 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe effect of scene context on weakly supervised semantic segmentation
Paper and Code
Feb 12, 2019
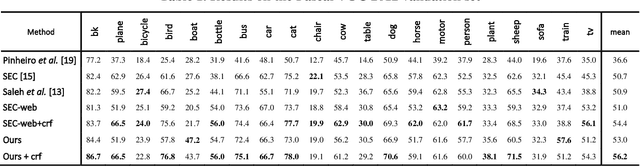
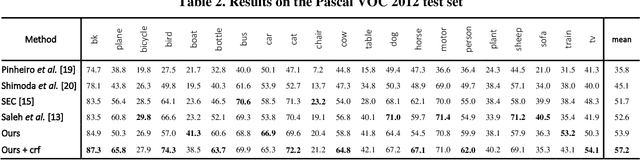

Image semantic segmentation is parsing image into several partitions in such a way that each region of which involves a semantic concept. In a weakly supervised manner, since only image-level labels are available, discriminating objects from the background is challenging, and in some cases, much more difficult. More specifically, some objects which are commonly seen in one specific scene (e.g. 'train' typically is seen on 'railroad track') are much more likely to be confused. In this paper, we propose a method to add the target-specific scenes in order to overcome the aforementioned problem. Actually, we propose a scene recommender which suggests to add some specific scene contexts to the target dataset in order to train the model more accurately. It is notable that this idea could be a complementary part of the baselines of many other methods. The experiments validate the effectiveness of the proposed method for the objects for which the scene context is added.