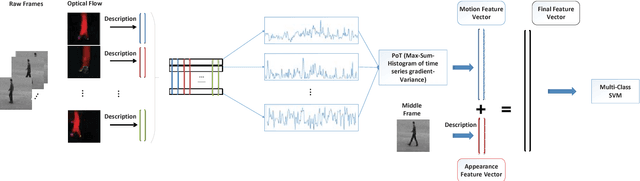
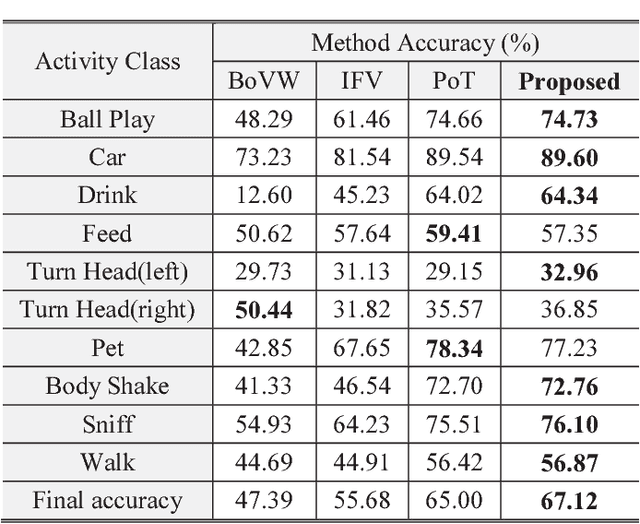

In this paper, a new video classification methodology is proposed which can be applied in both first and third person videos. The main idea behind the proposed strategy is to capture complementary information of appearance and motion efficiently by performing two independent streams on the videos. The first stream is aimed to capture long-term motions from shorter ones by keeping track of how elements in optical flow images have changed over time. Optical flow images are described by pre-trained networks that have been trained on large scale image datasets. A set of multi-channel time series are obtained by aligning descriptions beside each other. For extracting motion features from these time series, PoT representation method plus a novel pooling operator is followed due to several advantages. The second stream is accomplished to extract appearance features which are vital in the case of video classification. The proposed method has been evaluated on both first and third-person datasets and results present that the proposed methodology reaches the state of the art successfully.
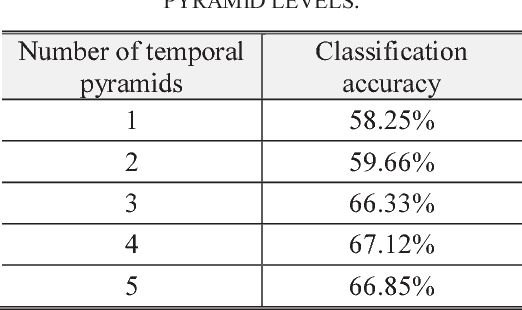
Learning Representative Temporal Features for Action Recognition
Mar 14, 2018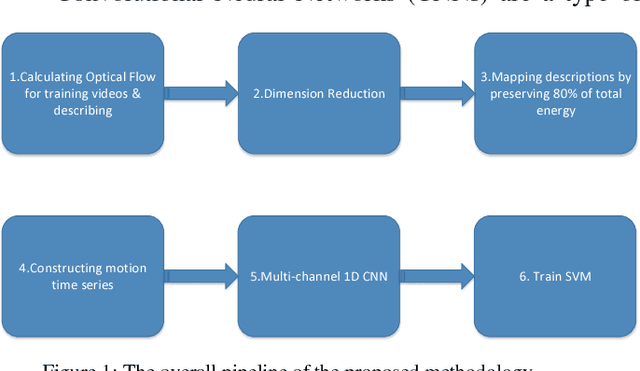
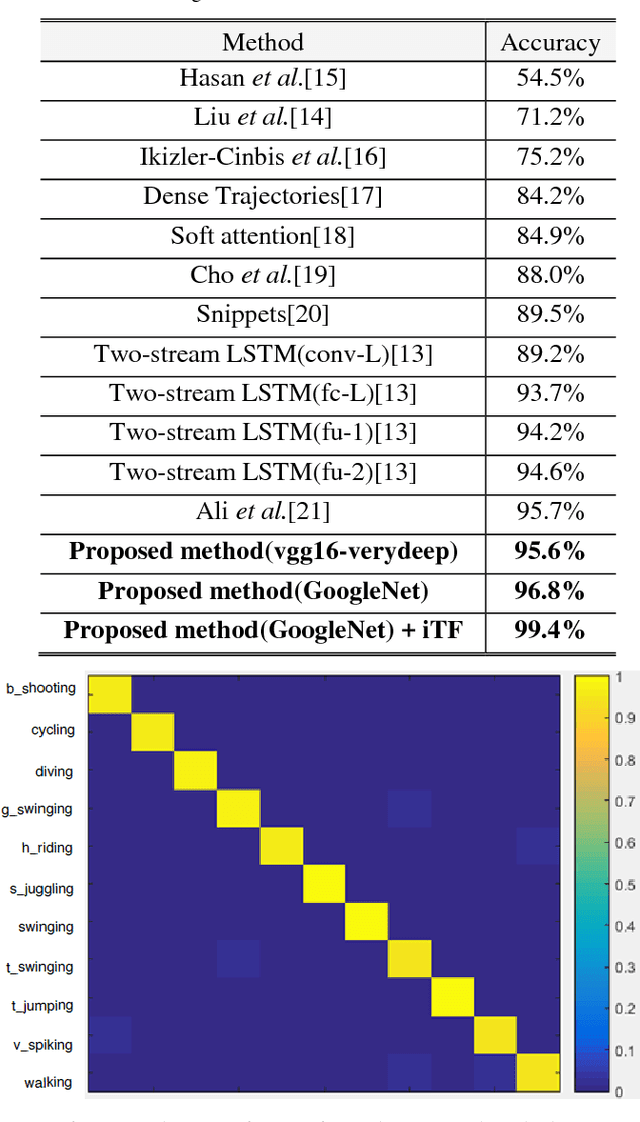
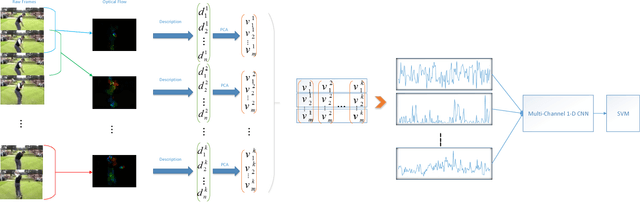

In this paper, a novel video classification methodology is presented that aims to recognize different categories of third-person videos efficiently. The idea is to keep track of motion in videos by following optical flow elements over time. To classify the resulted motion time series efficiently, the idea is letting the machine to learn temporal features along the time dimension. This is done by training a multi-channel one dimensional Convolutional Neural Network (1D-CNN). Since CNNs represent the input data hierarchically, high level features are obtained by further processing of features in lower level layers. As a result, in the case of time series, long-term temporal features are extracted from short-term ones. Besides, the superiority of the proposed method over most of the deep-learning based approaches is that we only try to learn representative temporal features along the time dimension. This reduces the number of learning parameters significantly which results in trainability of our method on even smaller datasets. It is illustrated that the proposed method could reach state-of-the-art results on two public datasets UCF11 and jHMDB with the aid of a more efficient feature vector representation.
A Correlation Based Feature Representation for First-Person Activity Recognition
Feb 09, 2018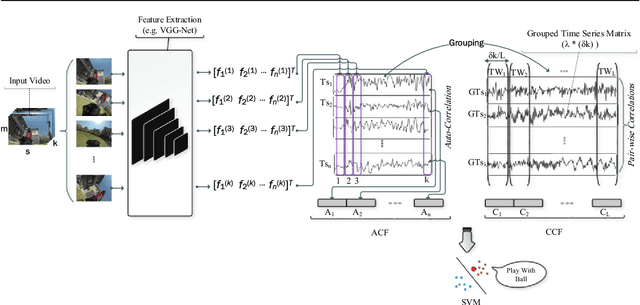
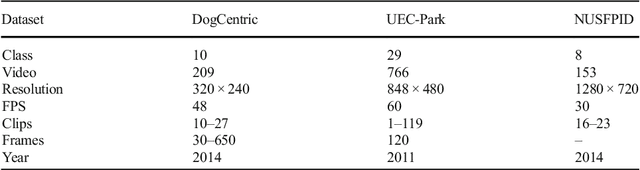
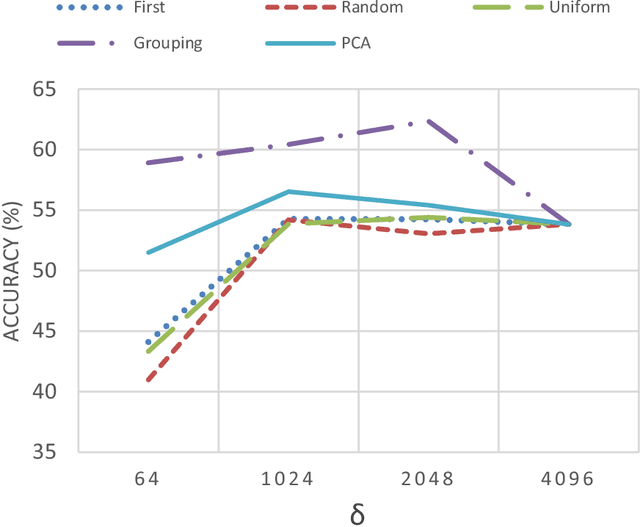

In this paper, a simple yet efficient activity recognition method for first-person video is introduced. The proposed method is appropriate for representation of high-dimensional features such as those extracted from convolutional neural networks (CNNs). The per-frame (per-segment) extracted features are considered as a set of time series, and inter and intra-time series relations are employed to represent the video descriptors. To find the inter-time relations, the series are grouped and the linear correlation between each pair of groups is calculated. The relations between them can represent the scene dynamics and local motions. The introduced grouping strategy helps to considerably reduce the computational cost. Furthermore, we split the series in temporal direction in order to preserve long term motions and better focus on each local time window. In order to extract the cyclic motion patterns, which can be considered as primary components of various activities, intra-time series correlations are exploited. The representation method results in highly discriminative features which can be linearly classified. The experiments confirm that our method outperforms the state-of-the-art methods on recognizing first-person activities on the two challenging first-person datasets.